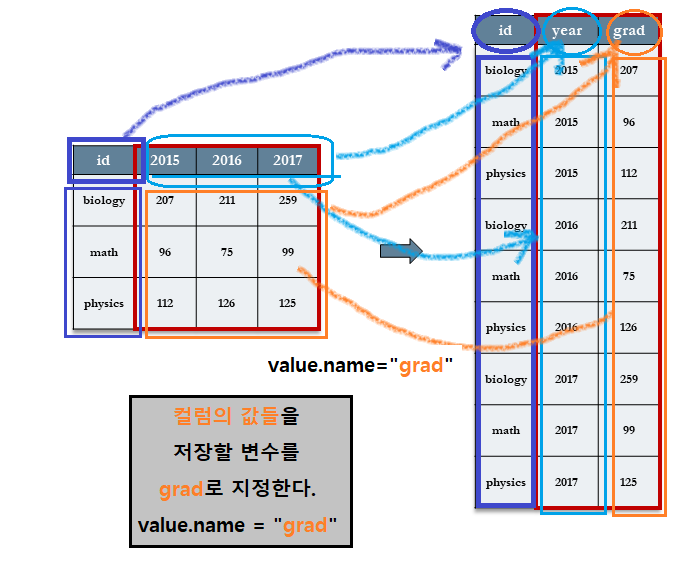
7.3 컬럼 제목들이 변수 명이 아니고 값들인 경우
3년간 3개의 학과로 부터 졸업생에 대한 데이터(dept1.csv)를 먼저 불러오기로 한다.
계획된 분석은 수년간 졸업자 수가 얼마나 증가했는지를 알아보는 것이다.
여기서 분석의 단위는 특정 년도(2015, 2016, 2017 등)에 있어서 특정 학과의 졸업율이다.
각각의 행은 학과별 해당 년도의 인원을 나타낸다.
7.3.1 데이터 세트
dept <- read_csv("data7/dept1.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## id = col_character(),
## `2015` = col_double(),
## `2016` = col_double(),
## `2017` = col_double()
## )dept## # A tibble: 3 x 4
## id `2015` `2016` `2017`
## <chr> <dbl> <dbl> <dbl>
## 1 biology 207 211 259
## 2 math 96 75 99
## 3 physics 112 126 1252015,2016,2017등의 연도(Year)는 분석의 ‘예측 변수(predictor)’이므로 컬럼 변수가 되어야 한다.- 각 3개 학과들은 3년간의 데이터를 가지고 있으므로, 매 년도마다 3개의 행을 가지고 있다.
- 또한, 전체 값들로 구성되는 테이블은 동일한 값들로 해당 년도에 있어서 해당 학과의 졸업자 수를 측정하고 있다.
- 그러므로, 해당 년도의 값들을 한 컬럼에 넣을 수 있다.
7.3.2 사용할 수 있는 함수의 종류
tidyr패키지의pivot_longer()함수tidyr패키지의gather()함수reshape2패키지의melt()함수
7.3.3 pivot_longer() 함수
pivot_longer() 함수를 사용하기 위해서는, 재구성할 변수의 집합(‘컬럼의 제목’과 ‘값’)을 선택한다:
- 원래 테이블의 컬럼의 제목들은 새로운 테이블의 컬럼 변수가 되고 그 컬럼의 값으로 반복적으로 축적이 된다 (
names_to =) - 원래 테이블의 컬럼 변수에 있는 값들은 새로운 테이블의 단일 컬럼 변수의 값으로 축적이 된다(
values_to =)
이 과정을 “long 형태로 재구성(reshaping)”한다고 말한다.
