함수 (예제 포함)
함수
프로그래밍 환경에서 함수(function)는 명령어의 집합이다. 프로그래머는 같은 일의 반복을 피하거나 또는 복잡성을 줄이기 위해 함수를 만든다.
함수는
- 특정의 작업을 수행하기 위해 작성되고
- 인수(arguments)를 포함할 수도 포함하지 않을 수도 있고
- 본체(body)를 포함하고
- 하나 이상의 값을 반환할 수 있거나 하지 않을 수도
있어야 한다.
함수 작성의 일반적인 접근방식은 inputs으로서 인수 부분을 사용하고, body 부분에 품을 전달하고, 최종적으로 output을 반환하는 것이다. 함수의 구문은 다음과 같다 :
xxxxxxxxxxfunction (arglist) {#Function body}
이 튜토리얼에서는 다음을 학습한다 :
주요 내장 함수
R에는 많은 함수들이 내장되어 있다. R은 값이나 위치로 함수의 인수를 입력 매개변수와 대응시킨 다음 함수의 본문(body)을 실행한다. 함수의 인수들은 기본값을 가질 수 있다. 이러한 인수를 값을 지정하지 않으면 R은 이 기본값을 취하게 된다.
주의 : 콘솔에서 함수 자체의 이름을 실행하여 함수의 소스 코드를 볼 수 있다.

우리는 다음과 같은 세 가지 부류의 함수에 대하여 살펴 볼 것이다.
- 일반 함수(General function)
- 수학 함수(Maths function)
- 통계 함수(Statistical function)
일반 함수
우리는 이미 cbind(), rbind(), range(), sort(), order() 등의 일반적인 함수에 익숙하다. 이 함수들은 각각 특정한 과업을 수행하여, 인수를 취하여 출력을 반환한다. 다음은 누구나 알아야 할 중요한 함수들이다:
diff() 함수
만약 당신이 시계열 분석(time series)을 한다면, 너는 그들의lag values고 하여 시리즈 stationary 필요가 있다. Astationary process 시간에 대해 끊임없이 나쁜 차액과 자기 상관을 허용한다. 이것은 주로 시간 시리즈의 예측을 향상시킨다. 쉽게 기능 diff() 할 수 있다. 우리는 추세를 섞고 이 기능을 사용하는 대로 time-series 데이터를 시리즈 stationary에 diff()을 지을 수 있다. 그 diff()기능 및 반환 적합하고 차이iterated은 뒤처져 하나의 논쟁, 벡터를 받아들입니다.
참고: 우리는 종종 무작위 데이터를 만들어야 하지만, 학습과 비교를 위해 우리는 기계 간에 숫자가 동일하기를 원한다. 우리 모두가 동일한 데이터를 생성하도록 하기 위해, 우리는 임의의 값이 123인 set.seed() 함수를 사용한다. set.seed() 함수는 모든 현대 컴퓨터가 동일한 수의 시퀀스를 갖도록 하는 의사 난수 생성기의 과정을 통해 생성된다. set.seed() 함수를 사용하지 않으면, 우리는 모두 다른 숫자의 순서를 갖게 될 것이다.
xxxxxxxxxxset.seed(123)## Create the datax = rnorm(1000)ts <- cumsum(x)## Stationary the seriediff_ts <- diff(ts)par(mfrow=c(1,2))## Plot the seriesplot(ts, type='l')plot(diff(ts), type='l')

length() function
많은 경우에, 우리는 계산을 위해 또는 for 반복구문에 사용하기 위해 벡터의 길이(length)를 알고 싶을 때가 있다. length() 함수는 벡터 x의 행의 수를 카운트한다. 다음의 코드는 cars 데이터 세트를 가져와서 행의 수를 반환한다.
