9.2 추가적인 심미적 매핑 탐색
geom_*() 함수에 좀 더 살펴보도록 하겠습니다. 심미적 매핑은 데이터 시각화에서 우리를 위해 많은 일을 해 줍니다.
따라서 데이터에서 변수를 나타낼 수 있는 심미적 요소들에 대하여 살펴 보겠습니다.
지금까지 x와 y 위치를 지정하였고, 이것은 “점”이라는 기하학적 객체로 표현하는데 필요한 심미적 요소입니다. 그러나 더 많은 선택 사항이 있습니다.
다음 예제에서는 필요한 심미적 매핑 (x 와 y 위치)을 수행한 다음 geom_point () 함수가 표현할 수 있는 다른 심미적 요소(색상, 모양, 크기, 알파 - 투명도)도 사용해 보겠습니다. 또한 이중 또는 삼중 의 심미적 “매핑”이 허용되는 것을 볼 수 있습니다. 여러 심미적 표현으로 동일한 변수를 나타낼 수 있습니다.
Cars93 %>%
ggplot() +
# X축 : Weight 변수
aes(x = Weight) +
# y축 : MPG.highway 변수
aes(y = MPG.highway) +
# 데이터 각 행의 X와 Y 위치에 점을 표시 : geom_point() 함수
geom_point() +
# 다음의 요소를 (+)로 중복 적용할 수도 있고,
# 한번에 하나씩 적용할 수도 있습니다.
aes(colour = Type) + # 색 지정
aes(shape = Type) + # 점의 모양 지정
aes(size = MPG.highway) + # 점의 크기
aes(alpha = MPG.highway) + # 점의 투명도
aes(colour = MPG.highway) # 색의 중복 적용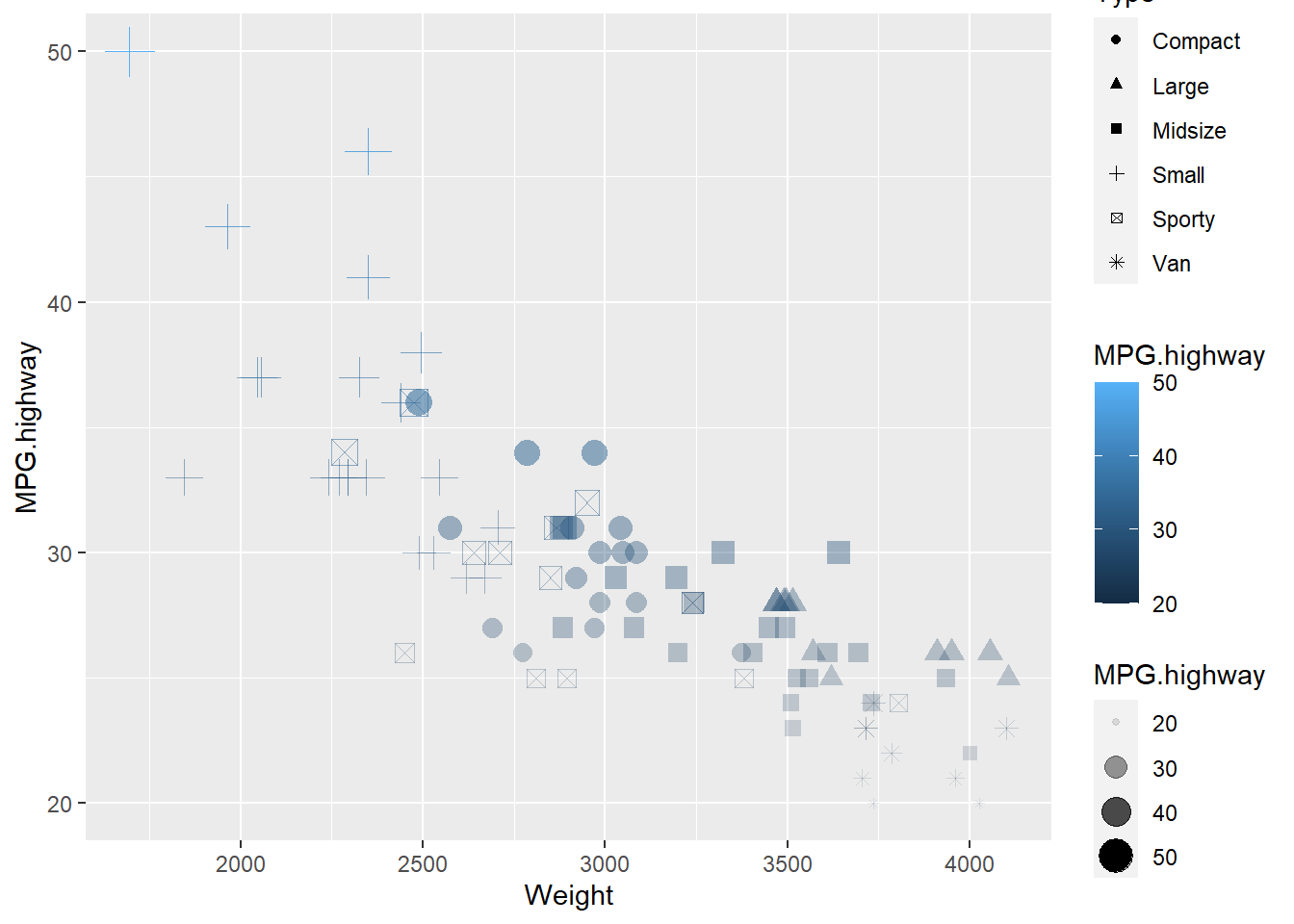
Figure 9.8: ggplot을 위한 심미적 요소의 추가 1
9.2.1 추가적 심미적 요소
다음의 플롯에서 fill = 요소와 color = 요소는 어떻게 다를까요?