7.3.3.1 pivot_longer() 함수의 구문
pivot_longer( data, cols, names_to = “name,” names_prefix = NULL, names_sep = NULL, names_pattern = NULL, names_ptypes = list(), names_transform = list(), names_repair = “check_unique,” values_to = “value,” values_drop_na = FALSE, values_ptypes = list(), values_transform = list(), … )
주요 인수 :
data: 피봇할 데이터 프레임names_to ="name": 컬럼 제목을 값으로 유지할 새로운 컬럼 변수 명 (name)values_to = “value”: 데이터 값들을 저장할 새로운 컬럼 변수 명(value)
디폴트 값으로 pivot_longer 함수는 축적되는 모든 컬럼을 선택할 것이다. 그러나 새로운 names_to =에 있는 값들이 변화하지 않는 컬럼들은 축적되지 않아야 한다.
7.3.3.2 pivot_longer() 함수의 사용 예
재구성할 데이터 세트는 다음과 같다:
dept## # A tibble: 3 x 4
## id `2015` `2016` `2017`
## <chr> <dbl> <dbl> <dbl>
## 1 biology 207 211 259
## 2 math 96 75 99
## 3 physics 112 126 125새롭게 재구성되는 데이터 세트에는 ‘년도(year)’와 ‘졸업율(grad)’ 등의 2 개의 컬럼으로 표시하고 싶다.
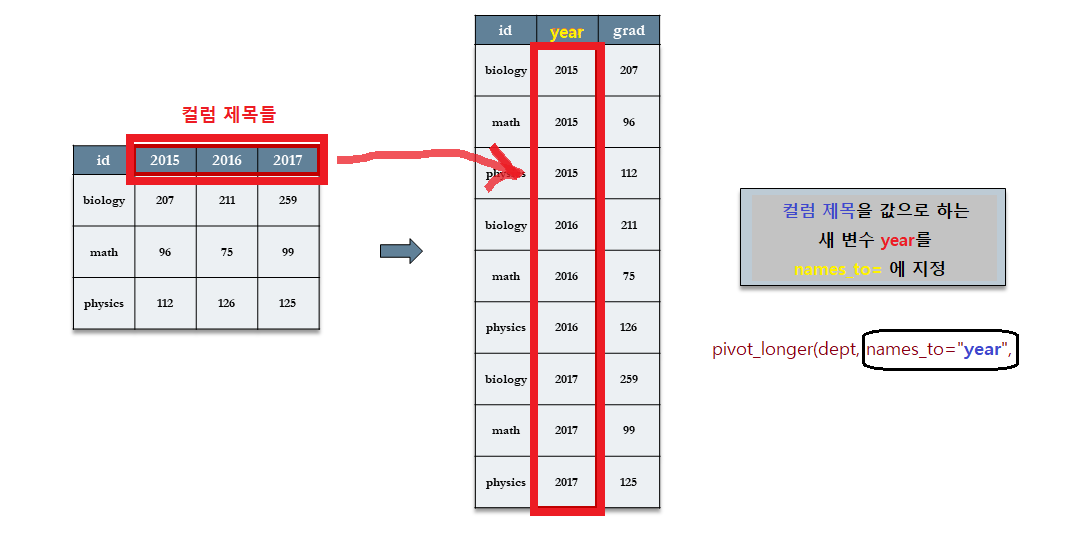
- 년도는 원래 데이터의 컬럼 제목이기 때문에,
names_to =인수에 변수명을year로 지정할 것이다.
