7.1 ggplot2
ggplot2는 필수적인 플로팅을 하게 해 주는 tidyverse 방법이다. 이는 이전 장에서 이미 보았던 데이터 플로팅의 base R 방법을 대체하고 향상시킨다. 지난 장에서 dplyr에 대한 논의에서 기대할 수 있듯이 ggplot2는 데이터 시각화를 수행하는 매우 독자적인 방법을 제공한다. 일일 데이터 탐색과 정적 그래픽이 허용되는 보고서에 포함하기 위해 ggplot2를 사용한다.
ggplot2를 사용하는 방법을 살펴 보자.
첫째, 다른 tidyverse 패키지와 마찬가지로 library() 함수를 사용하여 tidyverse 패키지를 불러온다.
library(tidyverse)
source("process_data.R")##
## -- Column specification --------------------------------------------------------
## cols(
## Year = col_double(),
## Race = col_character(),
## Sex = col_character(),
## `Average Life Expectancy (Years)` = col_double(),
## `Age-adjusted Death Rate` = col_double()
## )tidyverse를 불러온 한 후 코드의 두 번째 줄에서 source() 명령을 사용하여 “process_data.R” 파일에 저장한 모든 코드를 다시 실행했다. 이를 통해 expectation 데이터 세트의 구조를 사용할 수 있게 해 준다.
ggplot2를 사용하기 위해 데이터 세트를 ggplot() 함수로 파이프할 수 있다. 이 함수를 사용하려면 플로팅 할 변수를 지정해야 한다.
expectancy %>% filter(race == "All Races", sex == "Both Sexes") %>%
ggplot(aes(year, life_expectancy))이 코드를 실행하면 그림 7.1과 같이 X축과 Y 축이 이미 정의된 빈 캔버스가 나타난다.
그림 7.1: 빈 ggplot 캔버스
그림 7.1은 X 축에 연도, Y 축에 사망률이 있는 캔버스를 보여주고 있다. 이제 플롯의 범위를 정의했으므로 데이터를 표시하는 시각적 요소를 추가 할 수 있습니다. ggplot 함수를 데이터 스토리를 설명하는 “동사”세트로 파이핑하여 이를 수행한다.
expectancy %>% filter(race == "All Races", sex == "Both Sexes") %>%
ggplot(aes(year, life_expectancy)) +
geom_line()geom_line 동사를 사용하여 데이터를 표현하기 위해 선을 사용하고 싶다고 말했다. 예상 할 수있는 magrittr 파이프 연산자 (%>%)를 사용하는 대신 ggplot2는 파이프에 더하기 기호 (+)를 사용한다. 이 선 플롯의 예는 그림 7.2를 참조하기 바란다.
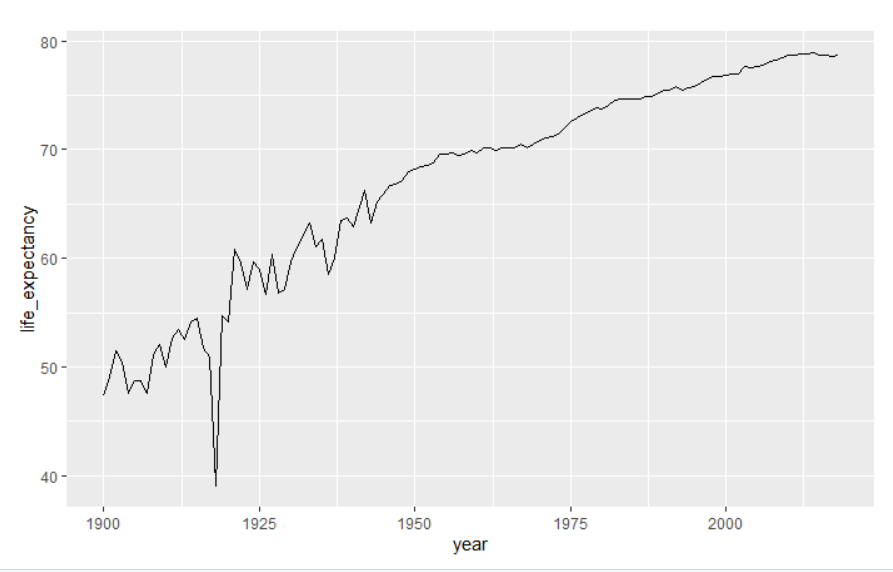
그림 7.2: 연도 별 사망률 선 플롯
그림 7.2의 플롯은 흥미로운 추세와 나중에 설명할 이상 값(outliers)을 보여주고 있다. 파이프 연산자 +를 사용하여 시각화를 파이핑하여 계속해서 시각화할 수 있다.
