15.1 for 반복문
for 반복구문은 특정 횟수 동안 반복적으로 코드 문을 실행하는데 사용됩니다.
for 반복구문의 플로우 차트는 다음과 같습니다.
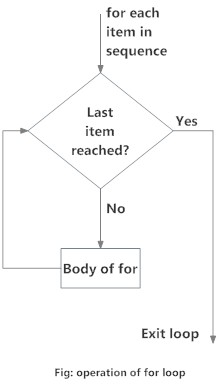
r for loop flowchart
for 반복구문의 형식은 다음과 같습니다.
for (val in sequence) # val 값을 sequence의 첫번째 값부터 마지막까지 하나씩 할당합니다.
{
statement # 반복실행되는 명령문입니다.
}for 구문의 일반적인 형식은 i 를 카운터로 하고 이 카원터가 순차적으로 증가하는 i번째 값에서 코드의 본체(body)가 실행되는 for 루프는 특정 횟수 동안 반복적인 명령문을 실행하는 데 사용됩니다. i가 카운터이고 i가 정의되어 있는 각 순차 값(이 예에서는 1부터 100까지)을 가정하므로 본문의 코드가 i 번째 값에 대해 수행되는 일반적인 구문은 다음과 같습니다.
# for 반복구문의 형식
for(i in 1:100) {
<do stuff here with i>
}예를 들어, 다음 ‘for’ 반복은 i가 가질 수 있는 값 (2010, 2011,…, 2016)의 범위인 2010에서 시작하여 2016의 값을 가질 때까지 중괄호 안에 있는 블럭의 ‘paste()’ 함수와 ‘print()’ 함수를 반복적으로 수행합니다.
for (i in 2010:2016){
output <- paste("The year is", i)
print(output)
}## [1] "The year is 2010"
## [1] "The year is 2011"
## [1] "The year is 2012"
## [1] "The year is 2013"
## [1] "The year is 2014"
## [1] "The year is 2015"
## [1] "The year is 2016"만일 for 루프를 수행하여 output을 벡터 또는 다른 데이터 구조로 결합시키려면 for 루프 이전에 output 데이터 구조를 지정할 수 있습니다. 예를 들어, 앞의 output출력 결과들을 하나의 벡터 x로 결합하고자 한다면 먼저 x를 for 루프 이전에 정의한 다음, for 루프 안에서 output 을 x에 추가하면 됩니다.
그 결과는 앞의 예에서 보았던 output 의 결과들이 벡터 x의 요소가 된다는 것입니다.
# 블록 내의 output 결과를 하나의 벡터 x로 결합하기
x <- NULL # x를 정의합니다.
for (i in 2010:2016){ # for 반복구문의 시작입니다.
output <- paste("The year is", i) # paste() 결과를 output에 할당합니다.
x <- append(x, output) # x에 output을 추가합니다.
}
x # 최종적으로 하나의 벡터 x로 출력됩니다.## [1] "The year is 2010" "The year is 2011" "The year is 2012" "The year is 2013"
## [5] "The year is 2014" "The year is 2015" "The year is 2016"그러나 학습해야 할 중요한 교훈은 R이 데이터 개체를 증가(growing)시키는 데 효율적이지 않다는 것입니다. 결과적으로 빈 데이터 객체를 만들고for 루프 출력으로 채우는(filling) 것이 더 효율적입니다. 이전 예에서는 새 값을 추가하여 x를 증가시켰습니다. 보다 효율적인 방법은 적당한 길이의 벡터 (또는 기타 데이터 구조)를 미리 정의하고 그 요소를 채우는 것입니다. 다음 예에서는 올바른 크기의 벡터 x 를 만든 다음 for 루프 내에서 각 요소를 채우는 것을 보여 주고 있습니다. 이 작은 예제에서는 이러한 비효율성이 눈에 띄지 않지만 더 큰 반복을 수행하면 눈에 띄게 될 것이므로 증가보다는 채우기 습관을 갖는 것이 좋습니다.
## 적당한 길이의 벡터를 그 유형과 함께 정의합니다.
x <- vector(mode = "numeric", length = 7) # 숫자형으로 길이가 7인 벡터 x를 정의합니다.
counter <- 1 # counter 변수의 초기값으로 1을 설정합니다.
for (i in 2010:2016){ # for 반복구문의 시작입니다.
output <- paste("The year is", i) # paste() 결과를 output에 할당합니다.
x[counter] <- output # output 결과를 x 요소로 채워 넣습니다.
counter <- counter + 1 # counter를 1증가 시킵니다.
}
x## [1] "The year is 2010" "The year is 2011" "The year is 2012" "The year is 2013"
## [5] "The year is 2014" "The year is 2015" "The year is 2016"다음의 예는 5 개의 행과 5 개의 열로 된 빈 행렬 my.dat를 정의하여 채워가는 예입니다. my.dat 행렬을 미리 정의한 다음for 루프가 각 열에 대하여 반복적으로 (여기에서 i가my.mat 행렬의 열 번호 값 1을 어떻게 취하는지 주목하기 바랍니다.) i 컬럼에 있는 평균 i를 갖는 포아송 분포에서 추출된 5개의 난수를 가져와 각 열의 요소로 채우게 됩니다. :
my.mat <- matrix(NA, nrow = 5, ncol = 5) # my.dat 행렬을 미리 정의합니다.
set.seed(1000) # 난수의 초기값을 지정합니다.
for(i in 1:ncol(my.mat)){ # for 반복구문의 시작입니다.
my.mat[, i] <- rpois(5, lambda = i) # ㅑ 컬럼을 rpois() 함수 반환값으로 할당합니다.
}
my.mat## [,1] [,2] [,3] [,4] [,5]
## [1,] 0 0 2 1 3
## [2,] 2 3 4 4 7
## [3,] 0 2 2 5 4
## [4,] 1 1 5 1 2
## [5,] 1 1 4 4 5