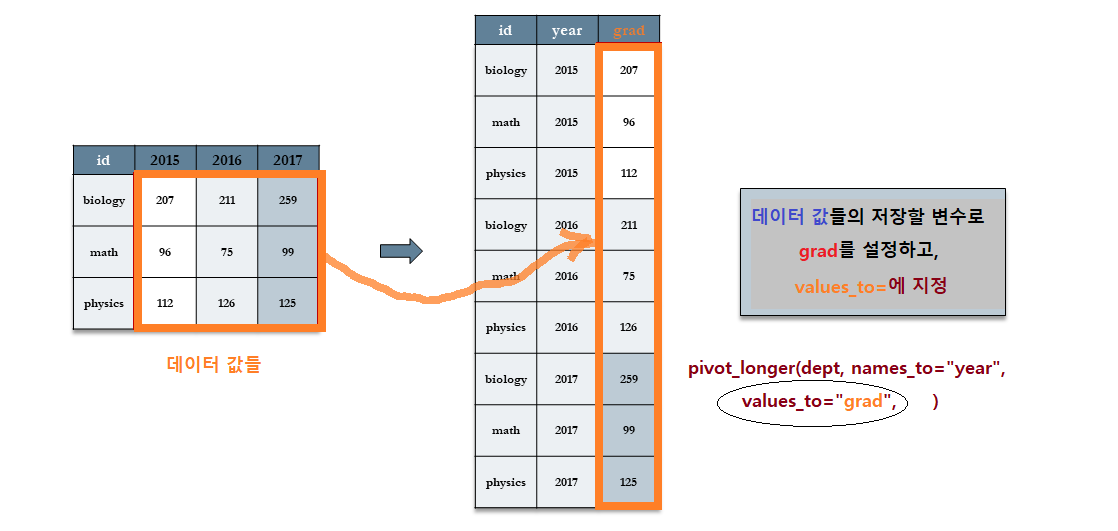
- 또한
2015,2016그리고2017컬럼에 있는 졸업율의 값들은 또 다른 새로운 변수에 축적이 되어야 하는데 이를values_to =인수로grad변수를 지정하여 저장할 것이다.
학과명(id)은 연도(year)와 상관없이 변함이 없으며 따라서 축적할 필요가 없다.
- 여기서
c(`2015`, `2016`, `2017`)로 압축이 되어야 하는 컬럼에 대해서만 컬럼을 지정하여 재구성을 할 것이며(주의 : 문자로 시작하지 않는 컬럼 명에 대해서는 컬럼 명을 지정할 때 ` 기호가 필요), - 이처럼 압축될 필요가 없는 컬럼에 대해서는 ‘
-’기호 다음에 컬럼을 지정한다.
# the new column "year" uses the column headings as values,
# the new column "graduates" will be the collapsed values
# we do not want to collapse id
dept_by_year <- dept %>%
pivot_longer(names_to="year", values_to="grad", -id)
dept_by_year## # A tibble: 9 x 3
## id year grad
## <chr> <chr> <dbl>
## 1 biology 2015 207
## 2 biology 2016 211
## 3 biology 2017 259
## # ... with 6 more rows7.3.3.3 pivot_longer() 함수의 활용 단계
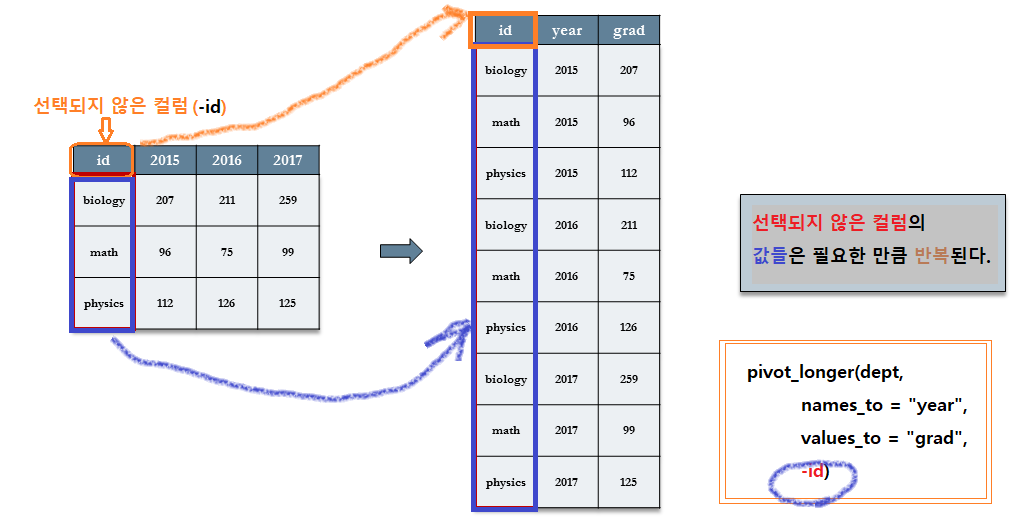
pivot_longer(names_to="year", values_to="grad", -id)
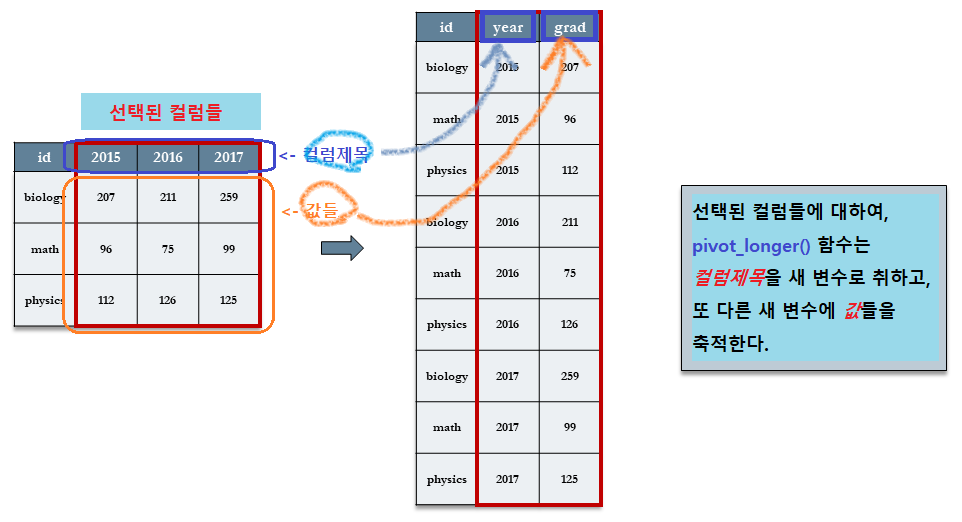
단계별 분석
