6.8 Join Exercises
이번 장에서는 dplyr 패키지를 이용한 데이터의 병합과 관련하여 사용할 수 있는 다음의 함수들에 대하여 살펴보기로 한다:
- inner_join()
- left_join()
- right_join()
- full_join()
- semi_join()
- anti_join()
- nest_join()
먼저 이 함수들의 기본 개념과 (간단한 예를 들어) 차이점들에 대하여 살펴볼 것이다.
그런 다음 좀 더 복잡한 예제들을 살펴보기로 한다:
6.8.1 예제 데이터의 생성
먼저 예제에 사용될 예제 데이터 프레임들을 생성해 보기로 한다.
data1 <- data.frame(ID = 1:2, # Create first example data frame
X1 = c("a1", "a2"),
stringsAsFactors = FALSE)
data1## ID X1
## 1 1 a1
## 2 2 a2data2 <- data.frame(ID = 2:3, # Create second example data frame
X2 = c("b1", "b2"),
stringsAsFactors = FALSE)
data2## ID X2
## 1 2 b1
## 2 3 b2다음의 그림은 지금 생성한 두 개의 데이터 프레임과 dplyr 패키지의 다양한 조인 함수를 이용하여 이들 데이터 프레임을 병합하는 방법을 보여주고 있다.
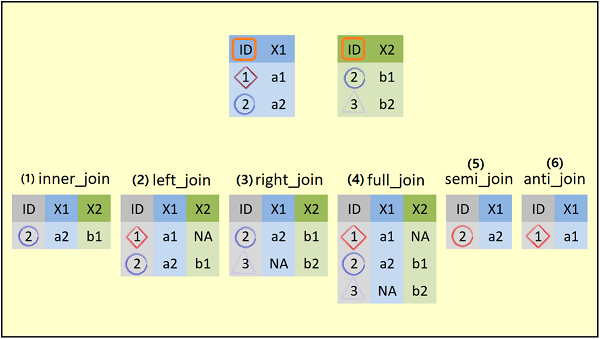
그림의 제일 위에 예제 데이터 프레임의 구조를 보여주고 있다. 각 데이터 프레임은 두 개의 컬럼을 가지고 있다.
data1은ID와X1컬럼을, 그리고data2는ID와X2컬럼을 가지고 있다.ID컬럼은 두 데이터 프레임의 공통 컬럼이며, 또한 공통의 값인2를 가지고 있다.- ~ (6) : 두 데이터 프레임을 조인하는 방법에 따라 결과로 생성되는 데이터 프레임을 보여주고 있다. 이들 각각에 대하여 예를 들어 살펴보기로 한다.
6.8.2 예제 1: inner_join()
먼저 dplyr 패키지를 설치하여 불러오기를 해야 한다:
install.packages("dplyr") # Install dplyr package ## Warning: package 'dplyr' is in use and will not be installedlibrary("dplyr") # Load dplyr package이 예제에서는 예제 데이터 프레임의 inner_join() 함수에 대하여 살펴보기로 한다.
6.8.2.1 inner_join() 함수의 기본 형식
inner_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
na_matches = c("na", "never")
) 6.8.2.2 inner_join() 함수의 예
inner_join 방식으로 데이터 프레임을 병합하기 위해서는, 병합할 두 개의 데이터 프레임의 이름들(data1과 data2)과 병합에 사용될 공통의 컬럼(여기서는 ID 컬럼)을 inner_join() 함수의 인수(by = ”ID”)로 지정해 주면 된다.
