dplyr : 자료 결합 & 클린징
데이터 분석 서론
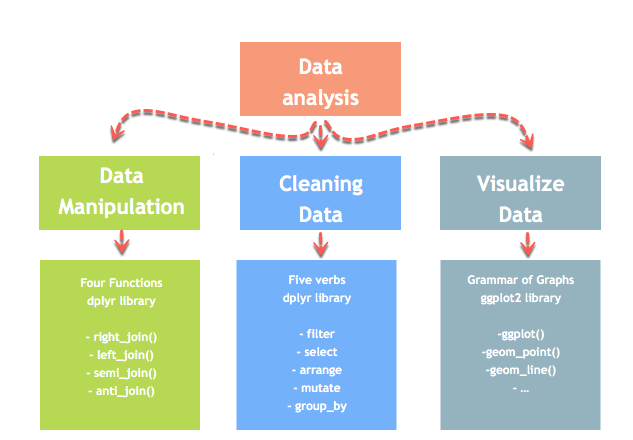
데이터 분석은 세 부분으로 나눌 수 있다.
- 추출: 첫째, 우리는 많은 원천으로부터 데이터를 수집하고 그것들을 결합해야 한다.
- 변환: 이 단계는 데이터 조작을 포함한다. 일단 우리가 모든 데이터 소스를 통합하고 나면, 우리는 그 데이터를 정제할 수 있다.
- 시각화: 마지막 조치는 불규칙성을 확인하기 위해 데이터를 시각화하는 것이다.
데이터 과학자가 직면한 가장 중요한 문제 중 하나는 데이터 조작이다. 데이터는 결코 원하는 형식으로 이용가능하지 않다. 데이터 과학자는 적어도 절반의 시간을 할애하여 데이터를 클린징과 조작하는데 시간을 투입해야 한다. 그것은 작업에서 가장 중요한 과제 중 하나이다. 데이터 조작 프로세스가 완전하지 않고 정밀하며 엄격하지 않으면 모델이 정확하게 수행되지 않을 것이다.
R에는 데이터 변환을 돕는 dplyr이라는 라이브러리가 있다.
dplyr 라이브러리는 데이터를 조작하기 위한 네 가지 함수와 데이터를 클린징하기 위한 다섯 개의 동사를 중심으로 근본적으로 만들어졌다. 그 후에 ggplot 라이브러리를 사용하여 데이터를 분석하고 시각화할 수 있다.
이 튜토리얼에서는 dplyr 라이브러리를 사용하여 데이터 프레임을 조작하는 방법에 대하여 학습할 것이다.
이 튜토리얼에서는 다음에 대하여 학습한다:
- 데이터 분석
dplyr을 이용한 결합- left_join()
- right_join()
- inner_join()
- full_join()
- 복수 키
- 데이터 클린징 함수
- gather()
- spread()
- separate()
- unite()
dplyr을 이용한 결합
dplyr은 데이터 세트를 잘 그리고 편리하게 결합할 수 방법을 제공해 준다.
우리는 많은 입력 데이터를 원천을 가지고 있을 수 있으며, 어느 시점에서는 그것들을 결합할 필요가 있다. dplyr을 이용한 결합은 원래 데이터 세트의 오른쪽에 변수를 추가한다. dplyr은 SQL과 비슷한 네 종류의 결합을 다루는 것이다.
- Left_join()
- right_join()
- inner_join()
- full_join()
우리는 쉬운 예를 이용하여 모든 join 유형을 학습할 것이다.
우선 두 개의 데이터 세트를 만든다. Table 1은 ID와 y의 두 변수를 포함하고, Table 2는 ID와 z를 수집한다. 각각의 경우에 키-쌍 변수가 필요하다. 우리의 경우, ID는 key 변수이다. 그 기능은 두 Table에서 동일한 값을 찾고 반환 값을 Table 1의 오른쪽에 결합한다.
