9.3 데이트-타임형 구성요소
날짜/시간 데이터를 R의 데이트-타임형 데이터 구조로 얻는 방법을 이제 알았으니 이를 이용해 할 수 있는 것을 탐색해보자. 이 절에서는 개별 구성요소를 얻고 설정하는 설정 함수(accessor function)에 초점을 맞출 것이다. 다음 절에서는 산술연산이 데이트-타임형에 어떻게 동작하는지 살펴 볼 것이다.
9.3.1 구성요소 가져오기
다음 설정 함수로 데이트형의 개별 부분을 가져올 수 있다. year(), month(), mday() (한 달에서 일), yday() (한 해에서 일), wday (한 주 중 일), hour(), minute(), second() .
datetime <- ymd_hms("2016-07-08 12:34:56")
year(datetime)## [1] 2016month(datetime)## [1] 7mday(datetime)## [1] 8yday(datetime)## [1] 190wday(datetime)## [1] 6month() 와 wday() 에서 label = TRUE 를 설정하여 월이나 일의 약식 이름을 반환할 수 있다. abbr = FALSE 를 설정하면 이름 전체를 반환할 수 있다.
month(datetime, label = TRUE)## [1] 7
## Levels: 1 < 2 < 3 < 4 < 5 < 6 < 7 < 8 < 9 < 10 < 11 < 12wday(datetime, label = TRUE, abbr = FALSE)## [1] 금요일
## Levels: 일요일 < 월요일 < 화요일 < 수요일 < 목요일 < 금요일 < 토요일wday() 를 사용하여 주말보다 평일에 출발하는 항공편이 더 많다는 것을 확인할 수 있다.
flights_dt %>%
mutate(wday = wday(dep_time, label = TRUE)) %>%
ggplot(aes(x = wday)) +
geom_bar()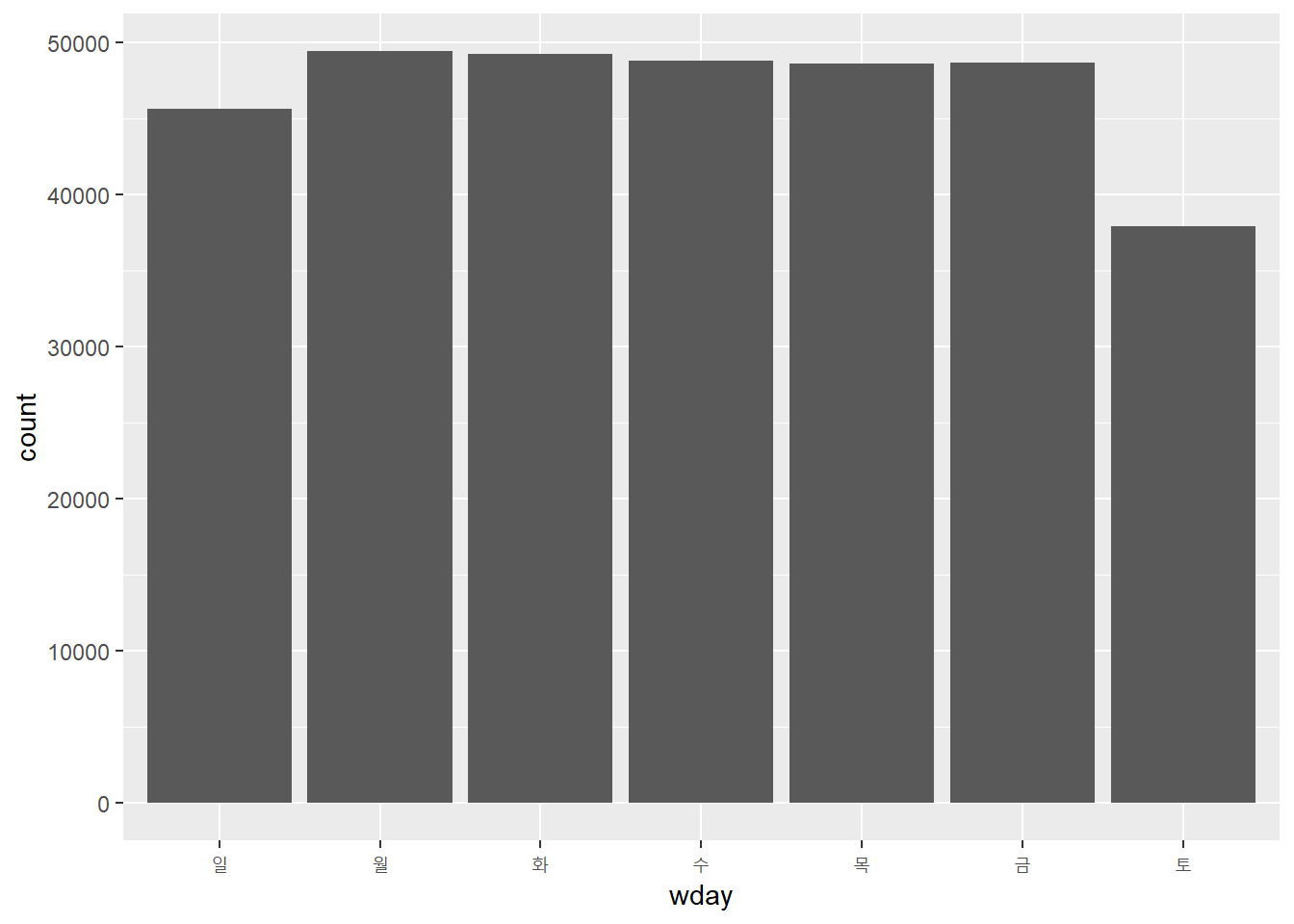