inner_join(data1, data2, by = "ID") # Apply inner_join dplyr function## ID X1 X2
## 1 2 a2 b1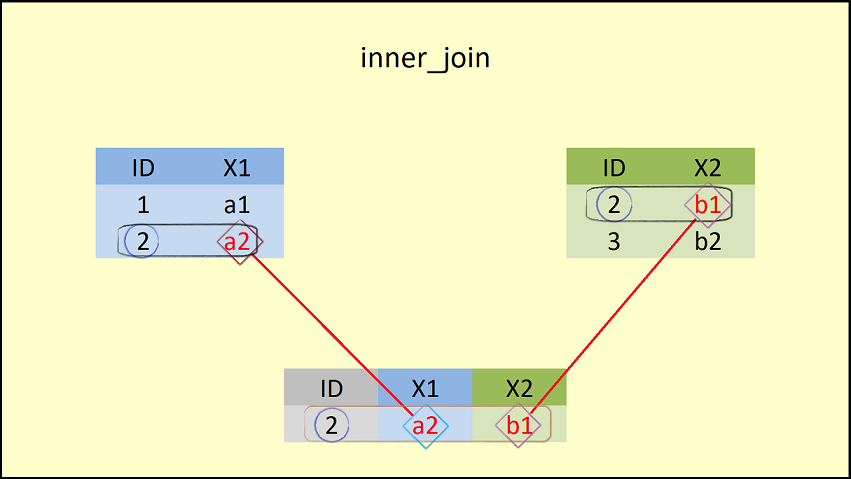
- 이 그림은 inner_join의 결과를 보여준다. 이 그림에서 볼 수 있듯이,
inner_join()함수는 두 개의 데이터 프레임의 컬럼들을 병합하지만, 공통의 컬럼인ID에 대해 같은 값을 갖는 행만(ID = 2)을 병합한다.
6.8.3 예제 2: left_join()
6.8.3.1 left_join() 함수의 기본 형식
left_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE
)6.8.3.2 left_join() 함수의 예
left_join(data1, data2, by = "ID") # Apply left_join dplyr function## ID X1 X2
## 1 1 a1 <NA>
## 2 2 a2 b1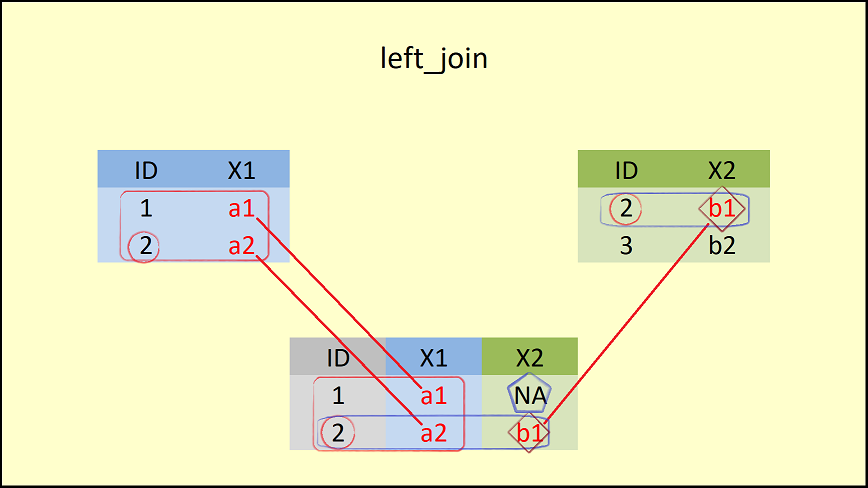
- inner_join과의 차이는 left_join은
left_join()함수에 첫 번째로 입력된(left) 데이터 프레임(data1)의 모든 행들을 포함하고 있다.
- 이때 결과로 생성되는 데이터 프레임의
ID = 1에 해당하는 행의X2컬럼에는NA로 채워진다.
6.8.4 예제 3: right_join()
left_join() 함수의 상대적 함수가 right_join() 함수이다.
6.8.4.1 right_join() 함수의 기본 형식
이 함수의 기본 형식은 다음과 같다:
right_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE
)6.8.4.2 right_join() 함수의 예
right_join(data1, data2, by = "ID") # Apply right_join dplyr function## ID X1 X2
## 1 2 a2 b1
## 2 3 <NA> b2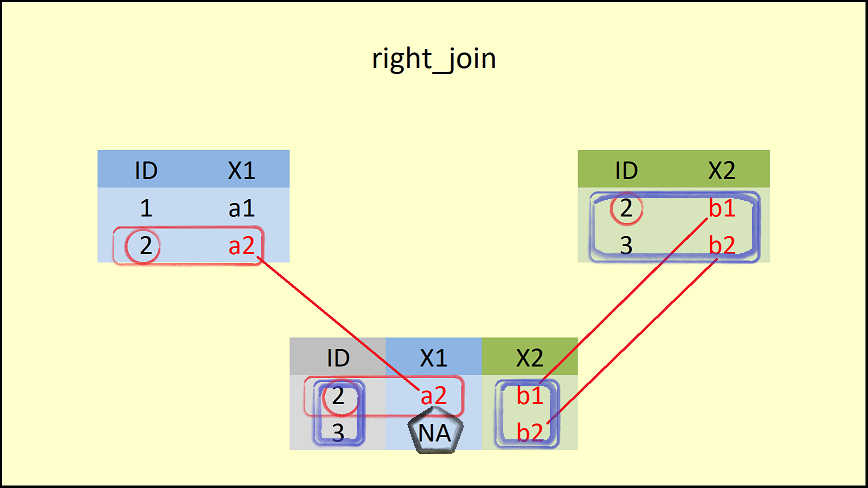
right_join()함수에 두 번째로 입력된(right) 데이터 프레임(data2)의 모든 행들을 포함하고 있다.이때 결과로 생성되는 데이터 프레임의
ID = 3에 해당하는 행의X1컬럼에는NA로 채워진다.
