11.5 범주형 데이터(요인)의 수준 순서 바꾸기
차량의 종류(Type) 변수와 같은 범주형 변수의 그룹(요인)을 x 축으로 그래프를 그리면 디폴트는 알파벳 순서대로 그룹이 제시가 됩니다. 만약 순서형 요인(ordered factor)으로 범주형 변수를 만들었다면 그 순서에 따라서 그래프가 그려질 겁니다.
그런데 분석가가 범주형 변수의 그룹의 순서를 ggplot2가 디폴트로 그려준 것과는 달리 바꾸고 싶어할 수 있습니다.
이때 scale_x_discrete(limits=c(...)) 함수를 사용해서 그룹의 순서를 바꿀 수 있습니다.
아래의 예제에 사용할 데이터는 Cars93 데이터 세트에는 Type 변수와 Origin 변수를 포함해서 총 9개의 요인형 변수가 있습니다.12
이 중에서 Type 변수와 Origin 변수 등 2 개의 변수를 중심으로 살펴보겠습니다.
Type 변수의 경우에는 “Compact,” “Large,” “Midsize,” “Small,” “Sporty,” “Van” 등 6개의 수준으로 구성이 되어 있으며, 지금까지 살펴 본 그래프에서 이들 수준이 알파벳 순서로 정렬이 되어 있었습니다.
ggplot2 패키지를 사용해서 Type을 x축으로 Price 를 y축으로 해서 박스 그래프를 그려보겠습니다.
이를 위해서 먼저 데이터셋을 ggplot2에서 사용할 수 있는 형태로 변환이 필요합니다. 가로로 옆으로 늘어서 있는 원래의 Cars93 데이터셋을 tidyverse 패키지의 pivot_longer() 함수를 이용하여 세로로 길게 세워보겠습니다.
## Factor 변수의 수준 순서 바꾸기
# 데이터 준비
library(tidyverse)
Cars93.sub1 <- Cars93[, c("Type", "Price")]
