데이터 불러오기 : CSV, Excel, SPSS, Stata, SAS 파일들 읽기
데이터는 다양한 형식으로 존재할 수 있다. 각각의 형식에 대해 R은 특정의 함수와 인수를 갖는다. 이 튜토리얼은 R에 데이터를 불러오는 방법을 설명한다.
이 튜토리얼에서는 다음에 대하여 학습한다 :
- CSV 파일 읽기
- 엑셀 파일 읽기
- readxl_example() 함수
- read_excel() 함수
- excel_sheets() 함수
- 다른 통계 소프트웨어 데이터 불러오기
- SAS 데이터 읽기
- STATA 데이터 읽기
- SPSS 데이터 읽기
- 데이터 불러오기 최선의 관행
CSV 파일 읽기
가장 널리 사용되는 데이터 저장소 중 하나는 .csv(comma separated values) 파일 형식이다. R은 시작 시 utils 패키지를 포함한 일련의 라이브러리를 적재한다. 이 패키지는 read.csv() 함수와 연결된 csv 파일을 열 수 있어 편리하다. read.csv()의 표현법은 다음과 같다 :
xxxxxxxxxxread.csv(file, header = TRUE, sep = ",")
Argument:
- file : 파일이 저장된 PATH(경로)
- header : 파일이 헤더를 가지고 있는지를 확인. 기본적으로 header값은 'TRUE'로 설정.
- sep : 변수를 구분짓는데 사용되는 기호. 기본적으로
,.
우리는 데이터 파일 이름 mtcats를 읽을 것이다. csv 파일은 온라인에 저장된다. .csv 파일이 로컬에 저장되어 있으면 코드 내에 PATH(경로)를 지정할 수 있다. ' '안에 싸는 것을 잊지 말아라. PATH(경로)는 문자열 값이어야 한다.
맥 사용자의 경우, 다운로드 폴더에 대한 PATH(경로)는 다음과 같다 :
xxxxxxxxxx"/Users/USERNAME/Downloads/FILENAME.csv"
윈도우즈 사용자의 경우 :
xxxxxxxxxx"C:\Users\USERNAME\Downloads\FILENAME.csv"
항상 파일명과 확장자까지 지정해야 함을 주의하기 바란다.
- .csv
- .xlsx
- .txt
- …
xxxxxxxxxxPATH <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/mtcars.csv'df <- read.csv(PATH, header = TRUE, sep = ',')length(df)
결과 :
xxxxxxxxxx## [1] 12
xxxxxxxxxxclass(df$X)결과 :
xxxxxxxxxx## [1] "factor"
R은 기본적으로 문자 값을 factor로 반환한다. stringsAsFactors = FALSE 를 추가하면 이 설정을 해제할 수 있다.
xxxxxxxxxxPATH <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/mtcars.csv'df <-read.csv(PATH, header =TRUE, sep = ',', stringsAsFactors =FALSE)class(df$X)
결과 :
xxxxxxxxxx## [1] "character"
변수 x의 클래스는 이제 '문자'이다.
엑셀 파일 읽기
엑셀 파일은 데이터 분석가들 사이에서 매우 인기가 있다. 스프레드시트는 작업하기 쉽고 유연하다. R에는 Excel 스프레드시트를 불러오기 위한 readxl라이브러리가 장착되어 있다.
readxl을 컴퓨터에 설치하려면 다음의 코드를 사용한다.
xxxxxxxxxxrequire(readxl)
r-conda-equential과 R을 함께 설치하면 라이브러리가 이미 설치된다. 명령 창에서 확인할 수 있다.
결과 :
xxxxxxxxxxLoading required package: readxl.
패키지가 존재하지 않는 경우, 콘다 라이브러리와 함께 설치하거나, 또는 터미널에서 conda install -c mittner r-readxl을 사용하라.
다음 명령을 사용하여 Excel 파일을 불러오려면 다음의 라이브러리를 사용해야 한다.
xxxxxxxxxxlibrary(readxl)
readxl_example() 함수
이 튜토리얼에서는 패키지의 readxl에 포함된 예를 사용한다.