주의 : length()는 벡터의 요소 수를 반환한다. 함수가 행렬이나 데이터 프레임으로 전달되면 열의 수가 반환된다.
xxxxxxxxxxdt <- cars## number columnslength(dt)
결과 :
xxxxxxxxxx## [1] 1## number rowslength(dt[,1])
결과 :
xxxxxxxxxx## [1] 50
수학 함수
R은 많은 수학함수를 보유하고 있다.
| Operator | 설명 |
|---|---|
| abs(x) | x의 절대값 |
| log(x,base=y) | 밑을 y로 하는 x의 로그; 만일 밑을 지정하지 않으면 자연로그를 반환한다. |
| exp(x) | e의 x제곱 반환 |
| sqrt(x) | x의 제곱근 반환 |
| factorial(x) | x 팩토리얼을 반환 |
예제 :
xxxxxxxxxx# sequence of number from 44 to 55 both including incremented by 1x_vector <- seq(45,55, by = 1)#logarithmlog(x_vector)
결과 :
xxxxxxxxxx## [1] 3.806662 3.828641 3.850148 3.871201 3.891820 3.912023 3.931826## [8] 3.951244 3.970292 3.988984 4.007333
예제 :
xxxxxxxxxx#exponentialexp(x_vector)결과 :
xxxxxxxxxx## [1] 3.493427e+19 9.496119e+19 2.581313e+20 7.016736e+20 1.907347e+21## [6] 5.184706e+21 1.409349e+22 3.831008e+22 1.041376e+23 2.830753e+23## [11] 7.694785e+23
예제 :
xxxxxxxxxx#squared rootsqrt(x_vector)Output:
xxxxxxxxxx## [1] 6.708204 6.782330 6.855655 6.928203 7.000000 7.071068 7.141428## [8] 7.211103 7.280110 7.348469 7.416198
예제 : 팩토리얼
xxxxxxxxxx#factorialfactorial(x_vector)결과 :
xxxxxxxxxx## [1] 1.196222e+56 5.502622e+57 2.586232e+59 1.241392e+61 6.082819e+62## [6] 3.041409e+64 1.551119e+66 8.065818e+67 4.274883e+69 2.308437e+71## [11] 1.269640e+73
통계 함수
R 표준 설치는 광범위한 통계 함수들을 포함한다. 이 튜토리얼에서는 가장 중요한 함수들에 대해 간략히 살펴보기로 한다.
기본 통계 함수
| 함수 | 설명 |
|---|---|
| mean(x) | x의 평균 |
| median(x) | x의 중앙값 |
| var(x) | x의 분산 |
| sd(x) | x의 표준편차 |
| scale(x) | x의 표준점수(z 점수) |
| quantile(x) | x의 사분위수 |
| summary(x) | x의 요약정보 : 평균, 최소, 최대, 사분위수 등 |
예제 :
xxxxxxxxxxspeed <- cars$speedspeed# Mean speed of cars datasetmean(speed)
결과 :
xxxxxxxxxx## [1] 15.4
예제 :
xxxxxxxxxx# Median speed of cars datasetmedian(speed)결과 :
xxxxxxxxxx## [1] 15
예제 :
xxxxxxxxxx# Variance speed of cars datasetvar(speed)결과 :
xxxxxxxxxx## [1] 27.95918
예제 :
xxxxxxxxxx# Standard deviation speed of cars datasetsd(speed)
결과 :
xxxxxxxxxx## [1] 5.287644
예제 :
xxxxxxxxxx# Standardize vector speed of cars dataset head(scale(speed), 5)Output:
xxxxxxxxxx## [,1]## [1,] -2.155969## [2,] -2.155969## [3,] -1.588609## [4,] -1.588609## [5,] -1.399489
예제 :
xxxxxxxxxx# Quantile speed of cars datasetquantile(speed)Output:
xxxxxxxxxx## 0% 25% 50% 75% 100%## 4 12 15 19 25
예제 :
xxxxxxxxxx# Summary speed of cars datasetsummary(speed)결과 :
xxxxxxxxxx## Min. 1st Qu. Median Mean 3rd Qu. Max.## 4.0 12.0 15.0 15.4 19.0 25.0
지금까지 우리는 R의 많은 내장함수에 대하여 학습하였다.
주의: 인수의 클래스(예: 숫자, 논리형 또는 문자열)에 신경쓰기 바란다. 예를 들어, 문자열 값을 전달해야 할 경우 "ABC"와 같이 큰 따옴표(" ")로 문자열을 묶어야 한다.