7.3.3.3.1 [Step 1]names_to="year" : 컬럼 제목들을 값으로 하는 변수(year) 지정
7.3.3.3.2 [Step 2]values_to="grad" : 데이터 값들을 저장할 변수(grad) 지정
7.3.3.3.3 [Step 3] -id : 선택되지 않는 컬럼 지정. (- 컬럼명)
7.3.4 gather() 함수
gather() 함수를 사용하기 위해서는, 재구성할 변수의 집합(‘컬럼의 제목’과 ‘값’)을 선택한다:
- 원래 테이블의 컬럼의 제목들은 새로운 테이블의 컬럼 변수가 되고 그 컬럼의 값으로 반복적으로 축적이 된다 (
key = "year") - 원래 테이블의 컬럼 변수에 있는 값들은 새로운 테이블의 단일 컬럼 변수의 값으로 축적이 된다(
value =grad)
7.3.4.1 gather() 함수의 구문
gather( data, key = “key,” value = “value,” …, na.rm = FALSE, convert = FALSE, factor_key = FALSE ) 주요 인수
data: 피봇할 데이터 프레임key = “key”: 컬럼 제목을 값으로 유지할 새로운 컬럼 변수 명 (key)value = “value”: 데이터 값들을 저장할 새로운 컬럼 변수 명(value)
df %>% gather("key", "value", x, y, z)는df %>% pivot_longer(c(x, y, z), names_to = "key", values_to = "value")와 같다.
7.3.4.2 gather() 함수의 사용 예
앞의 예를 그대로 이용하기로 한다.
원래의 테이블인 dept에서
- `2015`, `2016`, `2017` 세 개의 컬럼이 새롭게 재구성되는 데이터 세트에서는 ‘년도(
year)’로 - 그리고 이 세 개의 컬럼에 있는 값들은 새로운 테이블의 ‘졸업율(
grad)’ 컬럼의 값으로 표시하고 싶다.