Cars.Data <- Cars93.sub1 %>%
pivot_longer(names_to = "Variable",
values_to = "Value",
-1)
str(Cars.Data)## tibble [93 x 3] (S3: tbl_df/tbl/data.frame)
## $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
## $ Variable: chr [1:93] "Price" "Price" "Price" "Price" ...
## $ Value : num [1:93] 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...데이터셋 준비가 되었으므로, 디폴트 설정으로 해서 x축에 Type, y축에 Price로 Box plot 을 그려보겠습니다.
x축의 요인(factor)의 순서가 앞에서 살펴본 것처럼 “Compact,” “Large,” “Midsize,” “Small,” “Sporty,” “Van” 등과 같이 알파벳 순서로 되어있습니다.
# Type 변수의 기본 수준 순서
f1 <- ggplot(Cars.Data, aes(x=Type, y=Value)) +
geom_boxplot() +
ggtitle(("Boxplot of Price"))
f1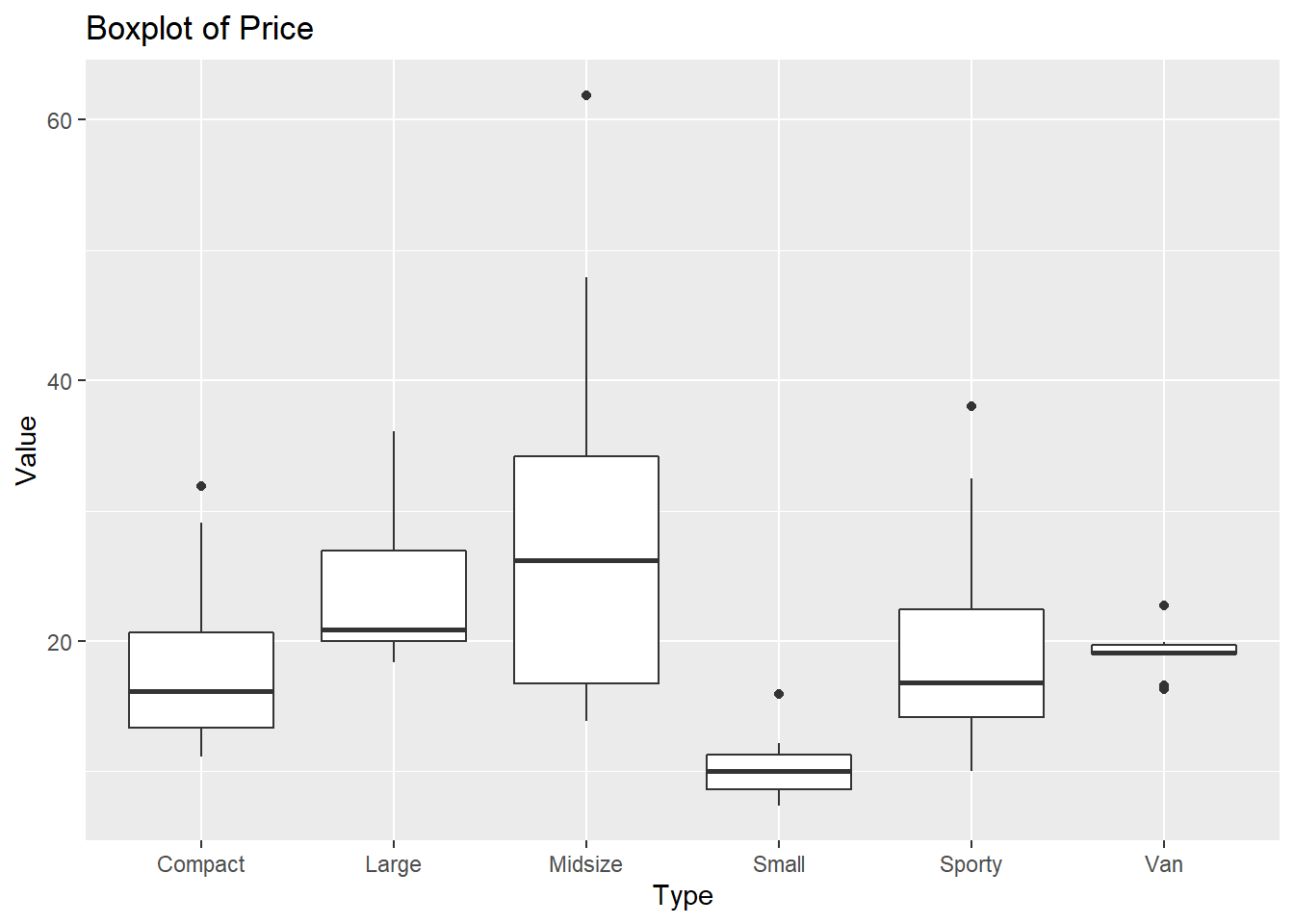
Figure 11.79: 차량 유형별 가격
이제 Type 변수의 수준 순서를 필요에 따라서 “Small,” “Midsize,” “Large,” “Compact,” “Sporty,” “Van” 등의 순서로 바꾸고 싶다고 가정해 보겠습니다. 이때 사용하는 것이 scale_x_discrete(limit=...)함수입니다.