출발 지연시간 평균을 매 시의 각 분(0~59 분)에 대해서 살펴보면 흥미로운 패턴이 있다. 20~30분과 50~60분에 출발하는 항공편은 나머지 시간보다 훨씬 덜 지연되는 것으로 보인다.
flights_dt %>%
mutate(minute = minute(dep_time)) %>%
group_by(minute) %>%
summarise(
avg_delay = mean(arr_delay, na.rm = TRUE),
n = n()) %>%
ggplot(aes(minute, avg_delay)) +
geom_line()## `summarise()` ungrouping output (override with `.groups` argument)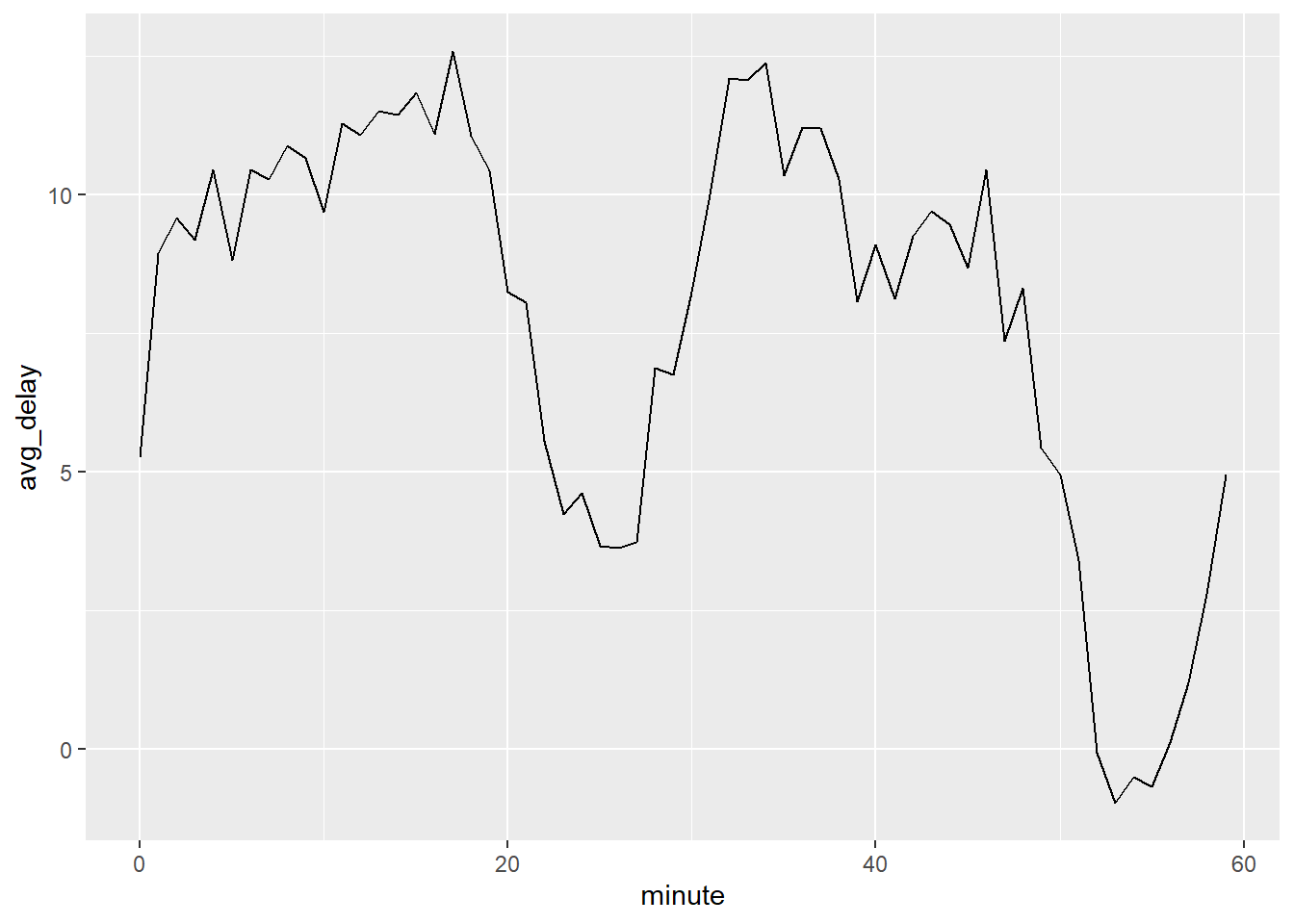
흥미롭게도 예정된 출발시간으로 보면 이러한 강한 패턴을 볼 수 없다.
sched_dep <- flights_dt %>%
mutate(minute = minute(sched_dep_time)) %>%
group_by(minute) %>%
summarise(