Cars93 %>%
ggplot() +
# X축 : Type 변수
aes(x = Type) +
# geom_bar() 함수
geom_bar() +
# 추가적인 심미적 요소
aes(colour = Type) + # 막대의 테두리 색 지정
aes(fill = Type) + # 막대의 채우기 색 지정
aes(alpha = ..count..) + # 막대 색의 투명도 (Type 별 빈도수) 지정
aes(linetype = Type)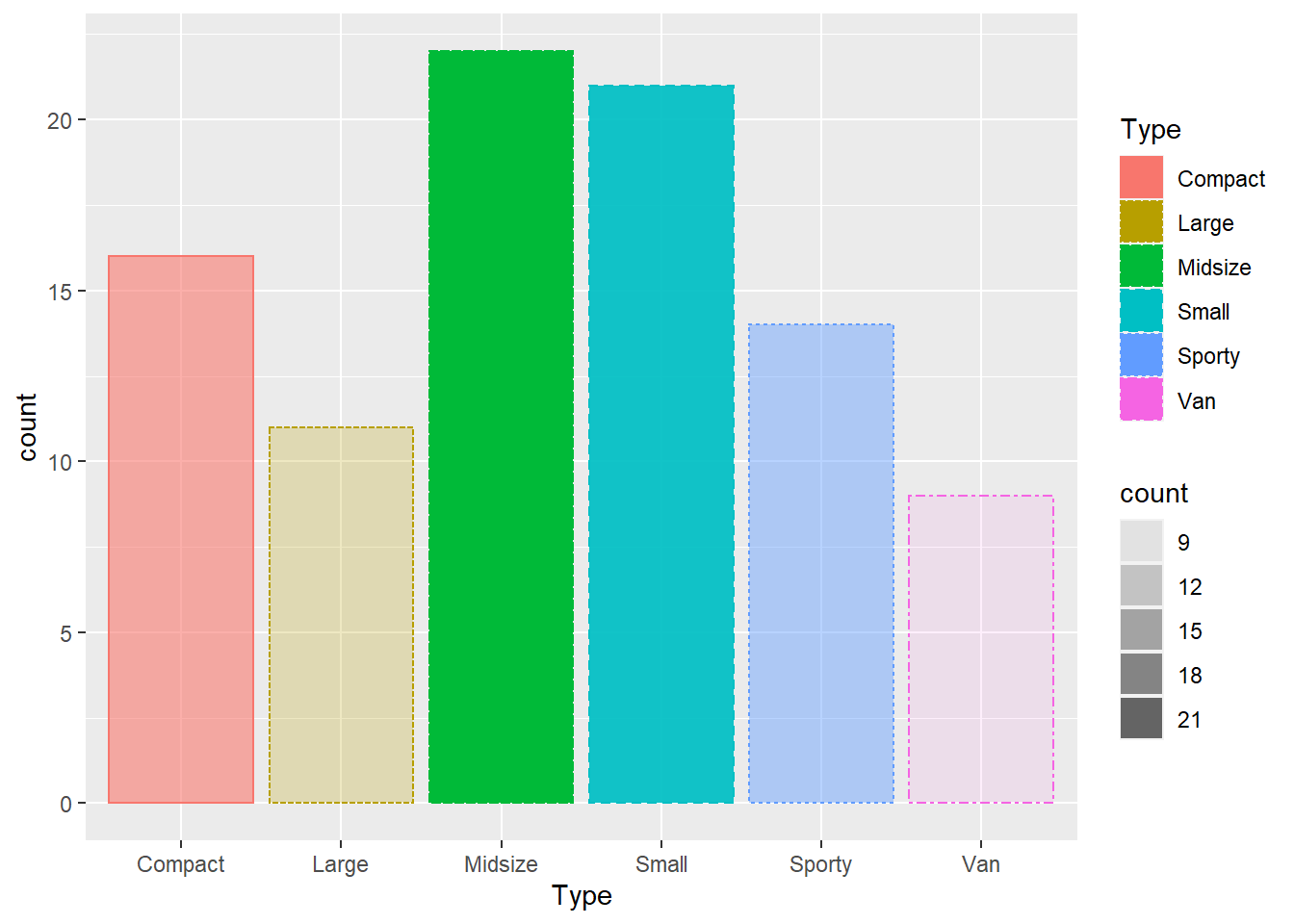
Figure 9.9: ggplot을 위한 심미적 요소의 추가 2
참고자료 : A ggplot2 grammar guide
ggplot2 가 어떻게 작동하는지를 간단히 설명하기란 매우 어렵습니다. 왜냐하면 ggplot2는 데이터 시각화와 관련한 심오한 철학을 담고 있기 때문입니다.
