5.2 R 코드 파일
처음에는 제공된 위젯과 대화형 콘솔 화면을 사용하는 것이 쉬울 수 있지만 분석을 다시 실행하거나 동료에게 분석을 실행하도록 요청하려면 지금까지의 단계를 다시 추적하기가 어렵다. 분석을 실제로 재현할 수 없다.
작업을 재현할 수 있도록 프로젝트에 R 스크립트 파일을 추가할 수 있다. 이제 할 일은 R 스크립트 파일을 추가 한 다음 자동으로 생성된 코드를 이 파일에 추가하여 그림에서 재사용 할 수 있도록 하는 것입니다.
RStudio 메뉴 모음으로 이동하여 “파일” ➤ “새 파일” ➤ “R 스크립트”를 선택한다. 그림 5.6에 표시된 새 탭이 “Untitled1”이라는 레이블이 붙은 데이터 프레임 옆에 나타난다.
그림 5.6: 스크립트 편집기
이 스크립트 편집기는 상단의 시각적 바로 가기 막대와 함께 매우 유용한 내부 기능을 제공한다. 먼저 플로피 디스크 아이콘을 클릭하여 기억에 남는 이름으로 이 파일을 프로젝트에 저장한다. 플로피 디스크 아이콘을 클릭하고 나타나는 대화 상자에서 파일의 이름을 “process_data.R”로 입력한다. 이제 파일이 파일 탐색기에 나타나고 이름을 클릭하여 언제든지 파일을 열 수 있다.
여기에서 코드 도구에 대해 이야기 할 때 다른 기능을 살펴 보겠지만 지금은 여기에 작업을 저장하고 위의 “실행”과 “소스” 버튼을 사용하여 코드를 실행할 수도 있다. 지금은 csv 파일에서 읽은 자동 생성된 코드를 검색한 다음 이 데이터 프레임에서 약간의 관리 작업을 수행하려고 한다.
오른쪽에 있는 “History” 탭을 열면 그림 5.7과 같이 csv 파일을 읽는 데 사용 된 코드 줄이 표시된다. 실행했던 명령어들을 클릭하여 코드의 처음 두 줄을 강조 표시 즉 선택한다.
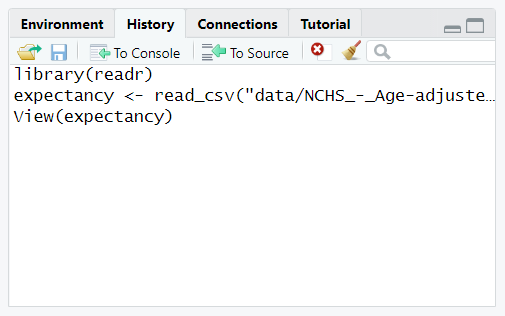
그림 5.7: 히스토리 탭에서 코드 검색
“To Source” 버튼을 클릭하여 이 코드를 R 스크립트 파일로 이동시킨다. 그런 다음 플로피 디스크 아이콘을 클릭하여 그림 5.8과 같이 파일을 저장한다.