라이브러리에 있는 이용가능한 스프레드시트를 알려면 다음의 코드를 사용한다.
xxxxxxxxxxreadxl_example()
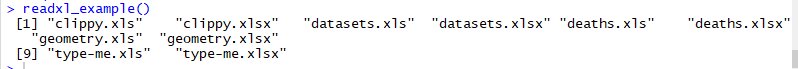
geometry.xls 스프레드시트의 위치를 확인하려면 단순히 다음과 같이 입력한다.
xxxxxxxxxxreadxl_example("geometry.xls")

conda와 함께 R을 설치하며, 스프레드시트는 Anaconda3/lib/R/library/readxl/extdata/filename.xls 에 위치한다.
read_excel() 함수
read_excel() 함수는 xls 및 xlsx 확장자 파일에 있어 매우 유용하다.
표현법은 다음과 같다 :
xxxxxxxxxxread_excel(PATH, sheet = NULL, range= NULL, col_names = TRUE)
arguments :
- PATH : 엑설 파일이 위치한 경로
- sheet : 불러올 시트를 선택한다. 기본 값은 all
- range : 불러올 범위를 선택한다. 기본 값은 비어 있지 않은(non-null) 모든 셀
- col_names : 불러올 열을 선택한다. 기본 값은 비어 있지 않은(non-null) 모든 열
readxl 라이브러리를 이용하여 스프레드쉬트를 블러올 수 있고, 첫 번째 시트의 열 수를 셀 수 있다.
xxxxxxxxxx# Store the path of `datasets.xlsx`example <- readxl_example("datasets.xlsx")# Import the spreadsheetdf <- read_excel(example)# Count the number of columnslength(df)
결과 :
xxxxxxxxxx## [1] 5
excel_sheets() 함수
The file datasets.xlsx is composed of 4 sheets. We can find out which sheets are available in the workbook by using excel_sheets() function
datasets.xlsx 파일은 4개의 시트로 구성되어 있다. excel_sheet() 함수를 사용하여 워크북에서 사용 가능한 시트를 확인할 수 있다.
xxxxxxxxxxexample <- readxl_example("datasets.xlsx")excel_sheets(example)
결과 :
xxxxxxxxxx[1] "iris" "mtcars" "chickwts" "quakes"
하나의 워크시트에 많은 시트가 포함되어 있는 경우, 시트 인수를 사용하여 특정 시트를 쉽게 선택할 수 있다. 우리는 시트의 이름이나 시트의 색인을 지정할 수 있다. 두 함수가 같은 결과를 반환하는지 identical() 함수르로 확인할 수 있다.
xxxxxxxxxxexample <- readxl_example("datasets.xlsx")quake <- read_excel(example, sheet = "quakes")quake_1 <-read_excel(example, sheet = 4)identical(quake, quake_1)
결과 :
xxxxxxxxxx## [1] TRUE
우리는 두 가지 방법으로 읽어 올 셀을 지정할 수 있다.
- n 개의 행을 반환하기 위해
n_max인수를 사용한다. cell_rows혹은cell_cols과 연결하여range인수를 사용한다.
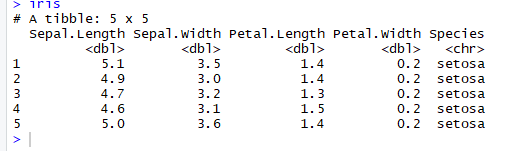
예를 들어, 우리는 앞의 5개 행을 불러오기 위해 n_max = 5 라고 설정한다.
xxxxxxxxxx# Read the first five row: with headeriris <-read_excel(example, n_max =5, col_names =TRUE)iris
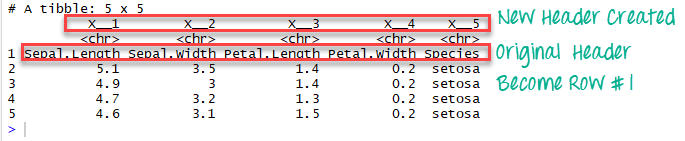
xxxxxxxxxx# Read the first five row: without headeriris_no_header <-read_excel(example, n_max =5, col_names =FALSE)iris_no_header
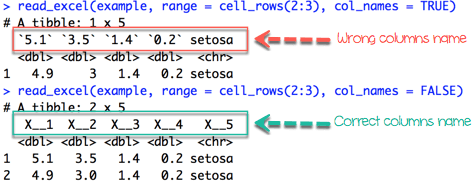
iris_no_header 데이터 프레임에서 , R은 x_1, x_2, x_3, x_4, x_5 등의 다섯 변수를 생성했다.