선에 점을 추가하려면 geom_point 동사를 사용한다.
expectancy %>% filter(race == "All Races", sex == "Both Sexes") %>%
ggplot(aes(year, life_expectancy)) +
geom_line() +
geom_point()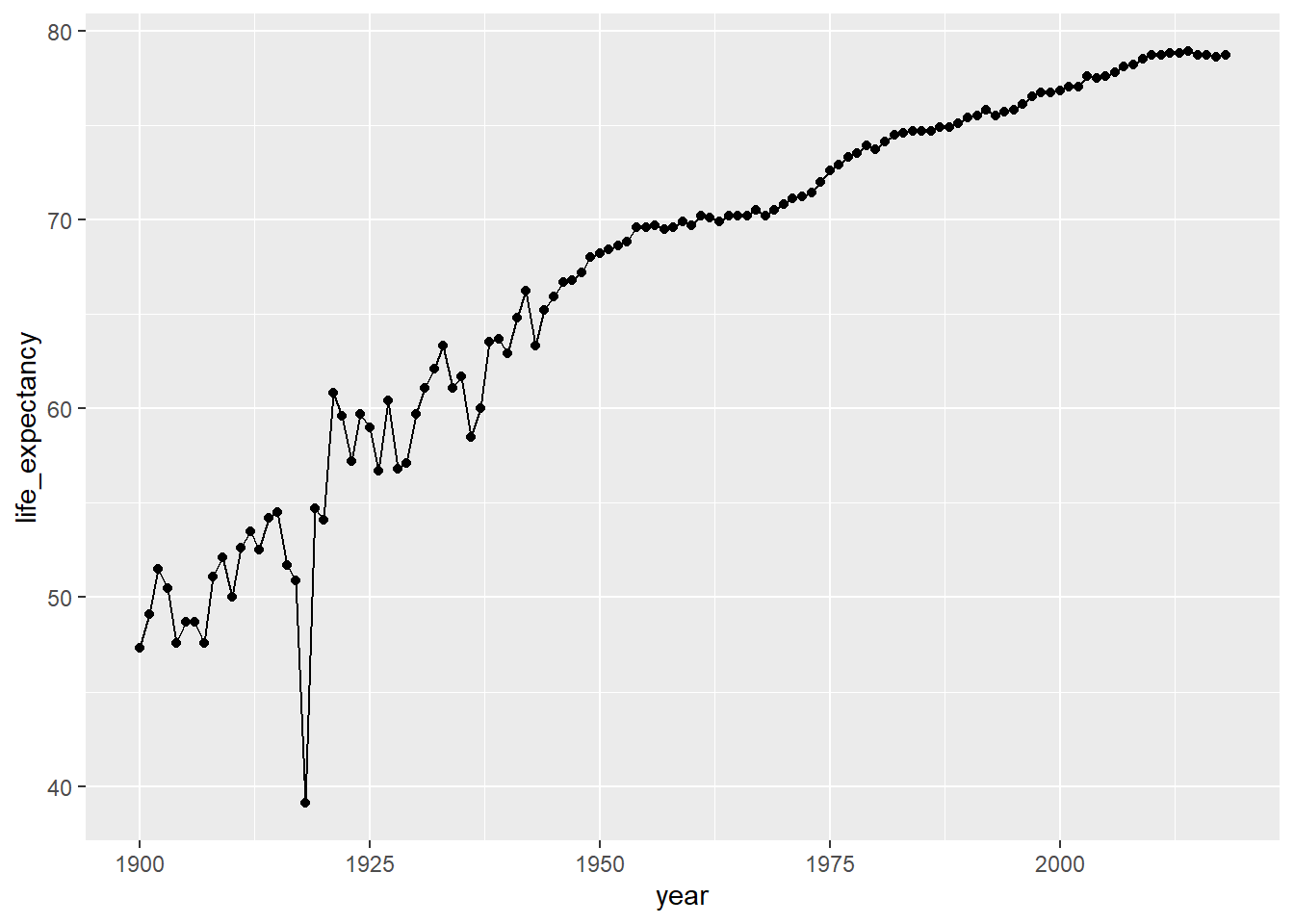
그러면 그림 7.3과 같이 플롯이 생성된다.