함수 작성
어떤 경우에는 특정한 일을 해야 하는데 내장 함수가 존재하지 않는 다면 우리가 직접 함수를 작성해야 할 떄가 있다. 사용자 정의 함수(user defined fuction)는 함수 이름, 인수 그리고 본체가 포함된다.
주의: 사용자 정의 함수의 이름을 기본 내장 함수의 이름과 다르게 정하는 것이 좋은 관행이다. 혼란을 피할 수 있게 해준다.
단일 인수 함수(One argument function)
다음은 단순한 제곱함수를 정의한다. 함수는 하나의 값(인수)를 받아 들이고 그 값의 제곱을 반환한다.
xxxxxxxxxxsquare_function<- function(n){# compute the square of integer `n`n^2}# calling the function and passing value 4square_function(4)
코드 설명 :
- 함수의 이름 :
square_function; 무엇이든 우리가 원하는대로 이름을 지을 수 있다. - 함수가 받아들이는 인수 "
n". 이 인수의 데이터 타입을 지정하지 않았기 때문에 정수(integer), 벡터 또는 행렬 등을 취할 수 있다. - 함수는 "
n"을 입력값으로 받아들이고 , 그 값의 제곱을 반환한다 : (n^2)
함수를 다 사용하고 난 뒤에는 rm() 함수를 이용하여 삭제할 수 있다.
# 함수를 생성한 이후
xxxxxxxxxxrm(square_function)square_function
이제 console에서 "Error: object 'square_function'이(가) 존재하지 않는다"는 오류 메시지를 확인할 수 있다.
환경 범위
R에서 환경은 함수, 변수, 데이터 프레임 등과 같은 오브젝트의 묶음이다.
R은 Rstudio가 작동할 때 마다 환경을 연다.
이용가능한 최상위의 환경은 R_GlobalEnv라 불리는 전역 환경(global environment)이다. 그리고 우리는 부분 환경(local environment)을 갖는다.
우리는 현재의 환경의 내용을 확인할 수 있다.
xxxxxxxxxxls(environment())
결과 :
xxxxxxxxxx## [1] "diff_ts" "dt" "speed" "square_function"## [5] "ts" "x" "x_vector"
R_GlobalEnv에서생성된 모든 변수와 함수를 볼 수 있다..
위의 목록은 여러분이 R Studio를 실행하고 있는 이전에 실행한(historic) 코드에 따라 다를 것이다.
이 전역환경에 있지 않은 square_function 함수의 인수인 n을 주목하기 바란다.
각각의 함수에 대하여 새로운 환경이 생성된다. 위의 예에서는 square_function()이 전역 환경 내에 새로운 환경을 생성한다.
To clarify the difference between 전역(global)과 *부분 환경(local environment)의 차이를 이해하기 위해, 다음의 예를 살펴보도록 하자.
이 함수는 x의 값을 인수로 받아들여 함수의 외부에 정의되어 있는 y값을 가져와서 함수 내부에서 합한다.

함수 f(5)는 15 값을 반환한다. 이것은 y 가 전역 환경에서 정의되어 있기 때문이다. 전역 환경에서 정의되어 있는 변수는 부분 환경에서도 이용될 수 있다. 변수y는 함수가 호출되어 있는 동안에서는 10의 값을 가지며 언제든지 이용가능하다.
이제 변수 y가 함수 내부에서도 정의되어 있을 때 어떤 일이 생기는지 살펴보자.
먼저 rm(y) 을 이용하여 이 코드를 실행하기 전에 y 를 없애야 한다.
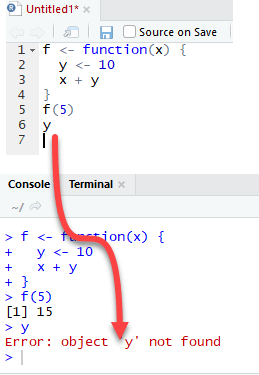
우리가 f(5)를 호출하면 결과는 15이지만, y 값을 인쇄하려고 하면 오류를 반환한다. 이제 변수 y는 전역 환경에 있지 않기 때문이다.
마지막으로 R은 함수 본체 내부를 통과하기 위해 가장 최근의 변수 정의를 사용한다. 다음 예를 고려해 보자.

