5.3 데이터 탐색
새 프로젝트를 시작할 때 할 수 있는 작업 중 하나는 탐색적 데이터 분석(Exploratory Data Analysis)을 수행하는 것이다. 데이터 세트를 미리 시각적으로 검사 할 수 있지만 더 완전한 그림을 작성하는 것이 좋을 것이니다. 또한 더 중요한 데이터 포인트를 시각화하기를 원할 수도 있다.
5.3.1 데이터 프레임 요약
RStudio 메뉴 표시 줄로 이동하여 “파일” ➤ “새 파일” ➤ “R 스크립트”를 선택하여 새로운 R 스크립트 파일을 생성해 보자. 앞에서와 마찬가지로 새 파일이 나타난다. 플로피 디스크 아이콘을 클릭하여이 파일을 “data_exploration.R”의 파일 이름으로 저장한다.
이제 우리는 expectancy 데이터 프레임의 요약을 확인하고자 한다. 그래서 우리는 summary() 함수의 인수로 데이터 프레임을 사용할 수 있다.
summary(expectancy)이 함수를 R 스크립트 파일에 바로 입력한 다음 “실행” 버튼을 클릭하여이 코드를 실행한다. 그러면 그림 5.9와 같이 각 변수 (또는 데이터 프레임의 열)를 설명하는 출력이 표시된다.
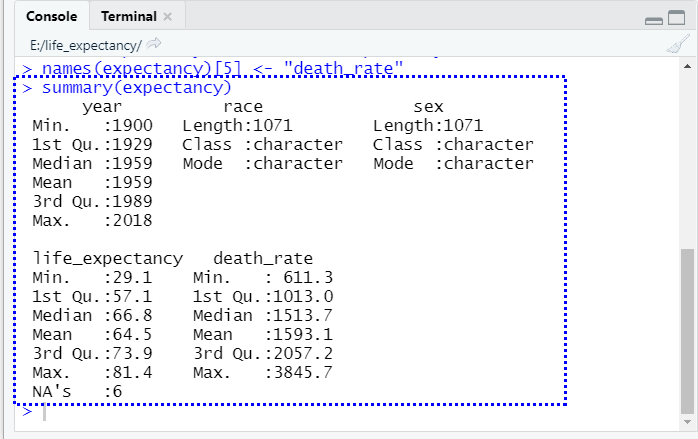
그림 5.9: 코드 편집 옵션
그림 5-9의 정보는이 데이터 세트에 대한 많은 것을 보여주고 있다. 각 열에 어떤 유형의 데이터가 포함되어 있는지 알 수 있으며, 숫자 데이터에 대한 정보가 있다. 예를 들어, 우리는 데이터 세트가 1900년에서 부터 2015 년까지를 포함하고, 어떤 연도의 기대수명은 29.10 년이고 다른 연도의 기대수명은 81.4 년이라는 것을 알 수 있다. 또한 인종과 성별의 두 가지 문자열 유형이 있음을 알 수 있지만 이에 대한 정보는 거의 없다. 이는 카테고리형 변수들로서, 이 데이터 세트가 어떻게 구성되어 있는지 보여주고 있다.
인종 및 성별의 범주를 보기 위해 R의 unique() 함수를 사용하고 다음과 같은 인수로 데이터 열을 전달할 수 있다.
unique(expectancy$race) ## [1] "All Races" "Black" "White"“실행” 버튼을 클릭하면, 그 결과는 다음과 같이 나타날 것이다:
## [1] "All Races" "Black" "White"성별의 범주에 대해 동일한 작업을 수행하면 “Both Sexes,” “Female” 그리고 “Male”의 세 가지 범주도 사용할 수 있음을 알 수 있다.
이 모든 것을 통해 데이터가 year(연도), race(인종) 그리고 sex(성별)의 세 가지 범주로 구성된다는 것을 알 수 있다. 또한 매년 가능한 모든 인종 및 성별 조합에 대한 행이 있을 것이다. 데이터 프레임 보기를 사용하여 이를 확인할 수 있다.
expectancy 데이터 프레임을 다시 보려면 프로젝트의 첫 번째 탭으로 이동한다. 데이터의 하위 집합을 보려면 필터(Filter) 버튼을 클릭한다. year(연도) 열의 슬라이더를 사용하여 그림 5.10에 표시된대로 1900 년으로 식별되는 행만 볼 수 있다.