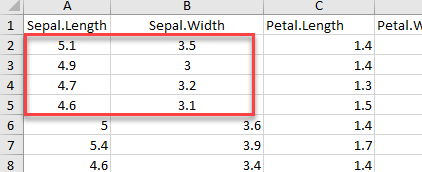
우리는 또한 스프레드 시트의 행과 열을 선택하기 range 인수를 사용할 수 있다. 아래의 코드에서, 우리는 A1:B5 범위를 선택하기 excel 형식을 사용한다.
xxxxxxxxxx# Read rows A1 to B5example_1 <-read_excel(example, range = "A1:B5", col_names =TRUE)dim(example_1)
결과 :
xxxxxxxxxx## [1] 4 2
우리는 example_1이 2개의 열, 4개의 행을 반환한다는 것을 알 수 있다. 데이터 세트는 헤더를 가지고 있고, 차수는 4x2 이다.
두 번째 예에서 우리는 반환할 행의 범위를 제어하는 cell_rows() 함수를 사용한다. 1 ~ 5 행을 불러오려면 cell_rows(1:5)를 설정할 수 있다. cell_rows(1:5)는 cell_rows(5:1)과 동일한 결과를 반환한다.
xxxxxxxxxx# Read rows 1 to 5example_2 <-read_excel(example, range =cell_rows(1:5),col_names =TRUE)dim(example_2)
결과 :
xxxxxxxxxx## [1] 4 5
그러나 example_2는 4x5 행렬이다. iris 데이터 세트는 헤더가 있는 5개의 열을 가지고 있다. 모든 열의 헤더와 함께 처음 네 개의 행을 반환한다.
만일 첫번쨰 행에서 시작하지 않는 행들을 불러오고자 한다면, col_names = FALSE를 포함해야 한다. range = cell_rows(2:5)를 사용하면, 그 결과는 이제 헤더가 없는 데이터 프레임이 된다.
xxxxxxxxxxiris_row_with_header <- read_excel(example, range = cell_rows(2:3), col_names = TRUE)iris_row_no_header <- read_excel(example, range = cell_rows(2:3),col_names = FALSE)
xxxxxxxxxxWe can select the columns with the letter, like in Excel.# Select columns A and Bcol <- read_excel(example, range = cell_cols("A:B"))dim(col)
결과 :
xxxxxxxxxx## [1] 150 2
주의 : range = cell_cols("A:B")는 Null이 아닌 값을 가진 모든 셀을 출력한다. 데이터 세트는 150개의 행을 포함하므로 read_excel()은 최대 150개의 행을 반환한다. 이것은 dim() 함수로 확인된다.
read_excel()은 셀에 숫자 값이 없는 기호가 나타나면 NA를 반환한다. 두 함수의 조합으로 결측치(missing values)의 갯수를 셀 수 있다.
sumis.na
여기에 코드가 있다.
xxxxxxxxxxiris_na <-read_excel(example, na ="setosa")sum(is.na(iris_na))
결과 :
xxxxxxxxxx## [1] 50
'setosa' 종에 속하는 행들인 50개의 결측치가 있다.
다른 통계 소프트웨어 데이터 불러오기
우리는 heaven 패키지로 다른 파일 형식을 불러올 것이다. 이 패키지는 SAS, STATA 및 SPSS 소프트웨어를 지원한다. 파일 확장자에 따라 다음의 함수를 사용하여 다양한 유형의 데이터 세트를 열 수 있다 :
- SAS :
read_sas() - STATA :
read_dta()또는read_stata() - SPSS :
read_sav()orread_por(). 확장자를 확인해야 한다.
이 함수에는 하나의 인수만 필요하다. 파일이 저장되어 있는 경로(PATH)를 알아야 한다. SAS, STATA 및 SPSS의 모든 파일을 열 준비가 되어 있다. 이 세 함수들은 URL도 받아들인다.
xxxxxxxxxxlibrary(haven)
haven 은 conda r-essential에 딸려 있다. 그렇지 않으면 링크에 접속하거나, 터미널에서 conda install -c conda-forge r-haven을 입력한다.
