종합 함수 : summarise() & group_by() (예제 포함)
변수의 요약은 데이터에 대한 아이디어를 갖는데 중요하다. 단, 변수를 그룹별로 요약하면 데이터의 분포에 대한 더 나은 정보를 얻을 수 있다.
이 튜토리얼에서는 dplyr 라이브러리를 사용하여 그룹별로 데이터 세트를 요약하는 방법에 대해 알아보겠다
이 튜토리얼에서 다음에 대하여 학습한다.
- summarise()
- group_by() 함수 사용
- summarise() 내의 함수 사용
- 기본 함수
- 부분 집합
- 합
- 표준 편차
- 최소값과 최대값
- 카운트
- first()와 last()
- n번째 관측치
- 복수 그룹
- filter()
- ungroup()
이 튜토리얼을 위해 'batting' 데이터 세트를 이용할 것이다.
원 데이터 세트에는 102,816개의 관측치와 22개의 변수가 포함되어 있다. 이 데이터 세트의 20%와 다음의 변수들을 사용하겠다.
- playerID: 선수 ID 코드. (factor 타입)
- yearID: 년도. (factor 타입)
- teamID: 팀. (factor 타입)
- lgID: 리그 (factor 타입) : AA, AL, FL, NL, PL, UA
- AT : 타석. (numeric 타입)
- G : 선수별 경기 수. (numeric 타입)
- R : 득점. (numeric 타입)
- HR : 홈런 수. (numeric 타입)
- SH : 희생타수. (numeric 타입)
요약을 수행하기 전에 다음 단계를 수행하여 데이터를 준비하자.
- 1단계: 데이터 불러오기
- 2단계: 관련 변수 선택
- 3단계: 데이터 정렬
xlibrary(dplyr)# Step 1data <- read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/lahman-batting.csv") %>%# Step 2select(c(playerID, yearID, AB, teamID, lgID, G, R, HR, SH)) %>%# Step 3arrange(playerID, teamID, yearID)
데이터 세트를 불러올 때 좋은 방법은 데이터 세트의 구조를 알기 위해 glimpse() 함수를 사용하는 것이다.
x# Structure of the dataglimpse(data)
결과 :
Observations: 104,324Variables: 9$ playerID <fctr> aardsda01, aardsda01, aardsda01, aardsda01, aardsda01, a...$ yearID <int> 2015, 2008, 2007, 2006, 2012, 2013, 2009, 2010, 2004, 196...$ AB <int> 1, 1, 0, 2, 0, 0, 0, 0, 0, 603, 600, 606, 547, 516, 495, ...$ teamID <fctr> ATL, BOS, CHA, CHN, NYA, NYN, SEA, SEA, SFN, ATL, ATL, A...$ lgID <fctr> NL, AL, AL, NL, AL, NL, AL, AL, NL, NL, NL, NL, NL, NL, ...$ G <int> 33, 47, 25, 45, 1, 43, 73, 53, 11, 158, 155, 160, 147, 15...$ R <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 117, 113, 84, 100, 103, 95, 75...$ HR <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 44, 39, 29, 44, 38, 47, 34, 40...$ SH <int> 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 6, ...
smmarise()
summarise() 함수의 표현법은 기초적이며, dplyr 라이브러리의 다른 함수들과 일관성이 있다.
xsummarise(df, variable_name=condition)
인수 :
- df : 요약 통계치 계산에 사용될 데이터 세트
- variable_name=condition : 새 변수를 생성할 공식
아래의 코드를 예로 살펴 보자.
xsummarise(data, mean_run = mean(R))
코드 설명 :
- summarise(data, mean_run = mean(R)) :
data데이터 세트에서 득점을 나타내는R열의 평균인mean_run변수를 생성한다.
결과 :
xxxxxxxxxx## mean_run## 1 18.7621
얼마든지 원하는 만큼의 변수를 추가할 수 있다. 당신은 평균 출전 게임 수(G)와 평균 희생 히트 수(SH)를 반환한다.
예제 :
xsummarise(data, mean_games = mean(G), mean_SH = mean(SH, na.rm = TRUE))
코드 설명 :
- mean_SH = mean(SH, na.rm = TRUE) : 두번째 변수를 요약. SH가 결측치를 포함하고 있기 때문에
na.rm = TRUE이라고 설정.
