6.2 데이터 세트의 병합(Merge)
결합(append)은 관측치의 행들을 묶어주는데 반해, 병합(merge) 또는 조인(join)은 컬럼들을 묶어 준다.
병합될 데이터 세트들은 특정 키 변수(컬럼)럼)가 대응되어 있어야 한다.
예를 들어, 아래의 그림에서 두 개의 데이터 세트들은 docid 컬럼으로 대응되고 있다.
그러면 이 컬럼을 중심으로 두 개의 데이터 세트를 병합할 수 있다.
그 결과로 생성된 데이터 세트는 두 데이터 세트들의 컬럼을 모두 병합하고 대응하는 변수들을 공유하는 관측치들을 병합한다.
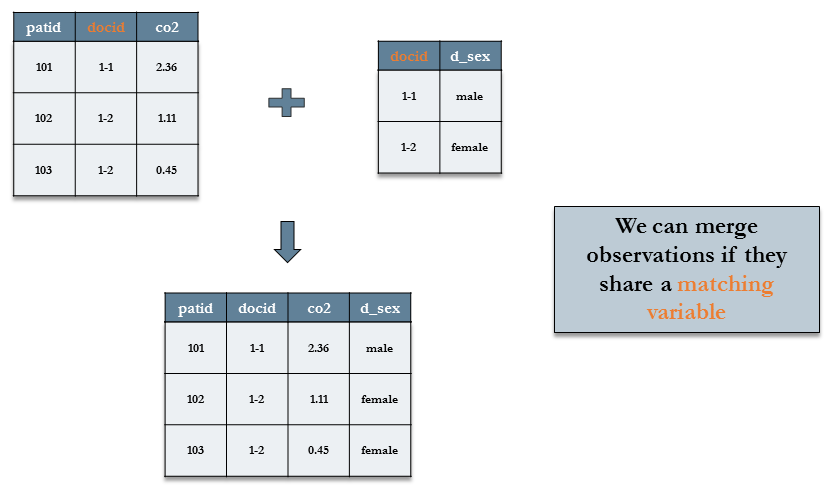
dplyr패키지의 “join()” 함수가 이러한 병합을 수행하며, 데이터 세트들 사이에 같은 이름을 갖는 변수(디폴트로는 id 변수)를 이용한다. 공통의 변수를 지정하기 위해서는 by= 인수를 사용한다.
이러한 조인은 데이터 세트 x와 y로 부터의 모든 컬럼을 갖는 테이블을 리턴하지만, 대응되지 않는 행들을 처리하는데에는 여러 가지 방법이 있다:
inner_join(x, y):y에 대응하는 값이 있다면x의 행(즉 대응하는 행만)을 리턴한다.left_join(x, y):x의 모든 행은 리턴하지만y와 대응하지 않는 행에 대해서는 NA를 리턴한다.y에 있는 대응하지 않는 행들은 리턴하지 않는다.full_join(x, y):x와y에 있는 모든 행들을 리턴한다. 그러나 양측에 대응하지 않는 행들은 새 컬럼의 값이 모두NA가 된다.
이러한 조인들은 base 패키지의 merge() 함수로도 가능하지만, join() 함수보다 그 처리 속도가 매우 느리다.
6.2.1 join 함수를 이용한 병합 예
병합의 예를 들기 위해 의사들에 관한 정보를 담고 있는 데이터 세트를 불러오기로 한다. 이 데이터 세트는 의사들의 근무기간, 학력 그리고 소송 횟수 등에 관한 정보를 담고 있다.
d_doc <- read_csv("data6/doctor_dm.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## docid = col_character(),
## experience = col_double(),
## school = col_character(),
## lawsuits = col_double(),
## medicaid = col_double()
## )6.2.1.1 예제 데이터 세트
병합이 어떻게 작동하는가를 이해하기 위해 데이터 세트로 작게 만들어서 작업을 하기로 한다.
지금 불러온 d_doc 데이터 세트의 일부와 앞에서 생성한 d3 데이터 세트의 일부를 병합해 보기로 한다.
먼저 d_doc의 경우는 docid 가 1-21과 2-178인 데이터를 서브세트로 선택한다.
그리고 d3의 경우는 d_doc과 대응이 되는 docid가 2-178인 행과 대응이 되지 않는 docid가 3-407인 행을 서브세트로 다음과 같이 선택한다.
# select one non-matching and one matching doctor from each to demo joins
# just a few variables from d3
d3.1 <- select(filter(d3, docid == "1-21" | docid == "2-178"),
docid, sex, age, test1, test2)
d3.1## # A tibble: 3 x 5
## docid sex age test1 test2
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 1-21 male 48.0 3.39 -99
## 2 2-178 male 34.2 4.63 3.26
## 3 2-178 male 48.9 4.15 3.04d_doc.1 <- filter(d_doc, docid == "3-407" | docid == "2-178")
d_doc.1## # A tibble: 2 x 5
## docid experience school lawsuits medicaid
## <chr> <dbl> <chr> <dbl> <dbl>
## 1 2-178 15 average 4 0.817
## 2 3-407 23 average 3 0.343이 결과를 그림으로 편집해 보면 다음과 같다.

병합된 공통의 변수의 id인 docid가 두 데이터 세트의 컬럼에 있다. 따라서 병합 변수를 새로이 지정할 필요는 없다.
6.2.1.2 병합의 예
inner_join(), left_join() 그리고 full_join() 함수를 이용하는 경우 각각의 결과가 다르게 나타나는 것을 잘 주목해 보자.
6.2.1.2.1 inner_join()
# only matching rows returned
# 2-178 from d_doc.1 matched twice to 2-178 in d3.1
inner_join(d3.1, d_doc.1)## Joining, by = "docid"## # A tibble: 2 x 9
## docid sex age test1 test2 experience school lawsuits medicaid
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 2-178 male 34.2 4.63 3.26 15 average 4 0.817
## 2 2-178 male 48.9 4.15 3.04 15 average 4 0.8176.2.1.2.2 left_join()
# all rows from d3.1 returned
left_join(d3.1, d_doc.1)## Joining, by = "docid"## # A tibble: 3 x 9
## docid sex age test1 test2 experience school lawsuits medicaid
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 1-21 male 48.0 3.39 -99 NA <NA> NA NA
## 2 2-178 male 34.2 4.63 3.26 15 average 4 0.817
## 3 2-178 male 48.9 4.15 3.04 15 average 4 0.8176.2.1.2.3 full_join()
# all rows from both returned
full_join(d3.1, d_doc.1)## Joining, by = "docid"## # A tibble: 4 x 9
## docid sex age test1 test2 experience school lawsuits medicaid
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 1-21 male 48.0 3.39 -99 NA <NA> NA NA
## 2 2-178 male 34.2 4.63 3.26 15 average 4 0.817
## 3 2-178 male 48.9 4.15 3.04 15 average 4 0.817
## 4 3-407 <NA> NA NA NA 23 average 3 0.343- 일반적으로 병합된 데이터 세트의 행의 갯수는 inner_join() <= left_join() <= full_join() 순이 된다.
이 밖에도 right_join(), semi_join()그리고 anti_join() 등의 함수가 있다.