R은 함수 본체 내에 y 변수를 명시적으로 생성했기 때문에 함수 외부에 정의된 y 값을 무시한다.
복수의 인수를 갖는 함수
우리는 한 개 이상의 인수를 갖는 함수를 작성할 수 있다. "times"라고 불리는 함수를 생각해 보자. 그것은 두 가지 변수를 곱하는 단순한 함수이다.
xxxxxxxxxxtimes <- function(x,y) {x*y}times(2,4)
결과 :
xxxxxxxxxx## [1] 8
언제 함수를 작성해야 하는가?
데이터 과학자들은 많은 반복적인 작업을 해야 한다. 대부분의 경우, 우리는 반복적으로 코드 조각들을 복사하고 붙여넣는다. 예를 들어, 기계 학습 알고리즘을 실행하기 전에 변수의 정규화를 적극 권장한다. 변수를 정규화하기 위한 공식은 다음과 같다.
우리는 이미 R에서 min()과 max() 함수를 사용하는 방법을 알고 있다. 우리는 데이터 프레임을 만들기 위해 tibble 라이브러리를 사용한다. tibble 은 지금까지 데이터 세트를 처음부터 만들기에 가장 편리한 함수이다.
xxxxxxxxxxlibrary(tibble)# Create a data framedata_frame <- tibble(c1 = rnorm(50, 5, 1.5),c2 = rnorm(50, 5, 1.5),c3 = rnorm(50, 5, 1.5),)
우리는 위에서 설명한 함수 계산을 위해 두 단계를 밟아야 할 것이다. 첫 단계에서는 c1을 정규화하여 c1_norm이라는 변수를 만들 것이다. 2단계에서는 c1_norm 코드를 복사하여 붙여넣기 방식으로 해서 c2와 c3도 변경한다.
c1 열 함수의 상세 내용:
분자 : : (data_frame$c1 -min(data_frame$c1))
분모 : : (max(data_frame$c1)-min(data_frame$c1))
따라서 c1열의 정규화 값을 얻기 위해 분자를 분모로 나누어 주면 된다:
xxxxxxxxxx(data_frame$c1 - min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
c1_norm, c2_norm and c3_norm 변수들을 만들 수 있다:
xxxxxxxxxxCreate c1_norm: rescaling of c1data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))# show the first five valueshead(data_frame$c1_norm, 5)
Output:
xxxxxxxxxx## [1] 0.3400113 0.4198788 0.8524394 0.4925860 0.5067991
잘 작동한다. 이제 복사와 붙여 넣기를 해서 c2와 c3도 변환한다.
xxxxxxxxxxdata_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
c1_norm을 c2_norm으로 그리고 c1을 c2로 바꿔준다. c3_norm도 같은 방법으로 만들어 준다.
xxxxxxxxxxdata_frame$c2_norm <- (data_frame$c2 - min(data_frame$c2)) /(max(data_frame$c2)-min(data_frame$c2))data_frame$c3_norm <- (data_frame$c3 - min(data_frame$c3)) /(max(data_frame$c3)-min(data_frame$c3))
이제 완벽하게 c1, c2 그리고 c3 를 변환했다.
그러나 이렇게 하는 방법은 실수를 저지르기 쉽다. 복사해서 붙여넣기 한다음 열의 이름을 바꾸는 것을 잊을 수 있다. 따라서, 두 번이상 같은 코드를 붙여넣기 해야 할 때 하나의 함수를 작성하면 좋다. 이제 코드를 하나의 공식으로 재정리하고 그것이 필요할 때마다 호출해서 사용하면 된다. 우리 만의 함수를 작성할면 다음의 것들을 정해야 한다:
- 함수 이름 : normalize
- 인수의 갯수 : 여기서는 하나의 인수만이 필요한데, 그것은 계산에서 사용하는 열이다.
- 함수의 본체 : 우리가 반환해야 할 공식이다.
normalize 함수를 만들기 위해 한단계식 진행해 보기로 한다.