결과 :
xxxxxxxxxx## mean_games mean_SH## 1 51.281215 2.279202
group_by() 함수 사용
group_by()를 사용하지 않는 summerise()는 큰 의미가 갖지 않는다. 그룹별로 요약 통계를 작성한다. dplyr 라이브러리는group_by() 내에 전달된 그룹에 자동적으로 함수를 적용한다.
주의 : group_by는 다른 모든 함수(즉, mutate(), filter(), arrange() 등)와 완벽하게 작동한다.
계산의 단계가 여러 단계일 때는 파이프라인(%>%) 연산자를 사용하는 것이 편리하다. 리그별(lgID)로 홈런 수(HR)의 평균을 계산할 수 있다.
xdata %>%group_by(lgID) %>%summarise(mean_run = mean(HR))
코드 설명 :
- data : 요약 통계치를 구성하는데 사용될 데이터 세트
- group_by(lgID) :
lgID변수별로 그룹하여 요약정보를 계산한다. - summarise(mean_run = mean(HR)) : 평균 홈런 수 계산
결과 :
xxxxxxxxxx### A tibble: 7 x 2## lgID mean_run## <fctr> <dbl>## 1 AA 1.01## 2 AL 3.07## 3 FL 1.15## 4 NL 2.75## 5 PL 2.15## 6 UA 0.374## 7 <NA> 0.286
파이프 연산자(%>%)는 ggplot()에도 함께 작동한다. 그래프로 요약 통계를 쉽게 표시할 수 있다. 그래프가 플롯될 때까지 모든 단계가 파이프라인 안으로 입력된다. 막대 그래프로 리그별 평균 홈런을 보는 것이 더 시각적이다. 아래의 코드는 group_by(), summary() 및 ggplot()을 함께 결합한 사용을 보여준다.
다음 단계를 수행한다.
- 1단계: 데이터 프레임 선택
- 2단계: 데이터 그룹
- 3단계: 데이터 요약
- 4단계: 요약 통계치 표시
library(ggplot2)# Step 1data %>%#Step 2group_by(lgID) %>%#Step 3summarise(mean_home_run = mean(HR)) %>%#Step 4ggplot(aes(x = lgID, y = mean_home_run, fill = lgID)) +geom_bar(stat = "identity") +theme_classic() +labs(x = "baseball league",y = "Average home run",title = paste("Example group_by() with summarise()"))
결과 :
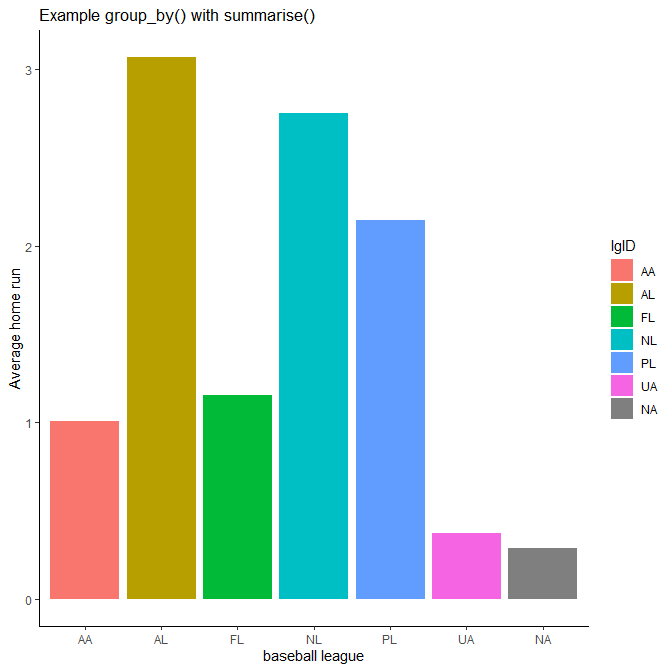
summarise() 내의 함수 사용
summary() 함수는 R의 거의 모든 함수와 호환된다. summary() 함수와 함께 사용할 수 있는 유용한 함수의 간단히 나열해 본다 :
| 목적 | 함수 | 설명 |
|---|---|---|
| Basic | mean() | 벡터 x의 평균 |
| median() | 벡터 x의 중앙값 | |
| sum() | 벡터 x의 합계 | |
| variation | sd() | 벡터 x의 표준편차 |
| IQR() | 벡터 x의 IQR(Interquartile, 사분범위) | |
| Range | min() | 벡터 x의 최소값 |
| max() | 벡터 x의 최대값 | |
| quantile() | 벡터 x의 사분위수 | |
| Position | first() | group_by() 함수를 사용하여 그룹의 첫번째 항목 표시 |
| last() | group_by() 함수를 사용하여 그룹의 마지막 항목 표시 | |
| nth() | group_by() 함수를 사용하여 그룹의 n 번째 항목 표시 | |
| Count | n() | group_by() 함수를 사용하여 그룹별 행의 갯수 카운트 |
| n_distinct() | group_by() 함수를 사용하여 그룹별 유일한 관측치의 갯수 카운트 |
위의 표에 있는 모든 함수들의 사용 예를 살펴보기로 한다.