이를 위해,
- 먼저 `2015`, `2016`, `2017` 등의 세 개의 컬럼을 선정한다.
- 이 세 개의 컬럼제목을 값으로 하는 새로운 테이블의 컬럼 이름을 지정한다. (
key = “year”) - 이 세 개의 컬럼에 저장되어 있는 값들을 저장할 새로운 테이블의 컬럼 이름을 지정한다. (
value = “grad”
`2015`, `2016`, `2017` 등이 원래 데이터의 컬럼 제목이기 때문에 key = 인수에 변수명을 year로 지정할 것이다.
또한 2015, 2016 그리고 2017 컬럼에 있는 졸업율의 값들은 또 다른 새로운 변수에 축적이 되어야 하는데 이를 value = 인수로 grad 변수를 지정하여 저장할 것이다.
dept %>%
gather(`2015`, `2016`, `2017`, key = "year", value = "grad")## # A tibble: 9 x 3
## id year grad
## <chr> <chr> <dbl>
## 1 biology 2015 207
## 2 math 2015 96
## 3 physics 2015 112
## # ... with 6 more rowsyear변수에 `2015`, `2016`, `2017` 등의 컬럼 제목이 값으로 저장됨을 알 수 있다.grad변수에 `2015`, `2016`, `2017` 등의 컬럼 값들이 저장되어 있음을 알 수 있다.
7.3.4.3 gather() 함수의 활용 단계
dept %>% gather(`2015`, `2016`, `2017`, key = “year,” value = “grad”)
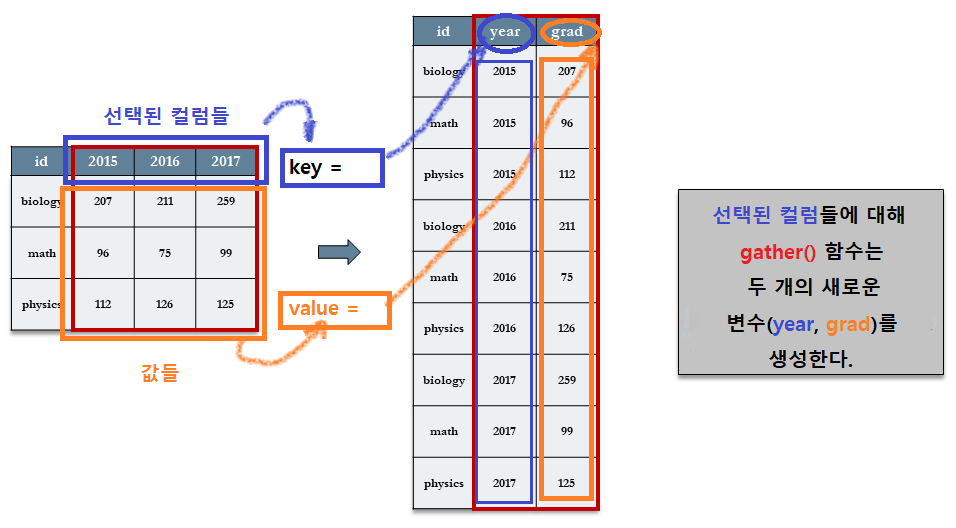
- 선택되지 않은 나머지 컬럼(
id)은 그대로 새로운 테이블에 반복적으로 저장되어 있음을 알 수 있다.
단계별 분석
이와 같은 타이디 데이터를 만들려면 해당 열을 새로운 부 변수로 수집(gather)해야 한다. 이 작업은 다음의 세 단계로 이루어진다.