avg_delay = mean(arr_delay, na.rm = TRUE),
n = n())## `summarise()` ungrouping output (override with `.groups` argument)ggplot(sched_dep, aes(minute, avg_delay)) +
geom_line()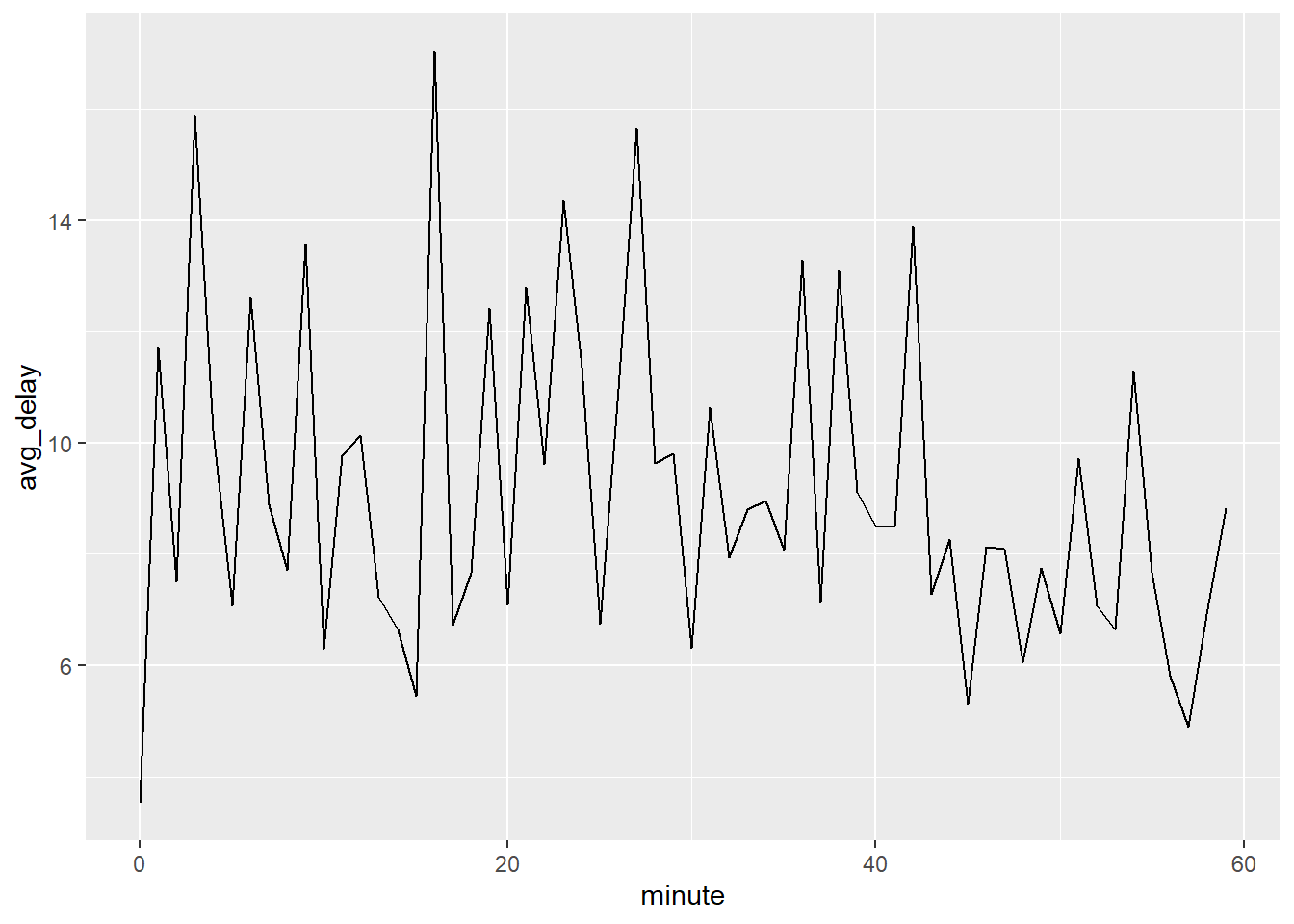
그러면 왜 실제 출발시간에는 그 패턴이 있는가? 사람에 의해 수집된 많은 데이터가 그런 것처럼, ’좋은‘ 출발시간에 떠나는 항공편 방향으로 편향(bias)이 강하게 존재한다. 인간의 판단이 관여된 데이터로 작업할 때마다 이런 종류의 패턴을 항상 유의해야 한다.
ggplot(sched_dep, aes(minute, n)) +
geom_line()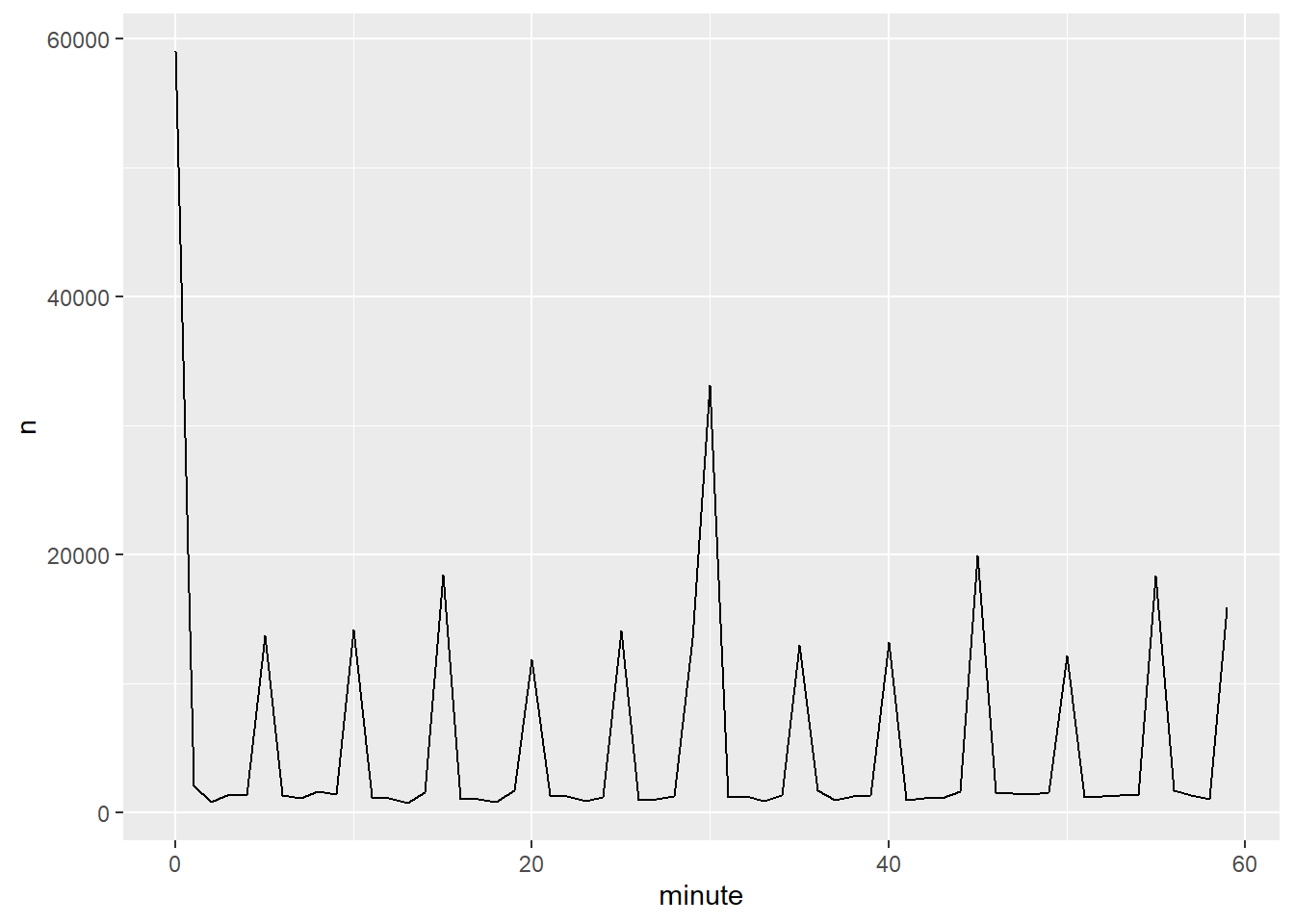
9.3.2 반올림