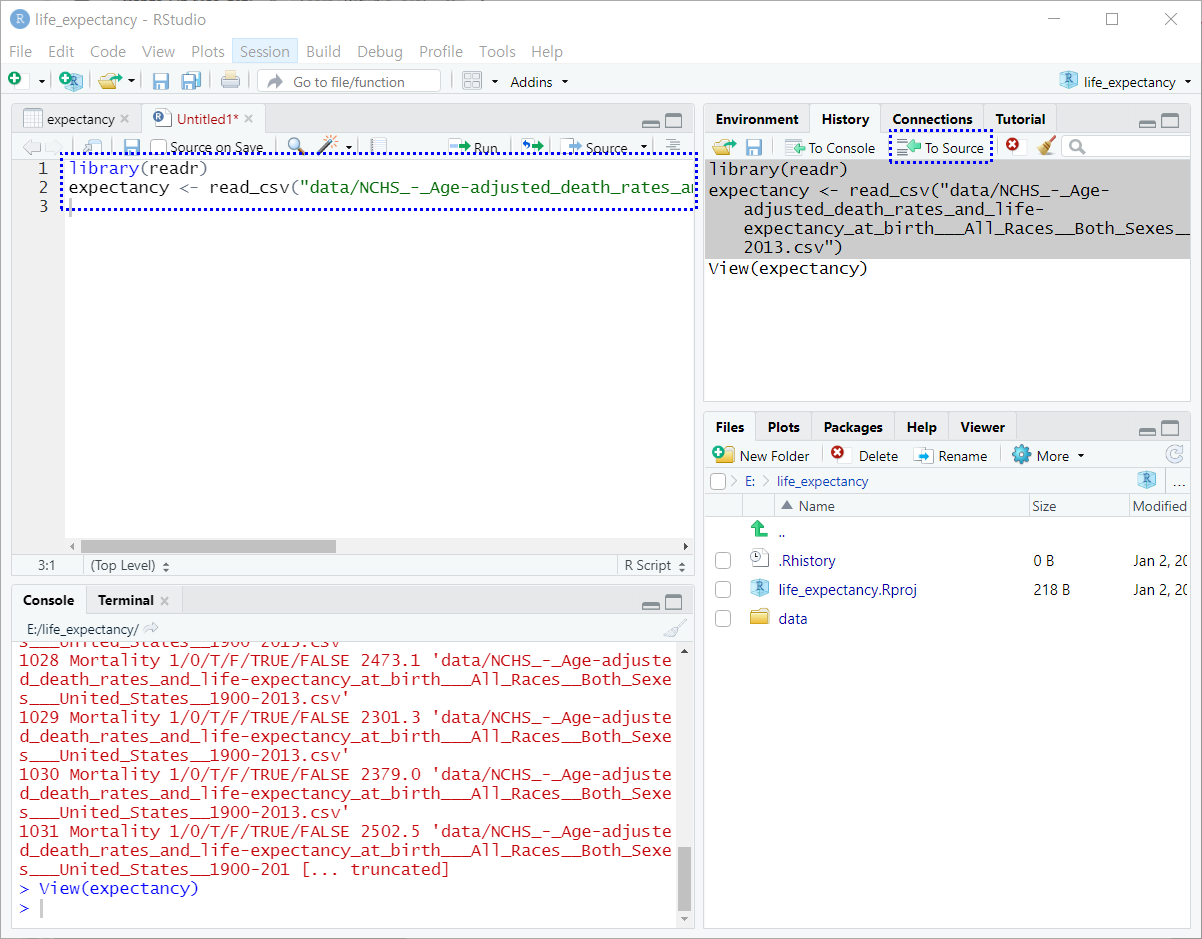
그림 5.8: 검색된 코드가 있는 R 스크립트 파일
이제 상단의 “Source” 버튼을 클릭하여 필요할 때마다 이 단계를 다시 실행할 수도 있다. 또한 이 프로젝트를 동료에게 보낼 수 있으며 그는 동일한 방식으로 작업을 재현할 수 있으므로 분석이 재현 가능한 상태로 유지된다.
계속 진행하기 전에 코드에 주석을 추가하고 나중에 작업하기 쉽도록 데이터 프레임을 정리해야 한다. 아래 코드는 이를 수행하는 방법의 한 예이다:
# Import NCHS Dataset
# File download from:
# https://catalog.data.gov
# Contains life expectancy data from 1900 in the US
library(readr)
expectancy <- read_csv("data/NCHS_-_Age-adjusted_death_rates_and_life-expectancy_at_birth___All_Races__Both_Sexes___United_States__1900-2013.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## Year = col_double(),
## Race = col_character(),
## Sex = col_character(),
## `Average Life Expectancy (Years)` = col_double(),
## `Age-adjusted Death Rate` = col_double()
## )# Clean up dataframe
# Use shorter column names
names(expectancy)[1] <- "year"
names(expectancy)[2] <- "race"
names(expectancy)[3] <- "sex"
names(expectancy)[4] <- "life_expectancy"
names(expectancy)[5] <- "death_rate"# 기호 다음은 주석 내용이고, R 코드의 마지막 5 줄은 열 이름을 작업하기 더 쉬운 짧은 이름으로 바꾸는 스크립트이다. 이 파일에 코드를 저장하려면 플로피 디스크 아이콘을 클릭하면 된다.