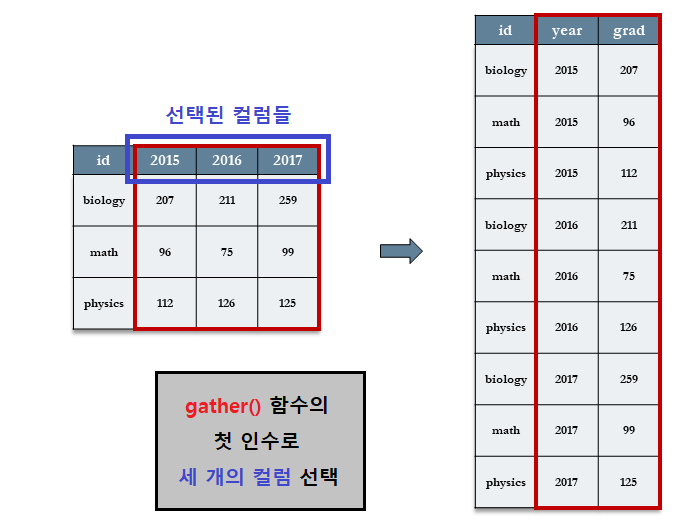
7.3.4.3.1 [Step 1] gather(`2015`, `2016`, `2017`, : 컬럼 제목들 선택
2015, 2016, 2017 등 값으로 되어 있는 컬럼 제목 세 개를 선택한다. 이 때, 선택된 컬럼 제목을 (``, 역 따옴표)안에 기입한다.
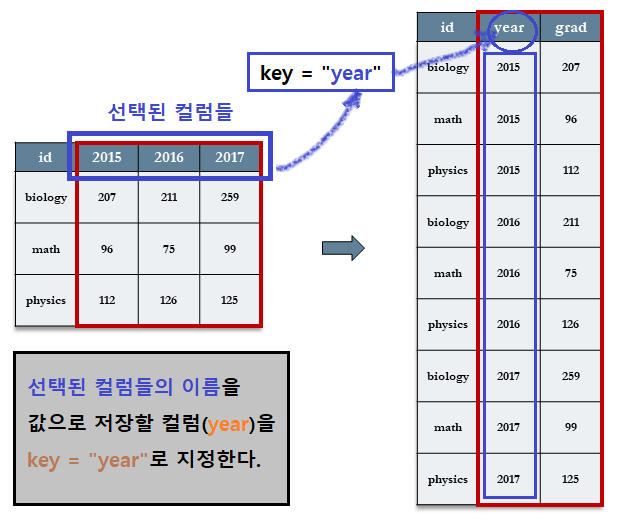
7.3.4.3.2 [Step 2] key = "year" : 새로운 테이블의 컬럼 명 지정
선택된 세 개의 컬럼이 새로운 테이블에 저장될 컬럼 명을 지정한다. 여기서는 year로 정하고 있다.
7.3.4.3.3 [Step 3] value = "grad" : 새로운 테이블의 컬럼 명 지정
선택된 세 개의 컬럼이 새로운 테이블에 저장될 컬럼 명을 지정한다. 여기서는 year로 정하고 있다.
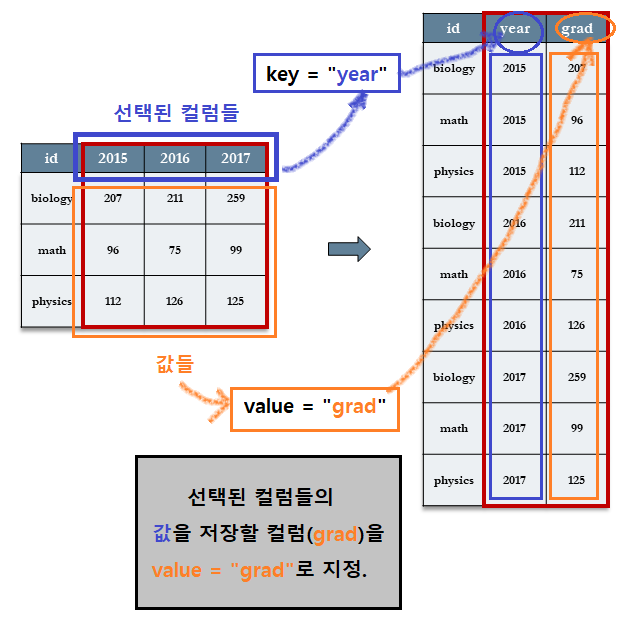
7.3.5 melt() 함수
melt() 함수를 사용하기 위해서는, 재구성할 변수의 집합(‘컬럼의 제목’과 ‘값’)을 선택하는 것이 아니고 원래의 테이블에서 사용하고 있는 컬럼 중 새로운 테이블에서도 계속 사용할 컬럼을 지정해 주면 된다.