기본 함수
이전 예에서는 요약 통계를 데이터 프레임에 저장하지 않았다.
다음 두 단계로 요약 정보를 데이터 프레임으로 작성할 수 있다.
- 1단계: 나중에 사용하기 위해 데이터 프레임에 저장
- 2단계: 데이터 세트를 이용하여 라인 플롯 작성
단계 1) 년도별 출전 경기 수(G)의 평균을 계산한다.
x## Meanex1 <- data %>%group_by(yearID) %>%summarise(mean_game_year = mean(G))head(ex1)
코드 설명 :
- 배팅 데이터 세트의 요약 통계치를 데이터 프레임 ex1에 저장한다.
결과 :
## # A tibble: 6 x 2## yearID mean_game_year## <int> <dbl>## 1 1871 20.0## 2 1872 21.1## 3 1873 28.8## 4 1874 34.1## 5 1875 28.7## 6 1876 37.9
단계 2) 요약 통계치를 라인 플롯으로 표시하고 추세를 분석한다.
x# Plot the graphggplot(ex1, aes(x = yearID, y = mean_game_year)) +geom_line() +theme_classic() +labs(x = "Year",y = "Average games played",title = paste("Average games played from 1871 to 2016"))
결과 :
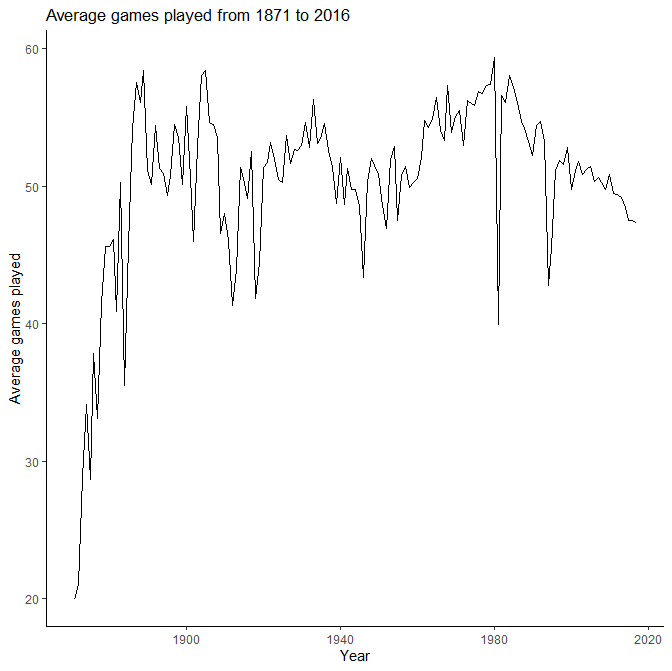
부분 집합
summarise() 함수는 부분 집합에도 적용할 수 있다.
x## Subsetting + Mediandata %>%group_by(lgID) %>%summarise(median_at_bat_league = median(AB),#Compute the median without the zeromedian_at_bat_league_no_zero = median(AB[AB > 0]))
코드 설명 :
- median_at_bat_leag_no_zero = median(AB[AB > 0]) : 변수 AB는 많은 0을 포함하고 있다. 0 값을 갖는 타석 변수(AB)와 0 값을 갖지 않는 AB 변수의 중앙값을 비교할 수 있다.
결과 :
## # A tibble: 7 x 3## lgID median_at_bat_league median_at_bat_league_no_zero## <fct> <dbl> <dbl>## 1 AA 126 128.## 2 AL 37 87## 3 FL 84.5 88## 4 NL 53 64## 5 PL 218 218## 6 UA 36 36## 7 <NA> 95 95
합
변수를 집계하는 또 다른 유용한 함수는 sum() 함수이다.