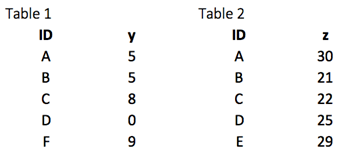
xxxxxxxxxxlibrary(dplyr)df_primary <- tribble(~ID, ~y,"A", 5,"B", 5,"C", 8,"D", 0,"F", 9)df_secondary <- tribble(~ID, ~y,"A", 30,"B", 21,"C", 22,"D", 25,"E", 29)
left_join()
두 데이터 세트를 병합하는 가장 일반적인 방법은 left_join() 함수를 사용하는 것이다. 아래 그림에서 키-쌍이 두 데이터 세트의 A, B, C 및 D 행과 완벽하게 일치한다는 것을 알 수 있다. 그러나 E와 F 행은 남겨져 있다. 이 두 가지 관찰 데이터는 어떻게 처리할까? left_join()으로 모든 변수를 원래 표에 보관하고 대상 표에 키-쌍이 없는 변수는 고려하지 않는다. 우리의 예에서 변수 E는 Table 1에 존재하지 않는다. 따라서, 그 줄은 삭제될 것이다. 변수 F는 원래 Table에서 나온다. 그것은 left_join() 뒤에 보관되며, z열에 NA를 반환한다. 아래 그림은 left_join()으로 일어날 일을 재현한다.
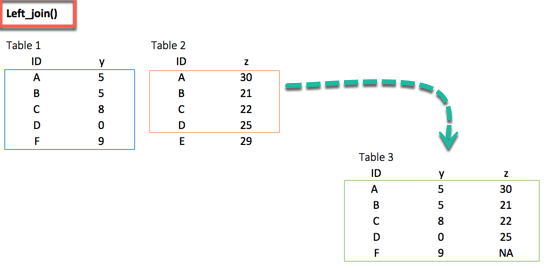
xxxxxxxxxxleft_join(df_primary, df_secondary, by ='ID')
결과 :
xxxxxxxxxx### A tibble: 5 x 3## ID y.x y.y## <chr> <dbl> <dbl>## 1 A 5 30## 2 B 5 21## 3 C 8 22## 4 D 0 25## 5 F 9 NA
right_join()
right_join() 함수는left_join()처럼 똑같이 작동한다. 유일한 차이점은 사라지는 행이다. 대상 데이터 프레임에서 사용할 수 있는 값 E는 새 Table에 존재하며, y열에 대한 값은 NA를 취한다.
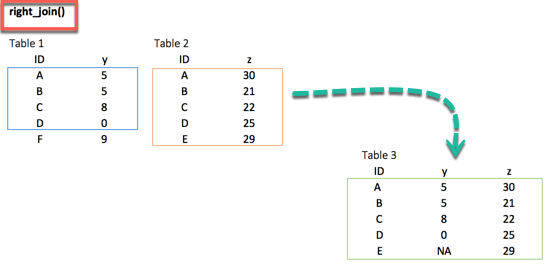
xxxxxxxxxxright_join(df_primary, df_secondary, by = 'ID')
결과 :
xxxxxxxxxx### A tibble: 5 x 3## ID y.x y.y## <chr> <dbl> <dbl>## 1 A 5 30## 2 B 5 21## 3 C 8 22## 4 D 0 25## 5 E NA 29
inner_join()
두 데이터 세트가 일치하지 않을 것이라고 100% 확신할 때, 양쪽 데이터 세트에 존재하는 행 만을 반환하는 것을 고려할 수 있다. 이는 깨끗한 데이터 세트가 필요하거나 또는 평균(mean)이나 중위수(median)로 결측치(missing value)을 부여하고 싶지 않을 때 가능하다.
inner_join()이 도움이 된다. 이 함수는 대응이 되지 않는 행들은 제외한다.
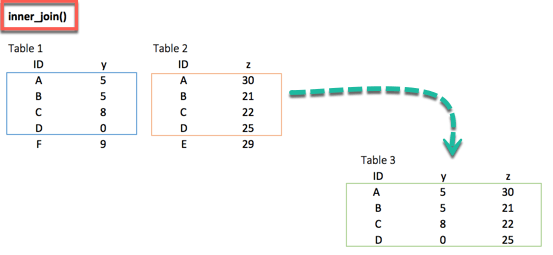
xxxxxxxxxxinner_join(df_primary, df_secondary, by ='ID')
결과 :
xxxxxxxxxx### A tibble: 4 x 3## ID y.x y.y## <chr> <dbl> <dbl>## 1 A 5 30## 2 B 5 21## 3 C 8 22## 4 D 0 25
full_join()
마지막으로 full_join() 함수는모든 관찰치들을 유지하고 결측치는 NA 값으로 대체한다.