SAS 데이터 읽기
다음의 예를 위해, IDRE의 admission 데이터 세트를 사용할 것이다.
xxxxxxxxxxPATH_sas <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.sas7bdat?raw=true'df <- read_sas(PATH_sas)head(df)
결과 :
xxxxxxxxxx## # A tibble: 6 x 4## ADMIT GRE GPA RANK## <dbl> <dbl> <dbl> <dbl>## 1 0 380 3.61 3## 2 1 660 3.67 3## 3 1 800 4.00 1## 4 1 640 3.19 4## 5 0 520 2.93 4## 6 1 760 3.00 2
STATA 데이터 읽기
STATA 데이터 파일은 read_dta()로 불러올 수 있다. 같은 데이터 세트로서 .dta 확장자로 저장된 파일을 사용한다.
xxxxxxxxxxPATH_stata <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.dta?raw=true'df <- read_dta(PATH_stata)head(df)
결과 :
xxxxxxxxxx## # A tibble: 6 x 4## admit gre gpa rank## <dbl> <dbl> <dbl> <dbl>## 1 0 380 3.61 3## 2 1 660 3.67 3## 3 1 800 4.00 1## 4 1 640 3.19 4## 5 0 520 2.93 4## 6 1 760 3.00 2
SPSS 데이터 읽기
read_sav() 함수를 이용하여 SPSS 파일을 불러온다. 파일의 확장자는 '.sav'이다.
xxxxxxxxxxPATH_spss <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.sav?raw=true'df <- read_sav(PATH_spss)head(df)
결과 :
xxxxxxxxxx## # A tibble: 6 x 4## admit gre gpa rank## <dbl> <dbl> <dbl> <dbl>## 1 0 380 3.61 3## 2 1 660 3.67 3## 3 1 800 4.00 1## 4 1 640 3.19 4## 5 0 520 2.93 4## 6 1 760 3.00 2
데이터 불러오기 최선의 관행
R로 데이터를 불러오려면 다음 체크리스트를 실행하는 것이 유용하다. 그러면 R로 데이터를 불러오는 것이 쉬울 것이다 :
- 스프레드시트의 일반적인 형식은 첫 행에 (변수 명인) 헤더를 사용한다.
- 데이터 세트의 이름에는 공란을 사용하지 않는다. 공란은 변수를 구분하는 것으로 해석될 수 있기 때문이다. 변수명에 공란대신에 '_' 혹은 '-'를 사용한다.
- 짧은 이름이 선호된다.
- 이름에는 기호를 포함하지 않는다. 즉,
exchange_rate_$_€는 부적절한다.exchange_rate_dollar_euro로 사용하는 것이 좋다. - 결측치는
NA를 사용한다. 그렇게 하지 않으면 나중에 그 형식을 정리해야 한다.
요약
다음 표는 R에서 다른 유형의 파일을 불러오기 위해 사용할 함수가 요약되어 있다. 제1열에는 함수와 관련된 라이브러리가 표시되어 있다. 마지막 열에는 기본적인 인수 값이 수록되어 있다.
| 라이브러리 | 목적 | 함수 | 기본 인수 값 |
|---|---|---|---|
| utils | CSV 파일 읽기 | read.csv() | file, header =TRUE, sep = "," |
| readxl | EXCEL 파일 읽기 | read_excel() | path, range = NULL, col_names = TRUE |
| haven | SAS 파일 읽기 | read_sas() | path |
| haven | STATA 파일 읽기 | read_stata() | path |
| haven | SPSS 파일 읽기 | read_sav() | path |
다음의 표는 read_excel()로 선택하여 불러올 수 있는 다양한 방법을 보여준다.
| 함수 | 목적 | 인수 |
|---|---|---|
| read_excel() | n개의 행 읽기 | n_max = 10 |
| 엑셀에서 같이 행과 열 선택 | range = "A1:D10" | |
| 색인으로 행 선택 | range= cell_rows(1:3) | |
| 문자로 열 선택 | range = cell_cols("A:C") |