- id 변수를 지정한다. (
id.vars = “id”) - 원래 테이블의 컬럼의 제목을 저장할 변수를 지정한다(
variable.name = year). - 원래 테이블의 컬럼 변수에 있는 값들을 저장한 새로운 테이블의 컬럼 변수의 이름을 지정한다(
value.name = "grad")
7.3.5.1 reshape2 패키지의 설치
melt() 함수를 사용하기 위해 reshape2 패키지를 설치한다.
# install.packages("reshape2")
library(reshape2)7.3.5.2 melt() 함수의 구문
melt( data, id.vars, measure.vars, variable.name = “variable,” …, na.rm = FALSE, value.name = “value,” factorsAsStrings = TRUE )
주요 인수
data: 재구성할 데이터 프레임id.vars:id변수들의 벡터measure.vars: 측정된 변수들의 벡터. 정수(변수의 위치) 또는 문자열(변수명). 빈 칸이면id.vars가 아닌 변수를 사용.variable.name = “variable”: 측정된 변수 명을 저장하는데 사용하는 변수의 이름. 디폴트 값은 “variable”...: 추가적 인수들na.rm: NA 값을 데이터 세트에서 제거할 지 여부value.name ="value": 값들을 저장하기 위해 사용될 변수의 이름. 디폴트 값은 “value”factorsAsStrings: 측정 변수로서 멜트될 때 factor 변수를 문자형으로 변환할 지 여부.
7.3.5.3 melt() 함수의 사용 예