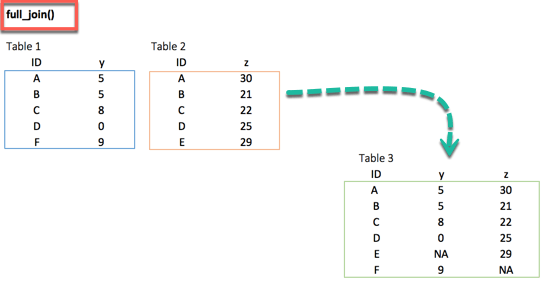
xxxxxxxxxxfull_join(df_primary, df_secondary, by = 'ID')
결과 :
xxxxxxxxxx## # A tibble: 6 x 3## ID y.x y.y## <chr> <dbl> <dbl>## 1 A 5 30## 2 B 5 21## 3 C 8 22## 4 D 0 25## 5 F 9 NA## 6 E NA 29
복수 키 쌍
마지막으로 중요한 것은 데이터 세트에 복수 개의 키가 있을 수 있다는 점이다. 고객이 구매한 제품 items 또는 year가 있는 다음의 데이터 세트를 고려해보자.

만약 우리가 두 테이블을 합치려 하면, R은 오류를 일으킨다. 이러한 상황을 해결하기 위해 우리는 두 개의 키-쌍 변수를 이용할 수 있다. 즉, 두 데이터 세트에 모두 나타나는 ID와 year을 이용하여 Table 1과 Table 2를 병합할 수 있다.
xxxxxxxxxxdf_primary <- tribble(~ID, ~year, ~items,"A", 2015,3,"A", 2016,7,"A", 2017,6,"B", 2015,4,"B", 2016,8,"B", 2017,7,"C", 2015,4,"C", 2016,6,"C", 2017,6)df_secondary <- tribble(~ID, ~year, ~prices,"A", 2015,9,"A", 2016,8,"A", 2017,12,"B", 2015,13,"B", 2016,14,"B", 2017,6,"C", 2015,15,"C", 2016,15,"C", 2017,13)left_join(df_primary, df_secondary, by = c('ID', 'year'))
결과 :
xxxxxxxxxx## # A tibble: 9 x 4## ID year items prices## <chr> <dbl> <dbl> <dbl>## 1 A 2015 3 9## 2 A 2016 7 8## 3 A 2017 6 12## 4 B 2015 4 13## 5 B 2016 8 14## 6 B 2017 7 6## 7 C 2015 4 15## 8 C 2016 6 15## 9 C 2017 6 13
데이터 클린징 함수
다음은 데이터를 정리하는 4가지 중요한 함수들이다.
gather(): 넓은 형태(wide format)의 데이터를 긴 형태(long format)의 데이터로 변환spread(): 긴 형태의 데이터를 넓은 형태의 데이터로 변환separate(): 하나의 변수를 두개로 나누다.unite(): 두개의 변수를 하나로 묶음
우리는 tidy 라이브러리를 사용한다. 이 라이브러리는 자료를 조작, 청소, 그리고 시각화하기 위한 라이브러리에 포함된다. 아나콘다와 함께 R을 설치하면, 이 라이브러리는 이미 설치되어 있다. 우리는 https://anaconda.org/r/r-tidyr 에서 이 라이브러리를 찾을 수 있다.
아직 설치가 되어있지 않다면, 다음의 명령어로 tidyr 라이브러리를 설치할 수 있다.
xxxxxxxxxxinstall tidyr; install.packages("tidyr")
gather()
gather() 함수의 목적은 넓은 데이터를 긴 데이터로 변환하는 것이다.
xxxxxxxxxxgather(data, key, value, na.rm = FALSE)Arguments:-data: The data frame used to reshape the dataset-key: Name of the new column created-value: Select the columns used to fill the key column-na.rm: Remove missing values. FALSE by default
아래에서, 우리는 넓은 형태에서 긴 형태로 변환하는 개념을 시각화할 수 있다.