그러나, 대부분의 경우
ggplot()함수에 데이터를 제공하고,aes()함수에 심미적 매핑을 제공해서 시작하게 됩니다.- 그런 다음,
geom_point()함수,geom_histogram()함수 등의 레이어, scale_colour_brewer()함수와 같은 척도,facet_wrap()함수와 같은 faceting 설정- 그리고
coord_flip()함수 등과 같은 좌표 시스템을 추가하게 됩니다.
다음의 예는 Cars93 데이터 세트를 이용하여, X축과 Y축으로 각각 Cylinders와 MPG.highway, 그리고 점의 색상은 Type 변수를 기준으로 해서 데이터를 점으로 시각화하고 있습니다.
ggplot(Cars93,
aes(x = Cylinders,
y = MPG.highway,
colour = Type)) +
geom_point()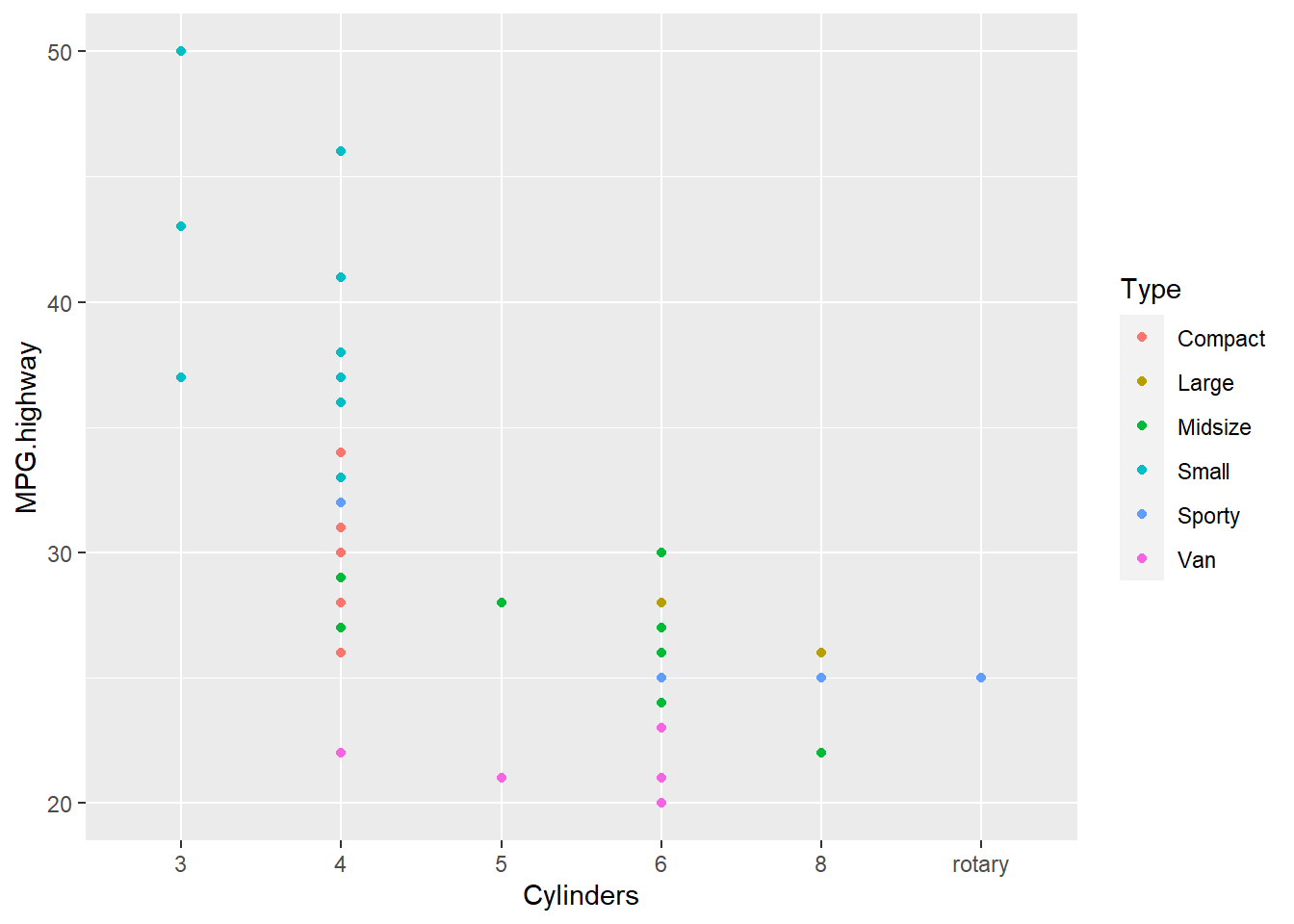
9.2.2 stat_*() 함수
ggplot() 함수는 시각화 객체로서 앞에서 설명한 geom_*() 함수들을 사용합니다. 그런데 이 시각화 객체 함수들은 처리하는 데이터를 통계적으로 변환해 주는 stat 모수들을 담고 있습니다.
예를 들어, geom_histogram() 함수는 한 변수의 데이터를 일정한 수의 bin(구간)으로 나눈 후, 각각의 bin에 속하는 데이터 갯수를 셉니다. 즉, X축은 데이터의 구간 값(bin)들이고, Y축은 각 구간 별 데이터의 갯수(..count..)가 되는 것입니다. 여기서 ..count.. 변수는 원래 데이터 세트에는 없는 변수입니다.
이처럼 geom_*() 함수를 이용하여 그래프를 그리면 새로운 값을 계산해내는 ggplot2의 알고리즘이 필요하고 이러한 알고리즘을 stat(Statistical Transformation)이라고 합니다. 그리고 이러한 geom_*() 함수에서 사용하는 stat 알고리즘은 args(geom_*)으로 확인할 수 있습니다.
geom_point() 함수의 기본 알고리즘을 확인해 보겠습니다.
args(geom_point)## function (mapping = NULL, data = NULL, stat = "identity", position = "identity",
## ..., na.rm = FALSE, show.legend = NA, inherit.aes = TRUE)
## NULLstat = "identity"가 geom_point() 함수의 기본 알고리즘임을 알 수 있습니다.
그런데 여기서 또 중요한 것은 stat_알고리즘() 함수를 geom_*() 함수를 대체해서 사용할 수 있다는 것입니다.
즉, stat_identity() 함수로 geom_point() 함수를 대신해 사용할 수 있습니다. 앞에서 geom_point() 함수를 사용한 그림 9.7은 다음과 같이 stat_identity() 함수를 이용해도 그릴 수 있다는 것입니다.
