데이터 프레임: 생성, 추가, 선택, 부분집합
데이터 프레임
데이터 프레임(data frame)은 같은 길이를 갖는 벡터의 리스트이다. 행렬은 한 가지 타입의 데이터만을 포함하지만, 데이터 프레임은 디양한 데이터 타입(숫자 벡터, 문자 벡터, factor 등)을 받아 들인다.
이 튜토리얼에서는 다음에 대하여 학습한다:
데이터 프레임 생성
우리는 변수 a, b, c, d를 data.frame() 함수에 투입하여 데이터 프레임을 생성할 수 있다. 우리는 name() 함수를 이용하여 열에 이름을 붙일 수 있고, 단순히변수들의 이름을 지정할 수도 있다.
xxxxxxxxxxdata.frame(df, stringsAsFactors = TRUE)
인수(Arguments):
- df: 데이터 프레임으로 변환될 행렬 또는 결합될 변수의 집합일 수 있다.
- stringsAsFactors: 문자열(string)을 factor를 변환 (기본 값 = TRUE)
우리는 같은 길이를 갖는 4개의 변수를 결합하여 첫 데이터 세트를 생성할 수 있다.
예제 1:
x# Create a, b, c, d variablesa <- c(10,20,30,40)b <- c('book', 'pen', 'textbook', 'pencil_case')c <- c(TRUE,FALSE,TRUE,FALSE)d <- c(2.5, 8, 10, 7)# Join the variables to create a data framedf <- data.frame(a,b,c,d)df
결과 :
xxxxxxxxxx## a b c d## 1 1 book TRUE 2.5## 2 2 pen TRUE 8.0## 3 3 textbook TRUE 10.0## 4 4 pencil_case FALSE 7.0
데이터 프레임의 열에 제목 달기
여기서 우리는 열 제목(column heading)이 변수의 이름과 같은 것을 알 수 있다. names() 함수를 이용하여 열의 이름을 변경할 수 있다. 다음의 예를 확인해 보자.
예제 1:
x# Name the data framenames(df) <- c('ID', 'items', 'store', 'price')df
결과 :
xxxxxxxxxx## ID items store price## 1 10 book TRUE 2.5## 2 20 pen FALSE 8.0## 3 30 textbook TRUE 10.0## 4 40 pencil_case FALSE 7.0# Print the structure
데이터 프레임의 구조 학인
데이터 프레임 변수의 구조를 확인하기 위해 str( )를 이용한다.
예제 1:
xxxxxxxxxxstr(df)
결과 :
xxxxxxxxxx## 'data.frame': 4 obs. of 4 variables:## $ ID : num 10 20 30 40## $ items: Factor w/ 4 levels "book","pen","pencil_case",..: 1 2 4 3## $ store: logi TRUE FALSE TRUE FALSE## $ price: num 2.5 8 10 7
기본적으로 데이터 프레임은 문자열 변수를 factor로 반환한다.
데이터 프레임의 분할
데이터 프레임의 값들을 분할할 수 있다. 데이터 프레임의 이름 다음에 대괄호 안에 행과 열을 선택할 수 있다.
데이터 프레임 df[A, B]는 행과 열로 구성된다. A는 행을 B는 열을 나타낸다. 우리는 데이터 프레임을 행 그리고/또는 열을 지정해서 분할할 수 있다.
아래의 그램에서 왼쪽 부분은 행(rows)을 나타내고, 오른쪽 부분은 열(column)을 나타낸다. 여기서 :기호는 '까지'(to)를 의미한다. 예를 들어 1:3은 1부터 3까지의 값을 선택하는 것을 나타낸다.
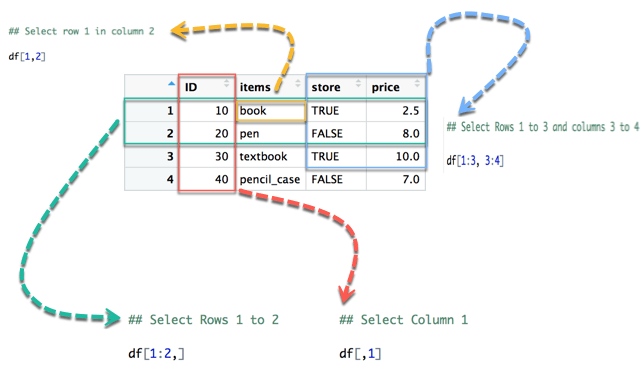
아래의 그림에서 우리는 데이터 프레임의 다양한 선택을 어떻게 접근하는지 보여준다:
df[1,2]: 노란색 화살표는 2열에 있는 1행을 선택한다.df[1:2, ]: 초록색 화살표는 1에서 2행까지를 선택한다.df[, 1]: 빨간색 화살표는 1열을 선택한다.df[1:3, 3:4]: 파란색 화살표는 1행에서 3행까지 그리고 3열에서 4열까지를 선택한다.