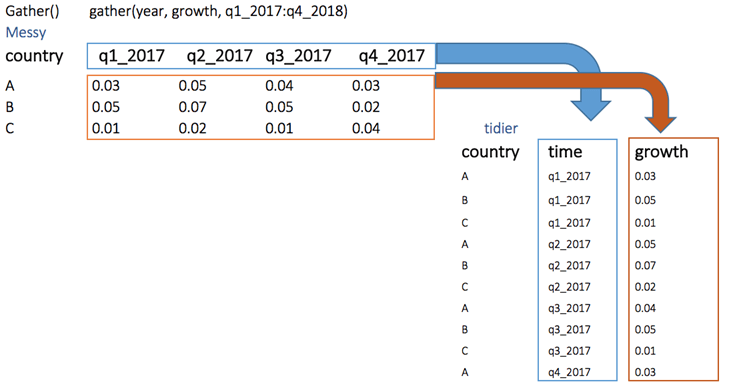
예제 : 넓은 형태의 데이터 프레임 생성
Messy 라는 데이터 프레임 변수에 country, q1_2017, q2_2017, q3_2017, q4_2017의 열을 만들고 다음과 같이 데이터를 입력하자. 그리면 이 Messy는 넓은 형태의 데이터 프레임이 된다.
xxxxxxxxxxlibrary(tidyr)# Create a messy datasetmessy <- data.frame(country = c("A", "B", "C"),q1_2017 = c(0.03, 0.05, 0.01),q2_2017 = c(0.05, 0.07, 0.02),q3_2017 = c(0.04, 0.05, 0.01),q4_2017 = c(0.03, 0.02, 0.04))messy
결과 :**
xxxxxxxxxx## country q1_2017 q2_2017 q3_2017 q4_2017## 1 A 0.03 0.05 0.04 0.03## 2 B 0.05 0.07 0.05 0.02## 3 C 0.01 0.02 0.01 0.04
예제 : 긴 형태의 데이터로 변환
이제 이 Messy 변수를 긴 형태의 tidier 변수로 변환해 보자.
그러기 위해 tidier 변수에는 기존의 country 열은 그대로 사용하고, q1_2017:q4_2017을 값으로 하는 quarter (또는 year 또는 time) 열을 생성하고, 성장률 수치를 값으로 하는 growth열을 생성하면 된다.
xxxxxxxxxx# Reshape the datatidier <-messy %>%gather(quarter, growth, q1_2017:q4_2017) # q1_2017:q4_2017이 growth 열의 값이 되고, # growth에는 해당 수치 값들이 순서대로 입력된다.tidier결과 :
xxxxxxxxxx## country quarter growth## 1 A q1_2017 0.03## 2 B q1_2017 0.05## 3 C q1_2017 0.01## 4 A q2_2017 0.05## 5 B q2_2017 0.07## 6 C q2_2017 0.02## 7 A q3_2017 0.04## 8 B q3_2017 0.05## 9 C q3_2017 0.01## 10 A q4_2017 0.03## 11 B q4_2017 0.02## 12 C q4_2017 0.04
gather() 함수에서 우리는 quarter와 growth라는 두개의 변수를 새로 생성하였는데, 이는 우리의 데이터 세트가 하나의 그룹 변수, 즉 country와 키-값 쌍(예, A, q1_2017=0.03; B, q1_2017=0.05; C, q1_2017=0.01 ...) 을 가지고 있기 때문이다.
spread()
spread() 함수는 gather() 함수와 반대로 작용한다..
xxxxxxxxxxspread(data, key, value)arguments:data: The data frame used to reshape the dataset key: Column to reshape long to widevalue: Rows used to fill the new column
예제 : 긴 형태의 데이터를 넓은 형태의 데이터로 변환
이제 tidier 데이터 세트를 spread() 함수를 이용하여 messy로 변환할 수 있다.
xxxxxxxxxx# Reshape the datamessy_1 <- tidier %>%spread(quarter, growth)messy_1
결과 :
xxxxxxxxxx## country q1_2017 q2_2017 q3_2017 q4_2017## 1 A 0.03 0.05 0.04 0.03## 2 B 0.05 0.07 0.05 0.02## 3 C 0.01 0.02 0.01 0.04
separate()
separate() 함수는 구분자에 따라 한 개의 열을 두 개로 나눈다. 이 함수는 변수가 날짜(date) 형태인 경우에 유용하다. 우리의 분석은 '분기'와 '연도'에 초점을 맞추고, 그 열을 두 개의 새로운 변수로 분리해 보기로 한다.
