10.5 기타 패턴 유형
문자열로 된 패턴을 사용하면 자동으로 regex() 호출로 래핑된다.
fruit <- c("banana", "Banana", "BANANA")
# The regular call:
str_view(fruit, "nana")# Is shorthand for
str_view(fruit, regex("nana"))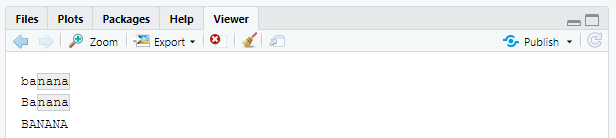
regex() 의 다른 인수를 사용하여 매치의 세부사항을 제어할 수 있다.
ignore_case = TRUE를 하면 문자가 대문자나 소문자 형태 모두로 매칭된다. 이때 항상 현재의 로케일을 사용한다.bananas <- c("banana", "Banana", "BANANA") str_view(bananas, "banana")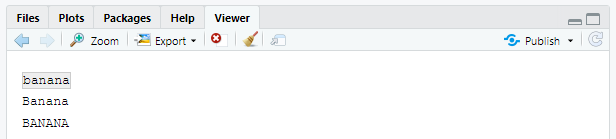
str_view(bananas, regex("banana", ignore_case = TRUE))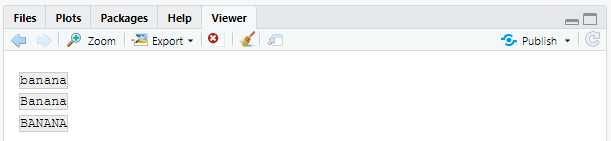
multiline = TRUE를 하면^와$이 전체 문자열의 시작, 끝이 아니라, 각 라인의 시작과 끝이 매칭된다.x <- "Line 1\nLine 2\nLine 3" str_extract_all(x, "^Line")[[1]]## [1] "Line"str_extract_all(x, regex("^Line", multiline = TRUE))[[1]]## [1] "Line" "Line" "Line"comments = TRUE를 하면 복잡한 정규표현식을 이해하기 쉽도록 설명과 공백을 사용할 수 있게 된다.#뒤에 나오는 다른 문자들처럼 공백도 무시된다. 공백 문자를 매치하기 위해서는“\\”로 이스케이프 해야 한다.phone <- regex(" \\(? # optional opening parens (\\d{3}) # area code [) -]? # optional closing parens, space, or dash (\\d{3}) # another three numbers [ -]? # optional space or dash (\\d{3}) # three more numbers ", comments = TRUE) str_match("514-791-8141", phone)## [,1] [,2] [,3] [,4] ## [1,] "514-791-814" "514" "791" "814"dotall = TRUE를 하면.이\n을 포함한 모든 것에 매칭된다.str_detect("\nX\n", ".X.")## [1] FALSEstr_detect("\nX\n", regex(".X.", dotall = TRUE))## [1] TRUE
regex() 대신 사용할 수 있는 세 가지 함수가 있다.
fixed()는 지정된 일련의 바이트와 정확히 매치한다. 이 함수는 모든 특수 정규표현식을 무시하고 매우 낮은 수준에서 동작한다. 이를 사용하여 복잡한 이스케이프를 피할 수 있으며 정규표현식보다 훨씬 속도가 빠르다. 다음의 소규모 벤치마크는 단순한 예시에 대해 약 3배 빠르다는 것을 보여준다.microbenchmark::microbenchmark( fixed = str_detect(sentences, fixed("the")), regex = str_detect(sentences, "the"), times = 20 )## Unit: microseconds ## expr min lq mean median uq max neval ## fixed 71.0 75.45 82.475 79.55 80.8 169.0 20 ## regex 201.5 203.45 211.400 204.90 208.3 271.4 20fixed()를 비영어에 사용할 때는 조심하라. 같은 문자를 나타내는 방법이 여러 가지이기 때문에 문제가 되는 경우가 많다. 예를 들어 ’á’를 정의하는 방법에는 두 가지가 있다. 즉, 단일한 문자로 하거나, ’a’와 악센트로 하는 방법이다.a1 <- "\u00e1" a2 <- "a\u0301" c(a1, a2)## [1] "a" "a<U+0301>"a1 == a2## [1] FALSE동일하게 렌더링하지만 다르게 정의되었기 때문에
fixed()가 매치를 찾지 못한다. 대신, 인간의 문자 비교 규칙을 존중하는coll()(아래에 정의됨)을 사용할 수 있다.str_detect(a1, fixed(a2))## [1] FALSEstr_detect(a1, coll(a2))## [1] TRUEcoll()은 표준 정렬(collation) 규칙을 사용하여 문자열을 비교한다. 대소문자를 구분하지 않는(case-insensitive) 매치를 수행할 때 유용하다.coll()은 문자 비교 규칙을 제어하는 로케일 파라미터를 취한다는 것을 주의해야 한다. 불행하게도 세계의 각 지역은 다른 규칙을 사용한다!# That means you also need to be aware of the difference # when doing case insensitive matches: i <- c("I", "İ", "i", "ı") i## [1] "I" "<U+0130>" "i" "ı"str_subset(i, coll("i", ignore_case = TRUE))## [1] "I" "i"str_subset(i, coll("i", ignore_case = TRUE, locale = "tr"))## [1] "i"fixed()와regex()모두에ignore_case인수가 있지만, 로케일 선택을 허용하지는 않는다. 이들은 항상 기본 로케일을 사용한다. 다음 코드를 통해 이를 알아볼 수 있다. (stringi 에서 더 살펴보자)stringi::stri_locale_info()## $Language ## [1] "ko" ## ## $Country ## [1] "KR" ## ## $Variant ## [1] "" ## ## $Name ## [1] "ko_KR"coll()의 단점은 속도이다. 어느 문자가 같은지 인식하는 규칙이 복잡하기 때문에,coll()은regex()와fixed()에 비해 상대적으로 느리다.str_split()에서 보았듯이boundary()를 사용하여 경계를 매치할 수 있다. 다른 함수들과도 사용할 수 있다.x <- "This is a sentence." str_view_all(x, boundary("word"))
str_extract_all(x, boundary("word"))## [[1]] ## [1] "This" "is" "a" "sentence"
10.5.1 연습문제
regex()vsfixed()를 사용하여, 어떻게\를 포함하는 모든 문자열을 찾겠는가?sentences에서 가장 자주 나오는 단어 다섯 가지는 무엇인가?