단계 1) nominator 변수를 다음과 같은 수식으로 만들어 준다 :
xxxxxxxxxxnominator <- x - min(x)
단계 2) denominator를 다음과 같은 수식으로 생성한다 :
xxxxxxxxxxdenominator <- max(x) - min(x)
단계 3) nominator를 denominator로 나누어 normalize를 구하는 수식을 작성한다 :
xxxxxxxxxxnormalize <- nominator/denominator
단계 4) 함수의 결과를 얻기 위해 return()의 인수로 (단계 3)의 normalize입력하고, 이 함수를 호출할 때 그 값으로 반환해 준다.
xxxxxxxxxxreturn(normalize)
단계 5) 이제 중괄호({ }) 안에 모든 것을 위치하여 감싸 줌으로써 함수를 이용할 준비가 되었다.
xxxxxxxxxxnormalize <- function(x){# step 1: create the nominatornominator <- x - min(x)# step 2: create the denominatordenominator <- max(x) - min(x)# step 3: divide nominator by denominatornormalize <- nominator/denominator# return the valuereturn(normalize)}
변수 c1에 대하여 우리의 함수를 시험해 보자 :
xxxxxxxxxxnormalize(data_frame$c1)
완벽하게 작도잉 된다. 우리는 이제 우리의 첫 함수를 작성하였다.
함수는 반복적인 작업을 수행하기 위한 더 포괄적인 방법이다. 우리는 다른 열 변수에 대해서도 다음과 같이 normalize 함수를 사용할 수 있다 :
xxxxxxxxxxdata_frame$c1_norm_function <- normalize(data_frame$c1)data_frame$c2_norm_function <- normalize(data_frame$c2)data_frame$c3_norm_function <- normalize(data_frame$c3)
지금의 예는 단순하지만 함수의 능력을 추측할 수 있을 것이다. 위의 코드는 이해하기 쉬우며, 특히 코드를 붙여넣기 하다 발생하는 실수들을 방지해 준다.
조건을 포함하는 함수
때때로, 우리는 코드가 다른 출력을 반환할 수 있도록 함수에 조건을 포함시킬 필요가 있다.
기계 학습 과제에서는 데이터 세트를 훈련 세트(train set)와 시험 세트(test set)로 분할해야 한다. 훈련 세트는 알고리즘이 데이터로부터 학습할 수 있게 해준다. 모델 성능을 테스트하기 위해 시험 세트를 사용하여 성능 측정값을 반환할 수 있다. R에는 두 개의 데이터 세트를 생성하는 기능이 없다. 우리는 이를 위해 함수를 작성한다. 우리의 함수는 두 개의 인수를 가지고 있으며 split_data()라고 이름을 붙인다. 이면의 아이디어는 간단하다. 데이터 집합의 길이(예: 관측 데이터의 수)를 0.8로 곱한다. 예를 들어, 데이터 세트를 80:20으로 분할하고, 데이터 세트에 100개의 행이 포함되어 있다면, 우리의 함수는 0.8*100 = 80을 반환한다. 이제 80개의 행이 우리의 훈련 데이터로 선택될 것이다.
We will use the airquality dataset to test our user-defined function. The airquality dataset has 153 rows. We can see it with the code below:
우리는 사용자 정의 함수를 테스트하기 위해 airquality데이터 세트를 사용할 것이다. airquality데이터 세트는 153개의 행을 가지고 있다. 아래 코드로 확인할 수 있다.
xxxxxxxxxxnrow(airquality)
결과 :
xxxxxxxxxx## [1] 153
다음과 같이 진행해 나가자 :
xxxxxxxxxxsplit_data <- function(df, train = TRUE)
인수 :
- df : 데이타 세트 정의
- train : 함수가 훈련 데이터 혹은 시험 데이터 반환할 지를 지정. 기본 값으로
TRUE로 설정.
우리의 함수는 두 개의 인수를 가지고 있다. train 인수는 부울리안 파라미터이다.TRUE로 설정되어 있으면 훈련 데이터 세트를 그렇지 않으면 시험 데이터 세트를 생성한다.
이제 normalize() 함수 작성할 때와 같은 방식으로 진행해 나간다. 단지 한번 사용하는 코드처럼 코드를 작성한 다음, 함수를 생성하기 위해 본체안에 조건식을 갖는 모든 것을 둘러 싼다.