dept %>%
melt(id.vars = "id", variable.name = "year", value.name = "grad")## id year grad
## 1 biology 2015 207
## 2 math 2015 96
## 3 physics 2015 112
## 4 biology 2016 211
## 5 math 2016 75
## 6 physics 2016 126
## 7 biology 2017 259
## 8 math 2017 99
## 9 physics 2017 125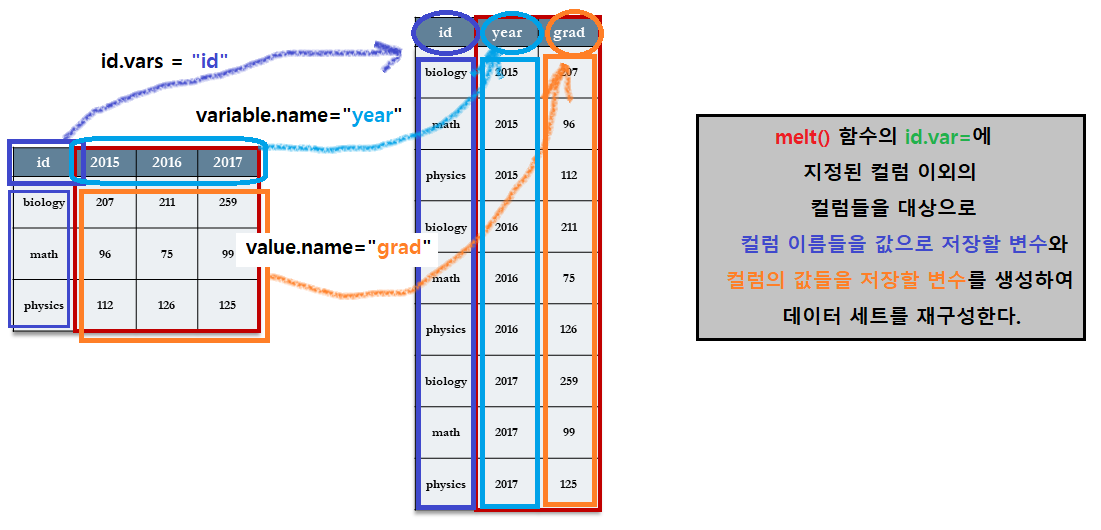
단계별 분석
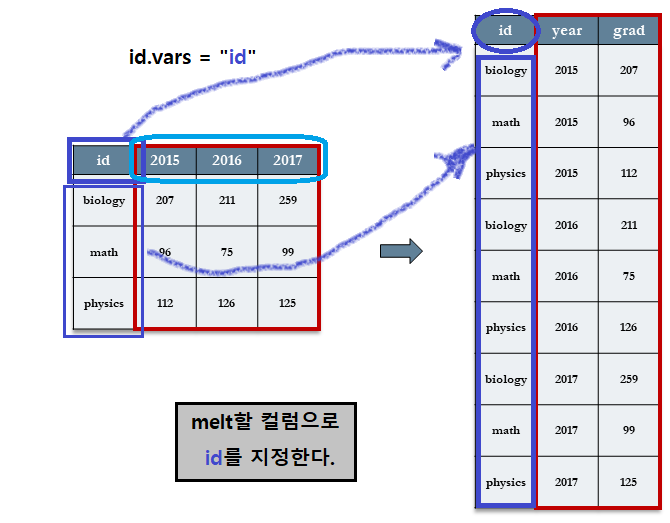
7.3.5.3.1 [Step 1] id.vars = “id” : id 컬럼을 지정한다.
dept 테이블의 id.vars 컬럼으로 id 컬럼을 지정한다.
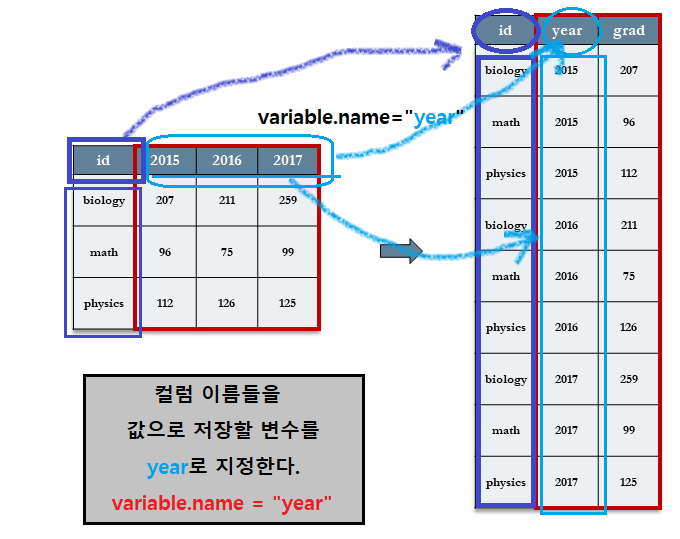
7.3.5.3.2 [Step 2] variable.name = “year” : id 컬럼 이외의 컬럼 이름(variable)을 값으로 저장할 변수 지정
dept 테이블의 id 컬럼 이외의 2015, 2016, 2017 컬럼 이름을 값으로 재구성할 컬럼의 이름을 year로 지정한다.
7.3.5.3.3 [Step 3] value.name = “grad” : id 컬럼 이외의 컬럼 값(value)을 저장할 변수 지정
dept 테이블의 id 컬럼 이외의 2015, 2016, 2017 컬럼의 행의 값을 저장할 컬럼의 이름을 grad로 지정한다.