어느 리그(lgID)에서 더 많은 홈런(HR)을 쳤는지 확인할 수 있다.
x## Sumdata %>%group_by(lgID) %>%summarise(sum_homerun_league = sum(HR))
결과 :
xxxxxxxxxx## # A tibble: 7 x 2## lgID sum_homerun_league## <fct> <int>## 1 AA 1907## 2 AL 146908## 3 FL 545## 4 NL 145386## 5 PL 320## 6 UA 125## 7 <NA> 211
표준 편차
데이터에 흩어짐 정도(spread)는 표준 편차(standard deviation) 또는 R의 sd()로 계산한다.
x# Spreaddata %>%group_by(teamID) %>%summarise(sd_at_bat_league = sd(HR))
결과 :
## # A tibble: 149 x 2## teamID sd_at_bat_league## <fct> <dbl>## 1 ALT 0.323## 2 ANA 8.14## 3 ARI 7.31## 4 ATL 7.68## 5 BAL 7.47## 6 BFN 1.97## 7 BFP 1.31## 8 BL1 1.25## 9 BL2 1.49## 10 BL3 1.86## # ... with 139 more rows
각 팀의 홈런 수에는 많은 차이가 존재한다.
최소값과 최대값
min()과 max() 함수를 사용하여 벡터의 최소값과 최대값을 계산할 수 있다.
아래의 코드는 시즌 동안 선수가 출전하는 최소 경기 수와 최대 경기 수를 반환한다.
x# Min and maxdata %>%group_by(playerID) %>%summarise(min_G = min(G),max_G = max(G))
Output:
xxxxxxxxxx## # A tibble: 19,182 x 3## playerID min_G max_G## <fct> <int> <int>## 1 aardsda01 1 73## 2 aaronha01 85 161## 3 aaronto01 8 141## 4 aasedo01 7 66## 5 abadan01 1 9## 6 abadfe01 18 69## 7 abadijo01 1 11## 8 abbated01 3 154## 9 abbeybe01 1 27## 10 abbeych01 31 133## # ... with 19,172 more rows
카운트
그룹별 관측치를 세는 것은 항상 좋은 생각이다. R을 사용하면 발생 횟수를 n() 으로 집계할 수 있다.
예를 들어, 아래의 코드는 각 선수(playerID)가 출전한 년도 수(number_year)를 계산한다.
x# count observationsdata %>%group_by(playerID) %>%summarise(number_year = n()) %>%arrange(desc(number_year))
결과 :
## # A tibble: 19,182 x 2## playerID number_year## <fct> <int>## 1 mcguide01 31## 2 henderi01 29## 3 newsobo01 29## 4 johnto01 28## 5 kaatji01 28## 6 ansonca01 27## 7 baineha01 27## 8 carltst01 27## 9 moyerja01 27## 10 ryanno01 27## # ... with 19,172 more rows
first()와 last() *
그룹의 첫 번째, 마지막 또는 n번째 위치를 선택할 수 있다.
예를 들어, 각 선수(playerID)의 첫번째 데이터 항목( yearID)와 마지막 항목( yearID)를 찾을 수 있다.
x# first and lastdata %>%group_by(playerID) %>%summarise(first_appearance = first(yearID),last_appearance = last(yearID))
결과 :
xxxxxxxxxx## # A tibble: 19,182 x 3## playerID first_appearance last_appearance## <fct> <int> <int>## 1 aardsda01 2015 2004## 2 aaronha01 1966 1976## 3 aaronto01 1968 1965## 4 aasedo01 1985 1989## 5 abadan01 2003 2001## 6 abadfe01 2016 2013## 7 abadijo01 1875 1875## 8 abbated01 1903 1910## 9 abbeybe01 1895 1892## 10 abbeych01 1893 1897## # ... with 19,172 more rows
주의 : 단지 입력된 데이터 순서에 의거하여 각 선수별(playerID)로 첫번째 데이터 항목(first(yearID))과 마지막 데이터 항목(last(yearID))을 출력해 준다.