단계 1 :
데이터 세트의 길이를 계산한다. 이는 nrow() 함수로 수행된다. nrow는 데이터 세트에 있는 총 행의 갯수를 반환한다. 이 값을 변수 length로 설정한다.
xxxxxxxxxxlength<- nrow(airquality)length
결과 :
xxxxxxxxxx## [1] 153
Step 2:
이 길이에 0.8을 곱한다. 그것은 선택할 행의 갯수를 반환할 것이다. 즉, 153 * 0.8 = 122.4가 될 것이다..
xxxxxxxxxxtotal_row <- length * 0.8total_row
결과 :
xxxxxxxxxx## [1] 122.4
airquality 데이터 세트에 있는 153개의 행 중에서 122개를 선택하고자 한다. 1 부터 total_row 까지의 값을 포함하는 리스트를 생성한다. 그리고 그 결과를 split 변수에 저장한다.
xxxxxxxxxxsplit <- 1:total_rowsplit[1:5]
결과 :
xxxxxxxxxx## [1] 1 2 3 4 5
split 변수는 데이터 세트에서 앞에 있는 122개의 행을 선택한다. 예를 들어, split 변수가 1, 2, 3, 4, 5 의 값들을 모아 놓고 있는 것을 볼 수 있다. 이 값들은 반환할 행들이 선택될 때의 색인 번호가 될 것이다.
결과 3:
split 변수에 저장되어 있는 값을 가지고 airquality데이터 세트에 있는 행들을 선택해야 한다. 이것은 다음과 같이 하면 된다 :
xxxxxxxxxxtrain_df <- airquality[split, ]head(train_df)
결과 :
xxxxxxxxxx##[1] Ozone Solar.R Wind Temp Month Day##[2] 51 13 137 10.3 76 6 20##[3] 15 18 65 13.2 58 5 15##[4] 64 32 236 9.2 81 7 3##[5] 27 NA NA 8.0 57 5 27##[6] 58 NA 47 10.3 73 6 27##[7] 44 23 148 8.0 82 6 13
단계 4 : 이제 남은 123:153의 행들을 가지고 시험 데이터 세트를 생성할 수 있다. 이것은 split 변수 앞에 - 를 사용하여 이루어 진다.
xxxxxxxxxxtest_df <- airquality[-split, ]head(test_df)
결과 :
xxxxxxxxxx##[1] Ozone Solar.R Wind Temp Month Day##[2] 123 85 188 6.3 94 8 31##[3] 124 96 167 6.9 91 9 1##[4] 125 78 197 5.1 92 9 2##[5] 126 73 183 2.8 93 9 3##[6] 127 91 189 4.6 93 9 4##[7] 128 47 95 7.4 87 9 5
Step 5:
함수의 본체 안에 조건문을 작성할 수 있다. 그런데 여기에서 train 인수가 부울리안으로 기본적으로 시험 데이터 세트를 반환하도록 TRUE로 설정되어 있다는 것을 기억하자. 조건문을 작성하기 위해 다음의 구문법을 사용한다 :
xxxxxxxxxxif (train ==TRUE){train_df <- airquality[split, ]return(train)} else {test_df <- airquality[-split, ]return(test)}
이제 함수를 작성할 수 있다. 단지 airquality를 df로 만 바꿔주면 된다. 그 이유는 우리 함수가 airquality 뿐만 아니라 어떠한 데이터 프레임도 사용할 수 있게 하고 싶기 때문이다 :
xxxxxxxxxxsplit_data <- function(df, train = TRUE){length<- nrow(df)total_row <- length *0.8split <- 1:total_rowif (train ==TRUE){train_df <- df[split, ]return(train_df)} else {test_df <- df[-split, ]return(test_df)}}
airquliaty 데이터 세트를 가지고 함수를 시험해 보자. 우리는 122 개 행의 훈련 데이터 세트와 31개의 시험 데이터 세트를 얻어야 한다.
xxxxxxxxxxtrain <- split_data(airquality, train = TRUE)dim(train)
결과 :
xxxxxxxxxx## [1] 122 6test <- split_data(airquality, train = FALSE)dim(test)
결과 :
xxxxxxxxxx## [1] 31 6
성공 !!!