6.8.5 예제 4: full_join()
6.8.5.1 full_join() 함수의 기본 형식
full_join() 함수는 join() 함수 중에서 가장 많은 데이터를 유지한다.
이 함수의 기본 형식은 다음과 같다:
full_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE
)6.8.5.2 full_join() 함수의 예
full_join(data1, data2, by = "ID") # Apply full_join dplyr function## ID X1 X2
## 1 1 a1 <NA>
## 2 2 a2 b1
## 3 3 <NA> b2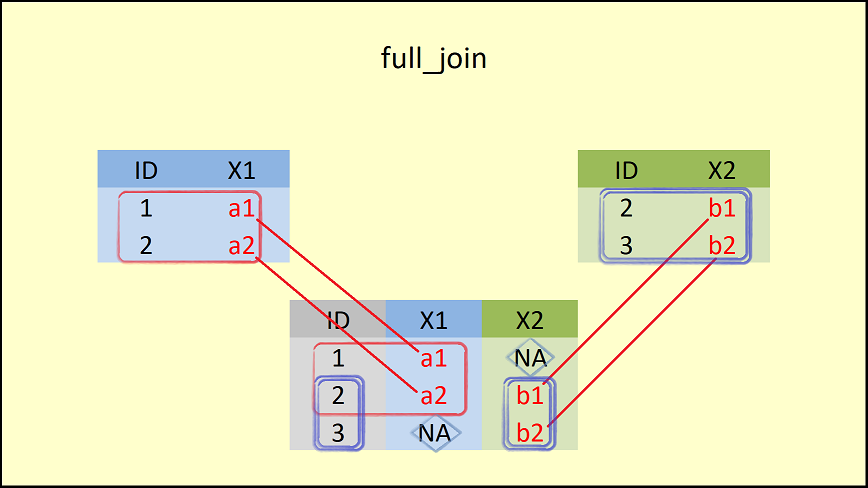
full_join()함수는 두 데이터 프레임(data1과data2`)의 모든 행들을 포함하고 있다.
- 이때 결과로 생성되는 데이터 프레임의
ID = 1에 해당하는 행의X2컬럼과ID=3에 해당하는 행의X1컬럼은NA로 채워진다.
6.8.6 예제 5: semi_join()
앞의 4개의 join 함수들(inner_join(), left_join(), right_join(), 그리고 full_join())은 변환 조인(mutating joins)이라고도 불린다. 변환 조인은 두 데이터 소스의 변수(컬럼)들을 결합한다.
다음의 두 개의 join 함수들(semi_join()과 anti_join())은 필터링 조인(filtering joins)이라고 불린다. 필터링 조인은 왼쪽 데이터(x)의 모든 경우를 유지하며, 오른 쪽 데이터(y)를 필터로 사용한다.
