6.3 Relational Data
6.3.1 들어가기
데이터 분석에서 데이터 테이블이 단 하나만 관련된 경우는 거의 없다. 일반적으로 데이터 테이블이 많이 있고, 관심 있는 질문에 대답하기 위해 이들을 결합해야 한다. 여러 데이터 테이블을 총칭하여 관계형 데이터 라고 한다. 이렇게 부르는 이유는 중요한 것이 개별 데이터셋이 아니라 이들의 관계(relationship)이기 때문이다.
관계라는 것은 항상 두 개의 테이블 사이에서 정의된다. 이 간단한 개념으로부터 다른 모든 관계가 구성된다. 테이블 3개 이상 사이의 관계는 항상 각 쌍 사이의 관계들을 이용하여 나타낼 수 있다. 때로는 쌍을 이루는 두 요소가 같은 테이블이 될 수도 있다! 예를 들어 사람에 대한 데이터 테이블을 가지고 있고, 각 사람이 부모에 대한 참조 정보를 가지고 있다면 이런 경우가 생긴다.
관계형 데이터로 작업하려면 두 개의 테이블에 작동하는 동사가 필요하다. 관계형 데이터에 동작하도록 설계된 세 가지 동사 계열이 있다.
- 변환 조인(Mutating Join) : 다른 데이터프레임에 있는 해당 관측값에서 가져와 새로운 변수로 생성하여 추가
- 필터링 조인 : 다른 테이블의 관측값와 일치하는지에 따라 관측값을 걸러냄
- 집합 연산 : 관측값을 집합 원소로 취급
관계형 데이터가 있는 가장 일반적인 장소는 관계형 데이터베이스 관리 시스템(RDBMS)이다. 이 용어는 거의 모든 현대의 데이터베이스를 포괄한다. 여러분이 이전에 데이터베이스를 사용했다면 SQL을 사용했을 것이 거의 확실하다. 그렇다면 dplyr 에서의 표현이 조금 다르긴 하지만, 이 장에 나오는 개념이 익숙할 것이다. 일반적으로 dplyr 은 SQL보다 약간 사용하기 쉽다. dplyr 은 데이터 분석에 특화되었기 때문이다. 즉, 일반적인 데이터 분석 작업을 하기는 더 쉽게 만들었지만, 대신 데이터 분석에서 일반적으로 필요하지 않은 작업을 수행하기는 더 어렵게 되었다.
6.3.2 준비하기
우리는 dplyr 의 2-테이블 동사를 사용하여 nycflights13 패키지에 있는 관계형 데이터를 탐색할 것이다.
library(nycflights13)6.3.3 nycflights13 패키지 내의 데이터 세트
관계형 데이터에 대해 배우기 위해 nycflights13 패키지를 사용할 것이다. nycflights13 패키지에는 flights 테이블과 관련된 4개의 티블(tibble)이 있다.
airlines를 사용하면 해당 약어 코드로 전체 항공사명을 찾아볼 수 있다.airlines## # A tibble: 16 x 2 ## carrier name ## <chr> <chr> ## 1 9E Endeavor Air Inc. ## 2 AA American Airlines Inc. ## 3 AS Alaska Airlines Inc. ## # ... with 13 more rowsairports에는 각 공항에 대한 정보가faa공항 코드로 식별되어 있다.airports## # A tibble: 1,458 x 8 ## faa name lat lon alt tz dst tzone ## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> ## 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/New_Y~ ## 2 06A Moton Field Municipal Airp~ 32.5 -85.7 264 -6 A America/Chica~ ## 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/Chica~ ## # ... with 1,455 more rowsplanes에는 각 여객기에 대한 정보가tailnum으로 식별되어 있다.planes## # A tibble: 3,322 x 9 ## tailnum year type manufacturer model engines seats speed engine ## <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr> ## 1 N10156 2004 Fixed wing mu~ EMBRAER EMB-1~ 2 55 NA Turbo-~ ## 2 N102UW 1998 Fixed wing mu~ AIRBUS INDUST~ A320-~ 2 182 NA Turbo-~ ## 3 N103US 1999 Fixed wing mu~ AIRBUS INDUST~ A320-~ 2 182 NA Turbo-~ ## # ... with 3,319 more rowsweather에는 각 NYC 공항의 매 시각 날씨 정보가 있다.weather## # A tibble: 26,115 x 15 ## origin year month day hour temp dewp humid wind_dir wind_speed wind_gust ## <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA ## 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA ## 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA ## # ... with 26,112 more rows, and 4 more variables: precip <dbl>, ## # pressure <dbl>, visib <dbl>, time_hour <dttm>
그림을 사용하여 테이블 간의 관계를 볼 수 있다.