각 선수별(playerID)로 첫 출전 경기 연도(min(yearID))와 마지막 출전 경기 연도(max(yearID))를 출력하고자 한다면 다음과 같이 한다.
x
# min and maxdata %>% group_by(playerID) %>% summarise(first_appearance = min(yearID), last_appearance = max(yearID))결과 :
xxxxxxxxxx## # A tibble: 19,182 x 3## playerID first_appearance last_appearance## <fct> <int> <int>## 1 aardsda01 2004 2015## 2 aaronha01 1954 1976## 3 aaronto01 1962 1971## 4 aasedo01 1977 1990## 5 abadan01 2001 2006## 6 abadfe01 2010 2017## 7 abadijo01 1875 1875## 8 abbated01 1897 1910## 9 abbeybe01 1892 1896## 10 abbeych01 1893 1897## # ... with 19,172 more rows
n번째 관측치
nth() 함수는 first()와 last()를 보완한다. 반환할 인덱스를 가진 그룹 내의 n번째 관측치에 접근할 수 있다.
예를 들어, 당신은 한 팀이 출전한 2번째 년도만 필터링할 수 있다.
x# nthdata %>%group_by(teamID) %>%summarise(second_game = nth(yearID, 2)) %>%arrange(second_game)
Output:
xxxxxxxxxx## # A tibble: 149 x 2## teamID second_game## <fctr> <int>## 1 BS1 1871## 2 CH1 1871## 3 FW1 1871## 4 RC1 1871## 5 BR1 1872## 6 CL1 1872## 7 MID 1872## 8 TRO 1872## 9 WS3 1872## 10 WS4 1872## # ... with 139 more rows
유일한 관측치의 갯수
n() 함수는 현재 그룹의 관측치 수를 반환한다. n()에 유사한 함수는 n_distinct()이며, 유일값의 수를 계산한다.
예제 : 다음 예에서는 팀별로 선발한 선수들의 총수를 구한다.
x# distinct valuesdata %>%group_by(teamID) %>%summarise(number_player = n_distinct(playerID)) %>%arrange(desc(number_player))
코드 설명 :
- group_by(teamID) : team별 그룹
- summarise(number_player = n_distinct(playerID)) : 선수 수,
n_distinct()함수 사용에 유의. - arrange(desc(number_player)) : 선수 수의 내림차순 정렬
결과 :
## # A tibble: 149 x 2## teamID number_player## <fct> <int>## 1 CHN 2051## 2 PHI 2036## 3 SLN 1971## 4 CIN 1912## 5 PIT 1877## 6 CLE 1855## 7 BOS 1783## 8 CHA 1744## 9 DET 1658## 10 NYA 1658## # ... with 139 more rows
예제 2: 다음 예에서는 팀별로 년도 별 선발 선수들의 총수를 구한다.
x# distinct valuesdata %>%group_by(teamID, yearID) %>%summarise(number_player = n_distinct(playerID)) %>%arrange(teamID, yearID)
코드 설명 :
- group_by(teamID, yearID) : 팀별, 연도별 그룹
- summarise(number_player = n_distinct(playerID)) : 선수 수
- arrange(teamID, yearID) : 팀별, 연도별로 정렬
결과 :
xxxxxxxxxx## # A tibble: 2,865 x 3## # Groups: teamID [149]## teamID yearID number_player## <fct> <int> <int>## 1 ALT 1884 18## 2 ANA 1997 43## 3 ANA 1998 45## 4 ANA 1999 45## 5 ANA 2000 45## 6 ANA 2001 38## 7 ANA 2002 40## 8 ANA 2003 43## 9 ANA 2004 38## 10 ARI 1998 46## # ... with 2,855 more rows
복수 그룹
복수 그룹에 대하여 요약 정보를 산출한다.
예제 1 : 다음 예에서는 팀별로 년도 별 선발 선수들의 총수를 구한다.