6.8.6.1 semi_join() 함수의 기본 형식
이 함수의 기본 형식은 다음과 같다:
semi_join(x, y, by = NULL, copy = FALSE, ..., na_matches = c("na", "never"))6.8.6.2 semi_join() 함수의 예
semi_join(data1, data2, by = "ID") # Apply semi_join dplyr function## ID X1
## 1 2 a2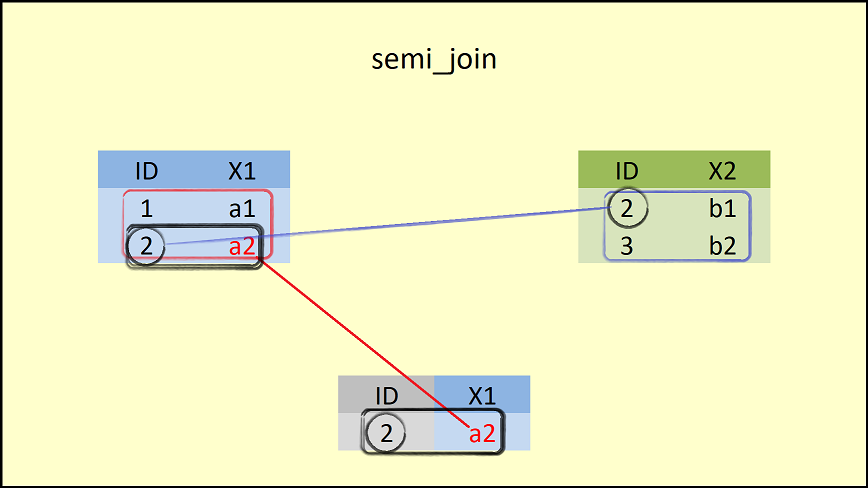
semi_join()함수는 왼쪽의 데이터 프레임(data1)에 대하여 오른 쪽 데이터 프레임(data2)에 있는 공통 컬럼인 ID 값과 비교하여 대응이 되는 행만을 유지한다.- 이 때, 결과로 생성되는 데이터 프레임의 구조는 왼쪽 데이터 프레임의 구조와 같다.
6.8.7 예제 6 : anti_join()
6.8.7.1 anti_join() 함수의 기본 형식
anti_join() 함수는 앞에서 살펴 본 semi_join() 함수의 결과의 반대이다.
이 함수의 기본 형식은 다음과 같다:
semi_join(x, y, by = NULL, copy = FALSE, ..., na_matches = c("na", "never"))6.8.7.2 anti_join() 함수의 예
anti_join(data1, data2, by = "ID") # Apply anti_join dplyr function## ID X1
## 1 1 a1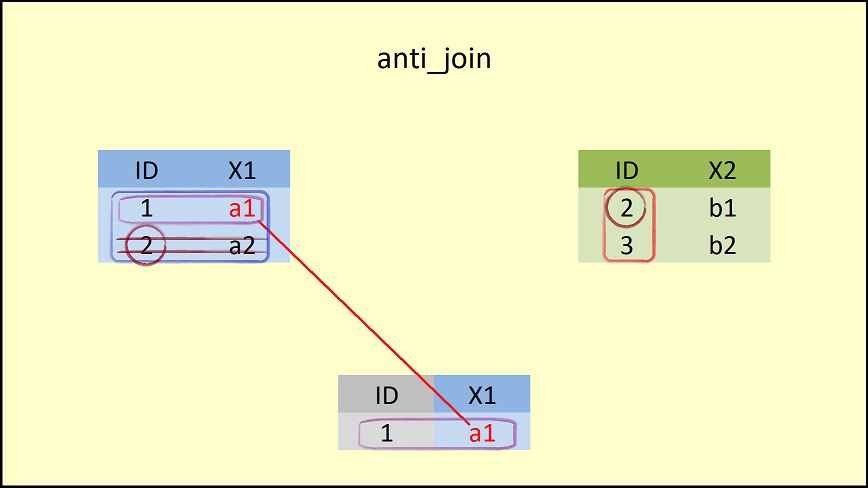
anti_join()함수는 왼쪽의 데이터 프레임(data1)에 대하여 오른 쪽 데이터 프레임(data2)에 있는 공통 컬럼인 ID 값과 비교하여 대응이 되지 않는 행만을 유지한다.- 이 때, 결과로 생성되는 데이터 프레임의 구조는 왼쪽 데이터 프레임의 구조와 같다.
지금까지 dplyr 패키지의 6 개 join 함수들의 기본 개념에 대하여 살펴 보았다. 그러나, 실제에 있어서는 지금까지 살펴 본 예제보다는 훨씬 더 복잡하다. 다음에서 좀 더 복잡한 상황에서 join 함수를 어떻게 적용할 수 있는지 살펴보기로 한다.