개별 구성요소를 플롯하는 또 다른 방법은 floor_date() , round_date() , ceiling_date() 로 인근 시간 단위로 날짜를 반올림하는 것이다. 각 ceiling_date() 함수의 입력값으로는, 조정할 날짜 벡터와, 내림(floor), 올림(ceiling), 혹은 반올림(round)해서 맞출 단위의 이름이다. 예를 들어 주당 항공편 수를 플롯할 수 있다.
flights_dt %>%
count(week = floor_date(dep_time, "week")) %>%
ggplot(aes(week, n)) +
geom_line()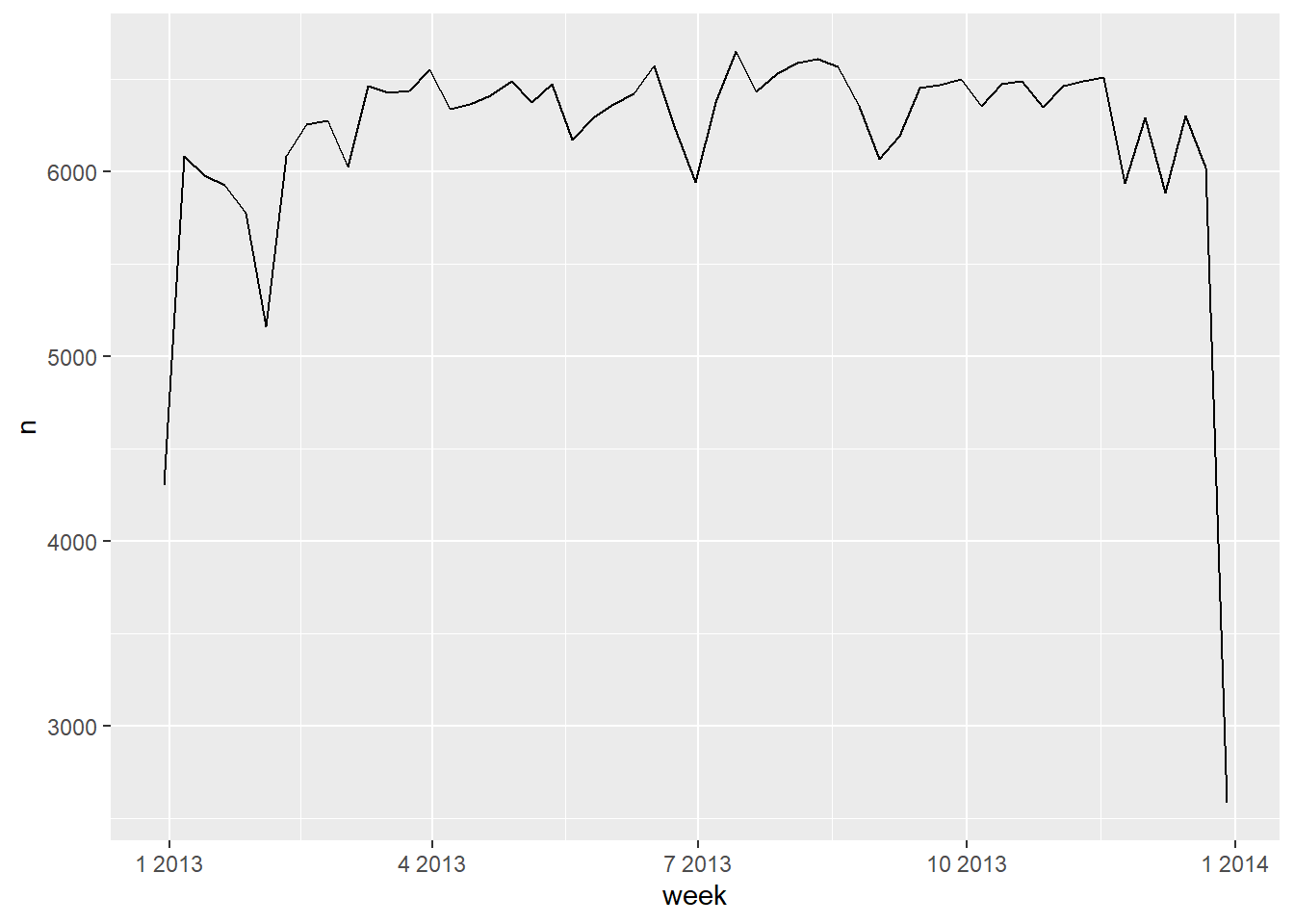
날짜 반올림 전후 차이를 계산하는 것은 특히 유용할 수 있다.
9.3.3 구성요소 설정
설정 함수를 사용하여 날짜/시간의 구성 요소를 설정할 수 있다.
(datetime <- ymd_hms("2016-07-08 12:34:56"))## [1] "2016-07-08 12:34:56 UTC"year(datetime) <- 2020
datetime## [1] "2020-07-08 12:34:56 UTC"month(datetime) <- 01
datetime## [1] "2020-01-08 12:34:56 UTC"hour(datetime) <- hour(datetime) + 1
datetime## [1] "2020-01-08 13:34:56 UTC"수정하는 대신, update() 로 새로운 데이트-타임형을 생성할 수도 있다. 이 방법을 사용하여 여러 개의 값을 한 번에 설정할 수도 있다.
update(datetime, year = 2020, month = 2, mday = 2, hour = 2)## [1] "2020-02-02 02:34:56 UTC"값이 너무 큰 경우에는 이월된다.
ymd("2015-02-01") %>%
update(mday = 30)## [1] "2015-03-02"ymd("2015-02-01") %>%
update(hour = 400)## [1] "2015-02-17 16:00:00 UTC"update() 를 사용하여 관심있는 해의 하루 동안 항공편의 분포를 볼 수 있다.