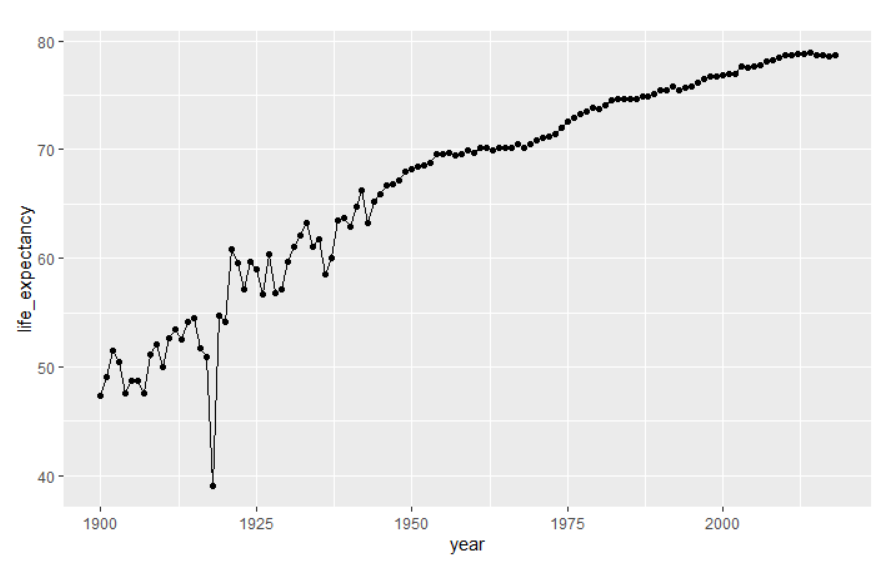
그림 7.3: 라인 플롯에 포인트 마커 추가
이 추세를 성별로 분류하고 싶다면 어떨까? ggplot 라인 플롯에서 이와 같은 하위 그룹을 보려면 분류하려는 geom_line 동사에 새로운 미적(aes) 매개 변수를 추가하기 만하면 된다.
expectancy %>% filter(race == "All Races") %>%
ggplot(aes(year, life_expectancy)) +
geom_line(aes(color = sex))이 시각화의 첫 번째 부분에서는 세 그룹을 모두 살펴 보고자하기 때문에 더 이상 “Both Sexes”를 필터링하지 않는다. 이 코드는 그림 7.4의 플롯을 생성한다.
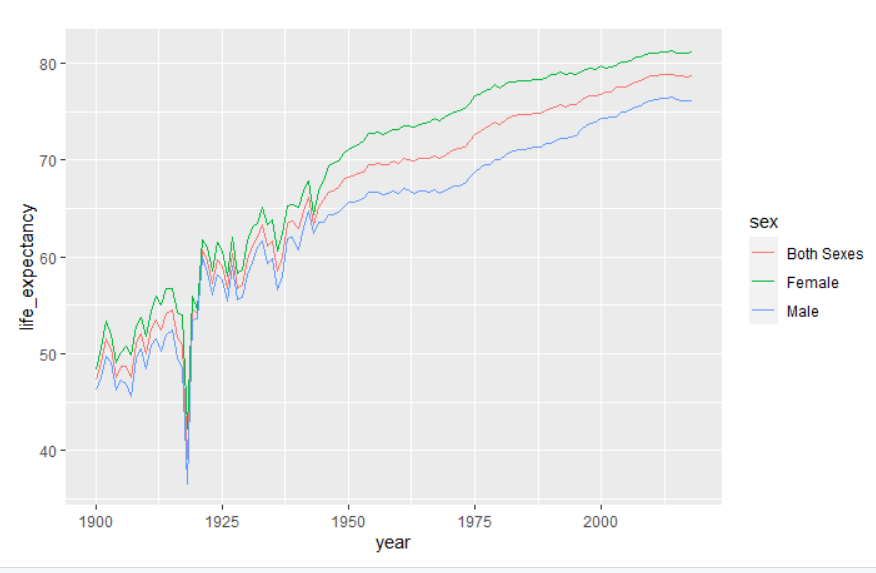
그림 7.4: ggplot에서 하위 그룹 플로팅
이 그림은 두 성별 간의 관계를 보여준다. geom_line에서 aes의 color 인수를 지정했기 때문에 선이 색상으로 나타난다.
이 장에서 다루고 있는 ggplot에는 훨씬 더 많은 여지가 있다. 레이블 및 제목 옵션과 함께 다양한 유형의 데이터를 표시할 수있는 많은 옵션이 있다. 이 패키지는 본질적으로 RStudio의 시각화 도구이기도 하다. 이 패키지의 사용 방법에 대한 자세한 정보는 공식 웹 사이트 ggplot2를 참조하기 바란다.