6.8.8 예제 7: 복수 개의 데이터 프레임 조인
좀 더 복잡한 상황을 만들기 위해 세 번째 데이터 프레임 예제 데이터를 생성한다:
6.8.8.1 예제 데이터의 생성
data3 <- data.frame(ID = c(2, 4), # Create third example data frame
X2 = c("c1", "c2"),
X3 = c("d1", "d2"),
stringsAsFactors = FALSE)
data3 # Print data to RStudio console ## ID X2 X3
## 1 2 c1 d1
## 2 4 c2 d2
- 세 번째 데이터 프레임인
data3은ID,X2,X3등의 컬럼을 가지고 있다. 이 컬럼들 중X2컬럼은data2에도 존재하고 있음을 주목하기 바란다.
이번 예제에서는 복수 개의 데이터 프레임들을 하나의 데이터 세트로 병합하는 방법에 대하여 살펴보기로 한다. 여기서는 full_join() 함수를 사용하겠지만, 다른 종류의 join 함수들도 같은 방법으로 이용할 수 있다.
full_join(data1, data2, by = "ID") %>% # Full outer join of multiple data frames
full_join(., data3, by = "ID")## ID X1 X2.x X2.y X3
## 1 1 a1 <NA> <NA> <NA>
## 2 2 a2 b1 c1 d1
## 3 3 <NA> b2 <NA> <NA>
## 4 4 <NA> <NA> c2 d2
full_join(data1, data2, by = "ID")먼저
data1과data2를 공통 컬럼인ID를 기준으로 해서 full_join을 한다.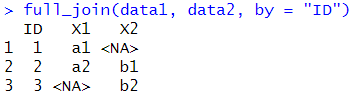
그런 다음, 그 결과로 생성된 객체(
.)를data3와 역시 공통 컬럼인ID를 기준으로 full_join을 한다.
- 왼쪽 테이블의
X2는X2.x로, 오른쪽 테이블의X2는X2.y로 변환되어 있음을 알 수 있다. - 최종으로 생성된 데이터의 첫 3개 행은 왼쪽 테이블, 그리고 네 번째 행은 오른쪽 테이블에 의해 생성되었다.
- 다만
X2.y컬럼과X3컬럼 중 첫 번째와 세 번째 행의 데이터, 그리고 네 번째 행의X1과X2.x컬럼의 값은 모두NA로 채워져 있음을 알 수 있다.
- 왼쪽 테이블의
6.8.9 예제 8: 복수 컬럼에 의한 조인
예제 7에서 본 것처럼, data2와 data3은 ID와 X2 컬럼을 같이 가지고 있다. 이 두 컬럼을 기준으로 두 개의 데이터 프레임을 조인하고자 한다면, by = 옵션에 동시에 그 변수들을 조인 변수로 지정하면 된다.
full_join(data2, data3, by = c("ID", "X2")) # Join by multiple columns ## ID X2 X3
## 1 2 b1 <NA>
## 2 3 b2 <NA>
## 3 2 c1 d1
## 4 4 c2 d2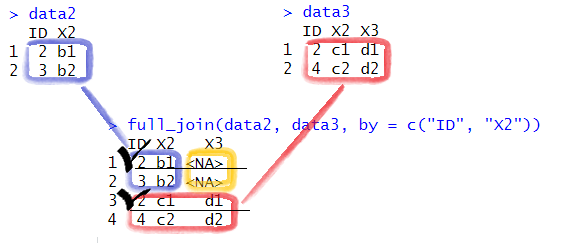
주의 : 최종적으로 생성된 데이터 세트에서 ID가 2 인 행의 경우, ‘1번 행’은 data2에는 X3가 없으므로 NA가 그리고 ‘4번 행’은 data3에는 X3가 d1 이므로 d1 값이 복사됨을 알 수 있다.
6.8.10 예제 9: 데이터 조인과 ID 삭제
마지막의 예로, 데이터 프레임을 조인하는데 사용된 공통의 컬럼인 ID가 더 이상 필요하지 않을 때가 있다. 이러한 ID 컬럼을 제거하기 위해서는 다음과 같은 코드를 사용하면 된다:
inner_join(data1, data2, by = "ID") %>% # Automatically delete ID
select(- ID) ## X1 X2
## 1 a2 b1