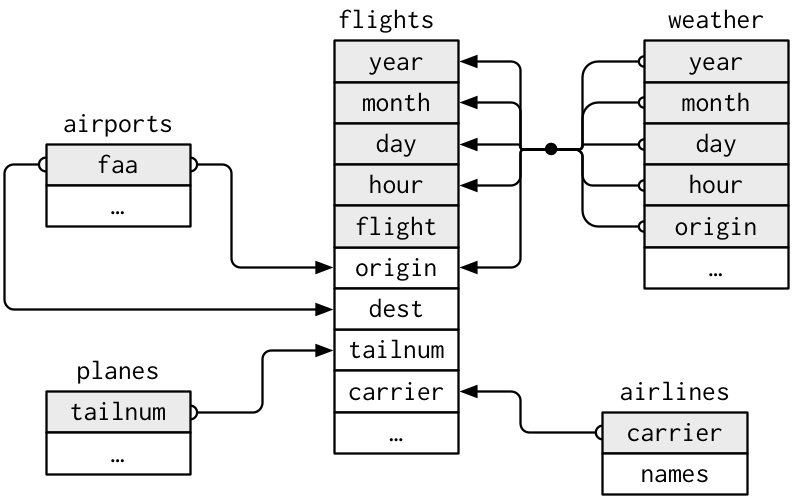
이 다이어그램은 꽤 복잡해 보이지만, 실전에서 보게 될 것과 비교하면 간단한 것이다! 이와 같은 다이어그램을 이해하는 데 핵심은 각 관계가 항상 한 쌍의 테이블과 관련되어 있음을 기억하는 것이다. 여러분은 모든 것을 이해할 필요는 없다. 관심 있는 테이블 사이의 연쇄적인 관계를 이해하면 된다.
nycflights13 에서
flights는 단 하나의 변수인tailnum을 통해planes에 연결된다.flights는carrier변수를 통해airlines에 연결된다.flights는origin(출발지) 및dest(목적지) 변수를 통해 두 가지 방법으로airports에 연결된다.flgiths는origin(위치),year, month, day, hour(시간)를 통해weather에 연결된다.flights: 항공편,planes: 여객기,airlines: 항공사,airports: 공항,weather: 날씨
6.3.4 연습문제
- 각 여객기가 출발지에서 목적지까지 날아가는 경로를 대략 그려보고 싶다고 상상해보라. 어떤 변수가 필요한가? 어떤 테이블을 결합해야 하는가?
- 우리는 앞에서
weather와airports사이의 관계를 그리는 것을 잊어버렸다. 어떻게 관계되며, 다이어그램을 이용하여 어떻게 그려야 하는가? weather는 출발지 (NYC) 공항에 대한 정보만 포함한다. 미국의 모든 공항에 대한 날씨 기록이 포함되어 있다면flights와 어떤 관계가 추가되는가?- 우리는 일 년 중 어떤 날이 ‘특별하다’는 것을 알고 있으며, 이 날에는 평소보다 적은 수의 사람들이 항공여행을 한다는 것을 알고 있다. 이 데이터를 데이터프레임으로 어떻게 표현하겠는가? 이 테이블의 기본키는 무엇이겠는가? 기존 테이블에 어떻게 연결되는가?
6.3.5 키(Key)
각 테이블 쌍을 연결하는 데 사용되는 변수를 키라고 한다. 키는 관측값을 고유하게 식별하는 변수 (또는 변수 집합)이다. 간단한 경우 단일 변수만으로 관측값을 식별할 수 있다. 예를 들어, 각 여객기(`planes)는 tailnum 으로 고유하게 식별된다. 어떤 경우에는 여러 변수가 필요할 수 있다. 예를 들어 weather 의 관측값을 식별하려면 year, month, day, hour, origin 의 다섯 개의 변수가 필요하다. (위의 그림에서 5개의 데이터 세트에 대해 각각의 속성을 표시하고 있으며, 그 중 진한 색깔의 속성이 키이다.)
키에는 두 가지 유형의 키가 있다.
- 기본키(주키, primary key) 는 자신의 테이블에서 관측값을 고유하게 식별한다. 예를 들어,
planes$tailnum은planes테이블의 각 여객기를 고유하게 식별하므로 기본키이다. - 외래키(외부키, foreigh key) 는 다른 테이블의 관측값을 고유하게 식별한다. 예를 들어,
flight$tailnum은flights테이블에서 각 항공편(flights)을 고유한 여객기(planes)와 매칭시키기 때문에 외래키이다. (flights테이블의tailnum컬럼은 상대 테이블인planes테이블의 기본키이다.)
한 변수가 동시에 기본키이며 외래키일 수 있다(이런 경우의 키를 교차참조키라 한다). 예를 들어, 출발지(origin) 컬럼은 weather 테이블의 기본키의 일부이며, flights 테이블의 외래키이기도 하다.
