6.7 집합 연산
2 테이블 동사의 마지막 유형은 집합 연산이다. 일반적으로 이 필터는 가장 드물게 사용하지만, 복잡한 필터를 단순한 필터들로 분해하려는 경우에 가끔 유용하다. 이 모든 연산은 행 전체에 동작하는데 모든 변수의 값을 비교한다. 이 집합 연산은 x 와 y 입력이 같은 변수를 가지는 것을 간주하며 관측값을 집합으로 취급한다.
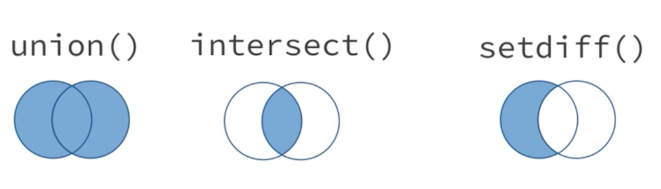
intersect(x, y):x, y모두에 있는 관측값만 반환union(x, y):x와y의 고유한 관측값을 반환. (중복값은 제외)setdiff(x, y):x에 있지만,y에 없는 관측값을 반환
아래의 간단한 데이터에 대해서,
df1 <- tribble(
~x, ~y,
1, 1,
2, 1
)
df2 <- tribble(
~x, ~y,
1, 1,
1, 2
)네 가지 연산은 다음과 같다.
intersect(df1, df2)## # A tibble: 1 x 2
## x y
## <dbl> <dbl>
## 1 1 1# 열이 4개가 아니라 3개임을 주목
union(df1, df2)## # A tibble: 3 x 2
## x y
## <dbl> <dbl>
## 1 1 1
## 2 2 1
## 3 1 2setdiff(df1, df2)## # A tibble: 1 x 2
## x y
## <dbl> <dbl>
## 1 2 1setdiff(df2, df1)## # A tibble: 1 x 2
## x y
## <dbl> <dbl>
## 1 1 2union_all(x, y, ...):x와y에 있는 모든 행들을 결합. (결합된 데이터 세트의 중복 행을 제거하지 않음.)setequal(x, y, ...):x와y의 행이 같은 지 비교.
union_all(df1, df2)## # A tibble: 4 x 2
## x y
## <dbl> <dbl>
## 1 1 1
## 2 2 1
## 3 1 1
## 4 1 2setequal(df1, df2)## [1] FALSE