x# Multiple Groups 1.data %>%group_by(teamID, yearID) %>%summarise(number_player = n_distinct(playerID)) %>%arrange(teamID, yearID)
코드 설명 :
- group_by(teamID, yearID) : 팀별, 연도별 그룹
- summarise(number_player = n_distinct(playerID)) : 선수 수
- arrange(teamID, yearID) : 팀별, 연도별로 정렬
결과 :
xxxxxxxxxx## # A tibble: 2,865 x 3## # Groups: teamID [149]## teamID yearID number_player## <fct> <int> <int>## 1 ALT 1884 18## 2 ANA 1997 43## 3 ANA 1998 45## 4 ANA 1999 45## 5 ANA 2000 45## 6 ANA 2001 38## 7 ANA 2002 40## 8 ANA 2003 43## 9 ANA 2004 38## 10 ARI 1998 46## # ... with 2,855 more rows
예제 2 :
x# Multiple groups 2.data %>%group_by(yearID, teamID) %>%summarise(mean_games = mean(G)) %>%arrange(desc(teamID, yearID))
코드 설명 :
- group_by(yearID, teamID) : 연도와 팀 별로 그룹
- summarise(mean_games = mean(G)) : 출전 경기 수의 평균
- arrange(desc(yearID, teamID)) : 연도별, 팀별 내림차순 정렬
결과 :
xxxxxxxxxx## # A tibble: 2,865 x 3## # Groups: yearID [147]## yearID teamID mean_games## <int> <fct> <dbl>## 1 1884 WSU 19.8## 2 1891 WS9 33.7## 3 1886 WS8 29.9## 4 1887 WS8 54.6## 5 1888 WS8 47.3## 6 1889 WS8 40.2## 7 1884 WS7 22.9## 8 1875 WS6 13.4## 9 1873 WS5 23.4## 10 1872 WS4 7.07## # ... with 2,855 more rows
filter()
작업을 수행하기 전에 데이터 세트를 필터링할 수 있다. 데이터 세트는 1871년에 시작되는데, 1980년 이전의 연도에 대해서는 분석을 필요로 하지 않는다.
x# Filterdata %>%filter(yearID > 1980) %>%group_by(yearID) %>%summarise(mean_game_year = mean(G))
코드 설명 :
- filter(yearID > 1980) : 분석할 년도(즉, 1980년 이후)만 데이터로 선택함.
- group_by(yearID) : 년도별 그룹
- summarise(mean_game_year = mean(G)) : 데이터 요약
결과 :
## # A tibble: 37 x 2## yearID mean_game_year## <int> <dbl>## 1 1981 40.0## 2 1982 56.6## 3 1983 56.1## 4 1984 58.1## 5 1985 57.2## 6 1986 56.1## 7 1987 54.7## 8 1988 54.2## 9 1989 53.3## 10 1990 52.2## # ... with 27 more rows
ungroup()
마지막으로 계산 수준을 변경하기 전에 그룹화를 해제해야 한다.
x# Ungroup the datadata %>%filter(HR > 0) %>%group_by(playerID) %>%summarise(average_HR_game = sum(HR) / sum(G)) %>%ungroup() %>%summarise(total_average_homerun = mean(average_HR_game))
코드 설명 :
- filter(HR >0) : 홈런 0개 제외
- group_by(playerID) : 선수별 그룹
- summarise(average_HR_game = sum(HR)/sum(G)) : 선수별 평균 홈런 수 계산
- ungroup() : 그룹 해제
- summarise(total_average_homerun = mean(average_HR_game)) : 데이터 요약
결과 :
xxxxxxxxxx## # A tibble: 1 x 1## total_average_homerun## <dbl>## 1 0.0624
요약
그룹별로 요약을 반환하려면 다음을 사용할 수 있다 :
# group by X1, X2, X3group(df, X1, X2, X3)
데이터의 그룹 해제는 다음과 같다.
xxxxxxxxxxungroup(df)
아래 표에는 summary() 함수에 대하여 요약하고 있다.
| 메소드 | 함수 | 코드 |
|---|---|---|
| 평균 (mean) | mean | summarise(df, mean_x1 = mean(x1)) |
| 중앙값 (median) | median | summarise(df, median_x1 = median(x1)) |
| 합 (sum) | sum | summarise(df, sum_x1 = sum(x1)) |
| 표준 편차 (standard deviation) | sd | summarise(df, sd_x1 = sd(x1)) |
| 사분 범위 (interquartile) | IQR | summarise(df, interquartile_x1 = IQR(x1)) |
| 최소값 (minimum) | min | summarise(df, minimum_x1 = min(x1)) |
| 최대값 (maximum) | max | summarise(df, maximum_x1 = max(x1)) |
| 사분위수 (quantile) | quantile | summarise(df, quantile_x1 = quantile(x1)) |
| 첫번째 관측치 (first observation) | first | summarise(df, first_x1 = first(x1)) |
| 마지막 관측치 (last observation) | last | summarise(df, last_x1 = last(x1)) |
| n 번째 관측치 (nth observation) | nth | summarise(df, nth_x1 = nth(x1, 2)) |
| 발생 횟수 (number of occurrence) | n | summarise(df, n_x1 = n(x1)) |
| 유일값 발생 횟수 (number of distinct occurrence) | n_distinct | summarise(df, n_distinct _x1 = n_distinct(x1)) |