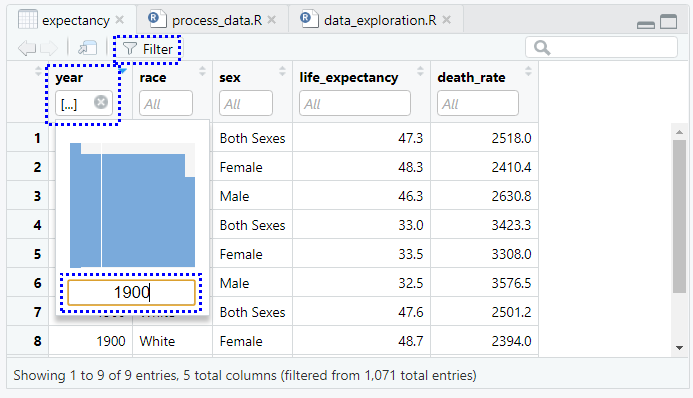
그림 5.10: 필터링된 데이터 프레임
우리는 데이터 프레임이 어떻게 구성되어 있는지 알고 있으므로 이 데이터 프레임을 처리하는 방법에 주의해야 한다. 예를 들어, 중복되는 범주가 포함되어 있으므로 연도별로 데이터 포인트를 단순히 집계하지 않고, 조사 질문을 개발할 때 이러한 범주를 필터링하고자 한다.
또한 우리가 보고 있는 숫자 변수에 대한 통찰력을 얻기 위해 기초적인 시각화를 수행할 수도 있다. 예를 들어 1900 년 이후로 기대 수명이 늘어 났을 것이라고 추측할 수 있다. 이 가설을 테스트하기 위해 race(인종)와 sex(성별) 범주 값이 “All Races”와 “Both Sexes”인 데이터 프레임의 행만 볼 수 있다.
trend <- expectancy
trend <- trend[trend$race == "All Races", ]
trend <- trend[trend$sex == "Both Sexes", ]먼저 trend라는 새 데이터 프레임에 expectancy 데이터 프레임을 할당한다. 그런 다음 데이터의 두 하위 집합을 가져온다. 두 번째 줄은 race(인종)이 “All Races”인 모든 행을 반환하고, 세 번째 줄은 sex(성별)이 “Both Sexes”인 모든 행을 반환한다. 다음으로, 특별히 살펴보게 될 변수에 대해 나머지 예상되는 값들은 모두 제거 할 수 있다.
trend$race <- NULL
trend$sex <- NULL
trend$death_rate <- NULLR에서 개체를 NULL로 설정하면 환경에서 개체가 제거된다. 이제 base R 플롯 함수를 사용하여 연도별 기대 수명을 플롯할 수 있다.
plot(trend)그러면 두 개의 변수가 자동으로 플롯되고 플롯 뷰어에는 그림 5.11과 같이 플롯이 표시된다.
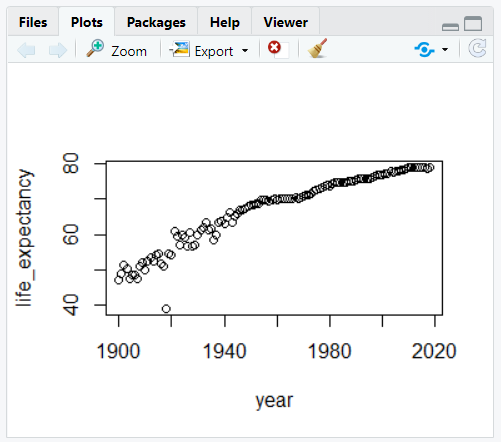
그림 5.11: 연도 별 기대 수명
보다시피 이 플롯은 기대 수명이 수년에 걸쳐 증가할 것이라는 처음의 추측을 뒷받침하고 있다. 이 플롯은 또한 초기 관측치가 후기 관측치만큼 일관성이 없음을 보여준다.