Syntax:
xxxxxxxxxxseparate(data, col, into, sep= "", remove = TRUE)
인수 (arguments) :
- data : 데이터 세트의 모양을 변환하는데 사용되는 데이터 프레임
- col : 분리할 열
- into : 새로운 변수들의 이름
- sep : 변수를 분리하는데 사용되는 기호. 예:
-,_,& - remove : 이전의 열 제거 여부. 기본 값은
TRUE
우리는 separate() 함수를 적용하여 더 깔끔한 데이터 세트에 해당 분기를 년도와 분리할 수 있다.
xxxxxxxxxxseparate_tidier <-tidier %>%separate(quarter, c("Qrt", "year"), sep ="_")head(separate_tidier)
결과 :
xxxxxxxxxx## country Qrt year growth## 1 A q1 2017 0.03## 2 B q1 2017 0.05## 3 C q1 2017 0.01## 4 A q2 2017 0.05## 5 B q2 2017 0.07## 6 C q2 2017 0.02
unite()
unite() 함수는 두 개의 열을 하나로 결합한다.
Syntax:
xxxxxxxxxxunit(data, col, conc ,sep= "", remove = TRUE)
인수(arguments) :
- data : 데이터 세트의 ㅙ느모양을 바꾸는데 사용되는 데이터 프레임
- col : 새로운 열의 이름
- conc : 결합되는 열의 이름
- sep : 변수를 결합하는데 사용되는 기호, 예:
-,_,& - remove : 이전 열의 제거 여부. 기본 값은
TRUE
위의 예에서, 우리는 quarter와 year를 분리했다. 만약 우리가 그것들을 병합하고 싶다면, 다음 코드를 사용한다.
xxxxxxxxxxunit_tidier <- separate_tidier %>%unite(Quarter, Qrt, year, sep ="_")head(unit_tidier)
결과 :
xxxxxxxxxx## country Quarter growth## 1 A q1_2017 0.03## 2 B q1_2017 0.05## 3 C q1_2017 0.01## 4 A q2_2017 0.05## 5 B q2_2017 0.07## 6 C q2_2017 0.02
요약
다음은 두 개의 데이터 세트를 결합하는데 dplyr에서 사용되는 중요한 4개의 함수들이다.
| 함수 | 목적 | 인수 | 복수 키 |
|---|---|---|---|
| left_join() | 두 개의 데이터 세트를 결합한다. 왼쪽 테이블의 모든 값들을 유지한다. | data, origin, destination, by = "ID" | origin, destination, by = c("ID", "ID2") |
| right_join() | 두 개의 데이터 세트를 결합한다. 오른쪽 테이블의 모든 값들을 유지한다. | data, origin, destination, by = "ID" | origin, destination, by = c("ID", "ID2") |
| inner_join() | 두 개의 데이터 세트를 결합한다. 대응되지 않는 모든 행은 제거한다. | data, origin, destination, by = "ID" | origin, destination, by = c("ID", "ID2") |
| full_join() | 두 개의 데이터 세트를 결합한다. 모든 행들을 유지한다. | data, origin, destination, by = "ID" | origin, destination, by = c("ID", "ID2") |
tiyr 라이브러를 사용하면 gather(), spread(), separate() 그리고 unite() 등의 함수로 데이터 세트를 변환할 수 있다.
| 함수 | 목적 | 인수 |
|---|---|---|
| gather() | 넓은 데이터를 긴 데이터로 변환 | (data, key, value, na.rm = FALSE) |
| spread() | 긴 데이터를 넓은 데이터로 변환 | (data, key, value) |
| separate() | 하나의 변수를 두 개로 분리 | (data, col, into, sep= "", remove = TRUE) |
| unite() | 두 개의 변수를 하나로 통합 | (data, col, conc ,sep= "", remove = TRUE) |