# Type 변수의 수준 순서 바꾸기 : scale_x_discrete() 함수 이용
f2 <- f1 +
scale_x_discrete(limits=c("Small", "Midsize", "Large",
"Compact", "Sporty`", "Van")) +
ggtitle("X축 수준의 순서 변경 : scale_x_discrete(limit=...) 함수 이용")
f2## Warning: Removed 14 rows containing missing values (stat_boxplot).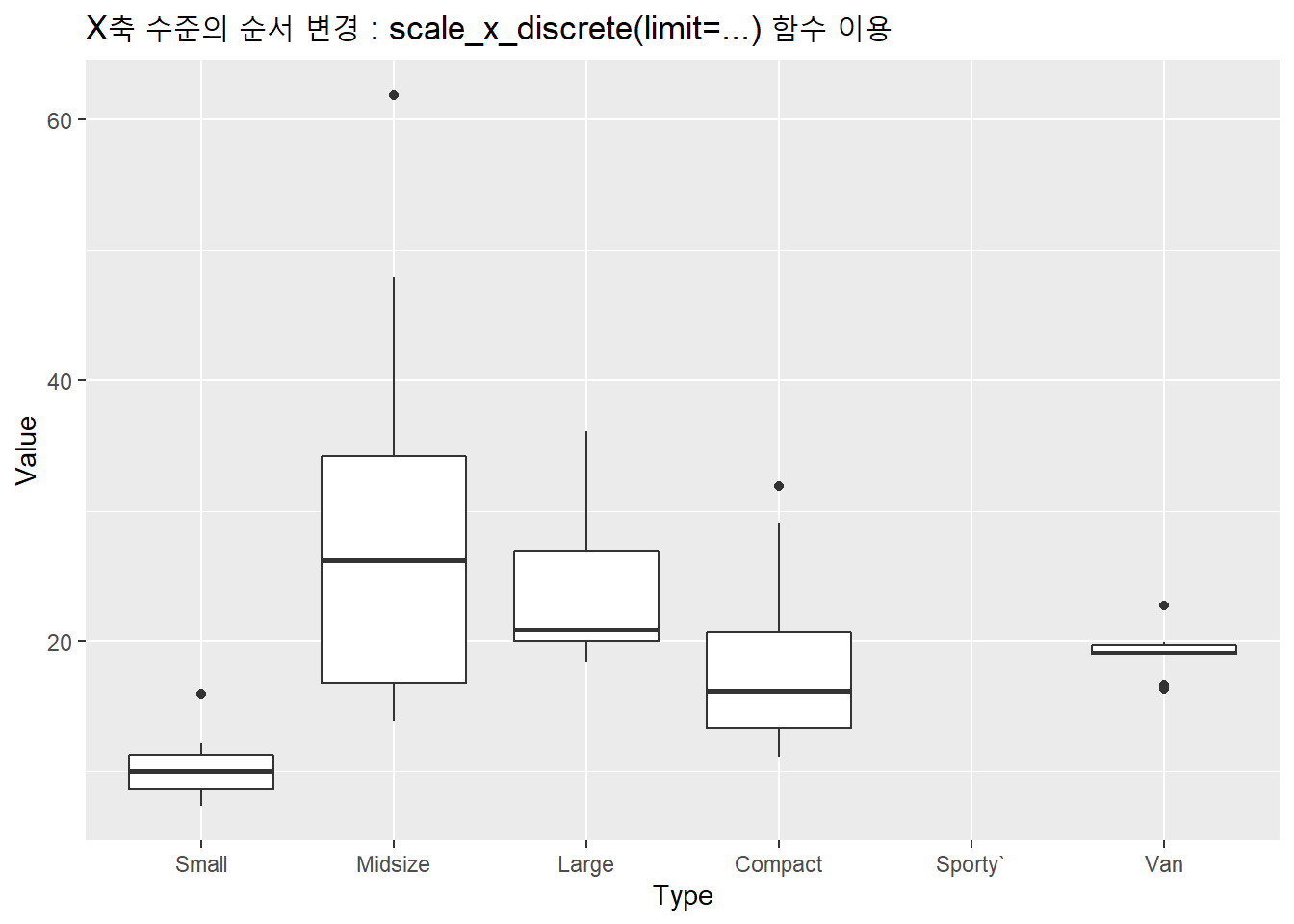
Figure 11.80: X축 수준의 순서 바꾸기 : scale_x_discrete(limit=…) 함수 이용
처음 f1 그래프는 Type 변수의 수준을 알파벳 수준으로 정렬한 디폴트의 박스 그래프이며, 두 번째에 f2 그래프는 Type 변수의 수준을 분석가의 필요에 따라 순서를 바꾼 박스 그래프입니다.
Manufacturer(32),Model(93),Type(6),AirBags(3),DriveTrain(3),Cylinders(6),Man.trans.avail(2),Origin(2),Make(93) 등 총 9개 변수입니다. () 안의 숫자는 수준의 갯수를 나타냅니다.↩︎