만일 왼쪽 부분을 빈칸으로 하면 R은 모든 행을 선택할 것이다. 비슷하게, 오른쪽 부분을 빈칸으로 하면, R은 모든 열을 선택할 것이다.
우리는 console에서 코드를 실행할 수 있다.
예제 1:
x# Select row 1 in column 2df[1,2]
결과:
xxxxxxxxxx## [1] book## Levels: book pen pencil_case textbook
예제 2 :
x# Select Rows 1 to 2df[1:2,]
결과:
xxxxxxxxxx## ID items store price## 1 10 book TRUE 2.5## 2 20 pen FALSE 8.0
예제 3 :
x# Select Columns 1df[,1]
결과:
xxxxxxxxxx## [1] 10 20 30 40
예제 4 :
x# Select Rows 1 to 3 and columns 3 to 4df[1:3, 3:4]
결과 :
xxxxxxxxxx## store price## 1 TRUE 2.5## 2 FALSE 8.0## 3 TRUE 10.0
또한 열의 이름을 이용해서 열을 선택할 수도 있다. 예를 들어, 아래의 코드는 ID와 store라는 두 개의 열을 추출한다.
예제 5:
xxxxxxxxxx# Slice with columns namedf[, c('ID', 'store')]
결과 :
xxxxxxxxxx## ID store## 1 10 TRUE## 2 20 FALSE## 3 30 TRUE## 4 40 FALSE
데이터 프레임에 열 추가하기
데이터 프레임에 열을 추가할 수 있다. $ 기호를 이용하여 새로운 변수를 추가할 수 있다.
예제 1:
x# Create a new vectorquantity <- c(10, 35, 40, 5)# Add `quantity` to the `df` data framedf$quantity <- quantitydf
결과 :
xxxxxxxxxx## ID items store price quantity## 1 10 book TRUE 2.5 10## 2 20 pen FALSE 8.0 35## 3 30 textbook TRUE 10.0 40## 4 40 pencil_case FALSE 7.0 5
주의 : 벡터에 있는 요소의 갯수는 데이터 프레임에 있는 요소의 갯수와 같아야 한다. 다음의 구문을 실행해보자.
xxxxxxxxxxquantity <- c(10, 35, 40)# Add `quantity` to the `df` data framedf$quantity <- quantity
에러 출력 :
xxxxxxxxxxError in `$<-.data.frame`(`*tmp*`, quantity, value = c(10, 35, 40))replacement has 3 rows, data has 4
cbind()를 이용하여 데이터 프레임에 열과 행을 추가할 수도 있다.
x# Create a, b, c, d variablesa <- c(10,20,30,40)b <- c('book', 'pen', 'textbook', 'pencil_case')c <- c(TRUE,FALSE,TRUE,FALSE)d <- c(2.5, 8, 10, 7)# Join the variables to create a data framedf <- data.frame(a,b,c,d)dfe <- c(10, 35, 40, 5)df <- cbind(df, e) # 열 e 추가하기결과 :
xxxxxxxxxx> df## a b c d## 1 10 book TRUE 2.5## 2 20 pen FALSE 8.0## 3 30 textbook TRUE 10.0## 4 40 pencil_case FALSE 7.0>> e <- c(10, 35, 40, 5)> df <- cbind(df, e) # 열 e 추가하기> df## a b c d e## 1 10 book TRUE 2.5 10## 2 20 pen FALSE 8.0 35## 3 30 textbook TRUE 10.0 40## 4 40 pencil_case FALSE 7.0 5
데이터 프레임의 열 선택
때때로 우리는 나중 사용을 위해 데이터 열을 저장하거나 열 단위의 연산을 수행할 필요가 있다. 이때 우리는 데이터 프레임의 열을 선택하기 위해 $ 기호를 사용할 수 있다.
예제 1:
xxxxxxxxxx# Select the column IDdf$ID
결과 :
xxxxxxxxxx## [1] 1 2 3 4
데이터 프레임의 부분집합
앞의 절에서 우리는 조건없이 전체 열을 선택하였다. 특정 조건이 true 인지에 따라 부분집합(subset)을 만들 수 있다.
subset() 함수를 사용한다.
xxxxxxxxxxsubset(x, condition)
인수(arguments) :
- x : 부분집합 수행에 사용될 데이터 프레임
- condition : 조건문을 정의
예제 1: price가 5보다 큰(price > 5) 항목들만 출력하고 싶다면 다음과 같이 할 수 있다.
xxxxxxxxxx# Select price above 5subset(df, subset = price > 5)
결과 :
xxxxxxxxxxID items store price2 20 pen FALSE 83 30 textbook TRUE 104 40 pencil_case FALSE 7