flights_dt %>%
mutate(dep_hour = update(dep_time, yday = 1)) %>%
ggplot(aes(dep_hour)) +
geom_freqpoly(binwidth = 300)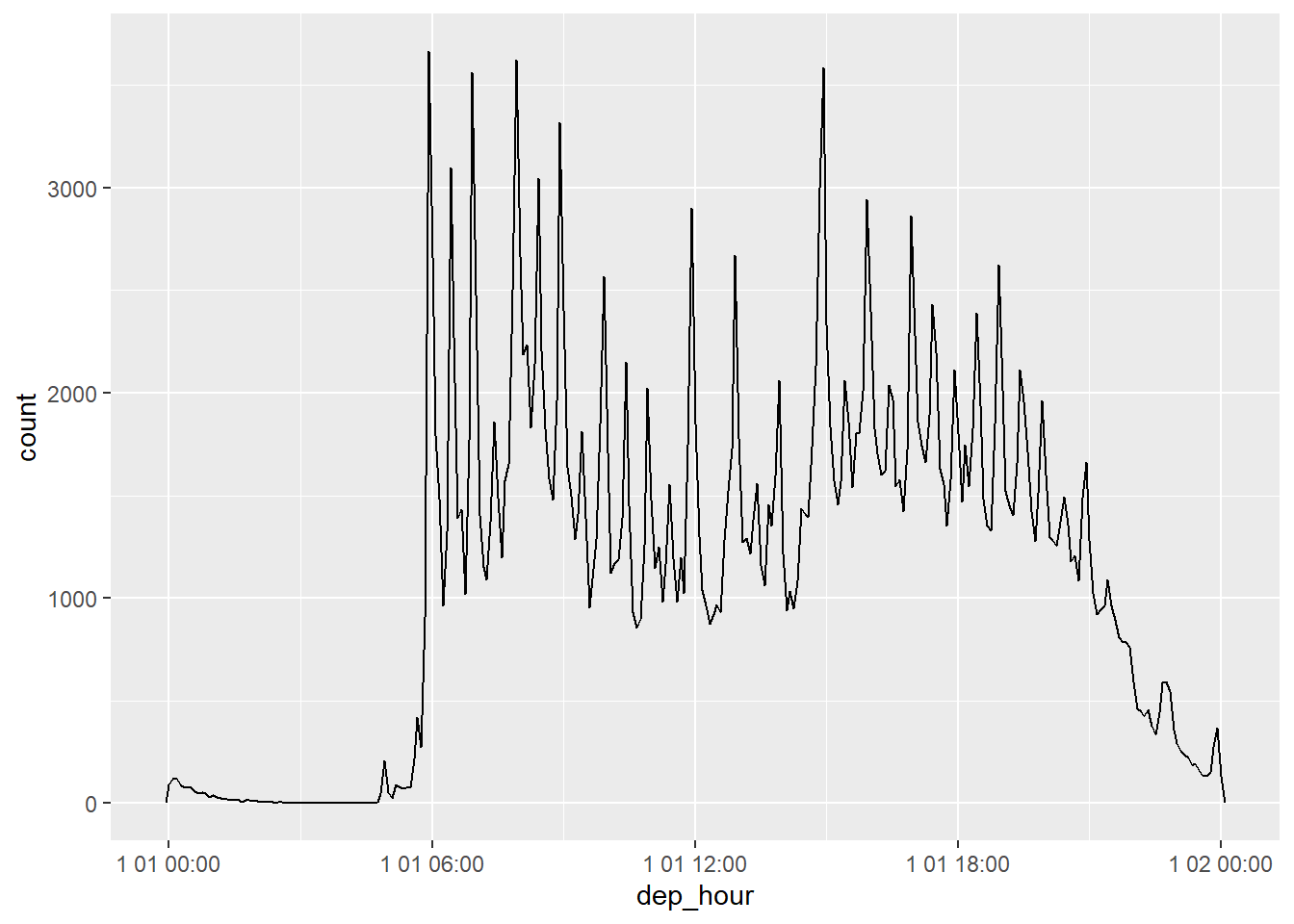
날짜의 상위 구성 요소를 상수로 설정하면, 하위 구성 요소의 패턴을 탐색할 수 있어서 매우 유용한 방법이다
9.3.4 연습문제
- 하루 동안 비행시간의 분포는 한 해 동안 어떻게 변화했는가?
dep_time, sched_dep_time, dep_delay를 비교하라. 이들은 일관성이 있는가? 무엇을 발견했는지 설명하라.- 출발, 도착 사이의 시간과
air_time을 비교하라. 무엇을 발견했는지 설명하라. (힌트: 공항의 위치를 살펴보라.) - 하루 동안 평균 지연시간은 어떻게 변화하는가?
dep_time또는sched_dep_time를 사용해야 하는가? 이유는 무엇인가? - 지연 가능성을 최소화하려면 한 주 중 어느 요일에 떠나야 하는가?
- 왜
diamonds$carat과flights$sched_dep_time분포가 비슷한가? - 20-30분과 50-60분에서 출발이 빠른 것은 일찍 출발하도록 계획된 항공편 때문이라는 우리의 가설을 확인하라. 힌트: 항공편이 지연되었는지 여부를 알려주는 이진 변수를 생성하라.