테이블에서 기본키를 확인한 후에는 실제로 기본키가 각 관측값을 고유하게 식별하는지 확인하는 것이 좋다. 이를 수행하는 한 가지 방법은 기본키를 count() 하고 n 이 1보다 큰 항목을 찾는 것이다.
planes %>%
count(tailnum) %>%
filter(n > 1)## # A tibble: 0 x 2
## # ... with 2 variables: tailnum <chr>, n <int>planes테이블의 경우tailnum이 기본키로서 각 관측값을 고유하게(unique, 유일하게) 식별하고 있다.
weather %>%
count(year, month, day, hour, origin) %>%
filter(n > 1)## # A tibble: 3 x 6
## year month day hour origin n
## <int> <int> <int> <int> <chr> <int>
## 1 2013 11 3 1 EWR 2
## 2 2013 11 3 1 JFK 2
## 3 2013 11 3 1 LGA 2- 반면에
weather테이블의 경우,year,month,day,hour,orgin등의 5개의 변수를 동시에 고려한 경우(이를 합성키라고 함) 중복값이 3개 나옴을 알 수 있다. 즉, 이 5개의 변수를 합성하여 기본키로 사용할 수 없음을 의미한다.
때로 테이블에 명시적인 기본키가 없는 경우가 있다. 모든 행은 관측값이지만 어떤 변수를 조합해도 각 행을 신뢰성있게 구분하지 못하는 경우이다. 예를 들어, flight 테이블의 기본키는 무엇인가? 여러분은 date 에 flight 혹은 tailnum 을 더한 것으로 생각하겠지만 이들 중 어느 것도 고유하지 않다.
flights %>%
count(year, month, day, flight) %>%
filter(n > 1)## # A tibble: 29,768 x 5
## year month day flight n
## <int> <int> <int> <int> <int>
## 1 2013 1 1 1 2
## 2 2013 1 1 3 2
## 3 2013 1 1 4 2
## # ... with 29,765 more rowsflights테이블의 경우,year,month,day,flight등의 4개의 변수를 동시에 고려한 경우에도 많은 중복값들이 나옴을 알 수 있다. 즉, 이 4개의 변수를 합성하여 기본키로 사용할 수 없음을 의미한다.
flights %>%
count(year, month, day, tailnum) %>%
filter(n > 1)## # A tibble: 64,928 x 5
## year month day tailnum n
## <int> <int> <int> <chr> <int>
## 1 2013 1 1 N0EGMQ 2
## 2 2013 1 1 N11189 2
## 3 2013 1 1 N11536 2
## # ... with 64,925 more rows- 이 데이터로 작업을 시작할 때 나는 각 항공편 번호(
flight)가 하루에 한 번만 사용된다고 순진하게 추측했다. 그런 경우라면 특정 항공편(flight)의 문제에 대해 훨씬 쉽게 의사 소통할 수 있었을 것이었다. 불행히도 그것은 사실이 아니다!
테이블에 기본키가 없으면 mutate() 와 row_number() 를 이용하여 기본키를 추가해 보라. 이렇게 하면 필터링을 수행하고 난 후 원래 데이터와 다시 점검할 때 관측값을 쉽게 일치시킬 수 있다. 이를 대체키(surrogate key) 라고 한다.
기본키와 이와 대응되는 다른 테이블의 외래키는 관계(relationship) 를 형성한다.
- 관계는 대개 일대다 관계(one-to-many)이다. 예를 들어, 각 항공편에는 여객기가 하나 있지만, 각 여객기에는 여러 항공편이 있다.
- 다른 데이터에서는 가끔 일대일 관계를 보게 된다. 이것을 일대다 관계의 특별한 경우라고 생각할 수 있다.
- 다대일(many-to-one) 관계와 일대다 관계를 사용하여 다대다(many-to-many) 관계를 모델링할 수 있다. 예를 들어 이 데이터에는 항공사(
airline)와 공항(airport) 간 다대다 관계가 있다. 즉, 각 항공사는 많은 공항으로 운항하고, 각 공항에는 많은 항공사가 있다.
6.3.6 연습문제
flights에 대체키를 추가하라.다음 데이터 세트의 (기본)키를 식별하라.
Lahman::Battingbabynames::babynamesnasaweather::atmosfueleconomy::vehiclesggplot2::diamonds
(이를 위해 패키지를 설치하고 설명서를 읽어야 할 수도 있다.)
Lahman패키지의Batting, Master, Salaries테이블 간의 연결을 나타내는 다이어그램을 그려라.Master, Managers, AwardsManagers사이의 관계를 보여주는 또 다른 다이어그램을 그려라.Batting, Pitching, Fielding테이블 간의 관계를 어떻게 규정하겠는가?