Cars93 %>%
ggplot() +
# X축 : Weight 변수
aes(x = Weight) +
# y축 : MPG.highway 변수
aes(y = MPG.highway) +
# 데이터 각 행의 X와 Y 위치에 점을 표시 : stat_identity() 함수
stat_identity()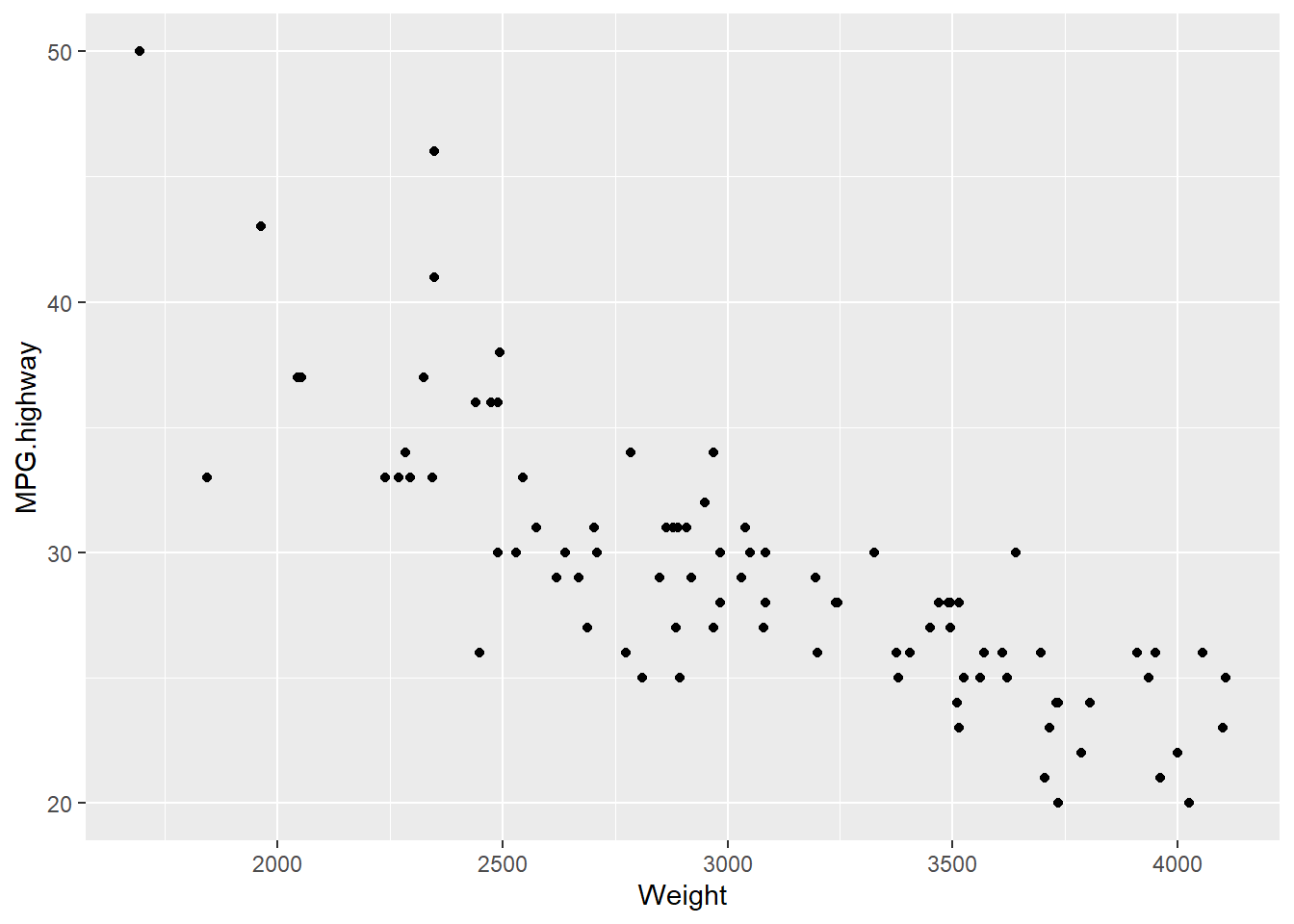
Figure 9.10: ggplot 시각화 객체 : stat_identity() 함수
한편 stat에 지정된 알고리즘이 아닌 데이터 세트에 있는 변수로 그래프를 그려야 할 때가 있습니다.
예를 들어, geom_bar() 함수의 경우 count를 기본 stat으로 하여 x축의 변수에 대한 도수(count)를 y축에 표시하게 됩니다. 그런데 Y축에 이러한 카운트를 사용하지 않고, 데이터 세트에 있는 다른 변수를 표시하고 싶은 경우가 있습니다.
다음은 Cars93 데이터 세트에 있는 자동차의 유형(Type)을 X축에 그리고 고속도로 연비(MPG.highway)를 Y축에 막대 그래프로 표시하는 예입니다.
ggplot(Cars93) +
aes(x = Type) +
aes(y = MPG.highway) +
geom_bar()## Error: stat_count() can only have an x or y aesthetic.
이 경우에 geom_bar() 함수는 count 알고리즘을 기본 stat으로 사용하므로 Y축이 y = ..count.. 이 되어야 하는데, 지금은 y = MPG.highway로 되어 있어 에러가 발생합니다.
Y축의 값으로 기본적인 stat 알고리즘을 사용하지 않는 경우에는 이러한 에러를 방지하기 위해서 시각화 객체인 geom_bar() 함수에 stat = 'identity'를 삽입해 주어야 합니다.
이는 Y축에 표시될 값은 기본 알고리즘을 사용하여 산출하지 않고 원 데이터 세트에 있는 값으로 사용하겠다는 설정인 것입니다.
ggplot(Cars93,
aes(x = Type,
y = MPG.highway)) +
geom_bar(stat = "identity")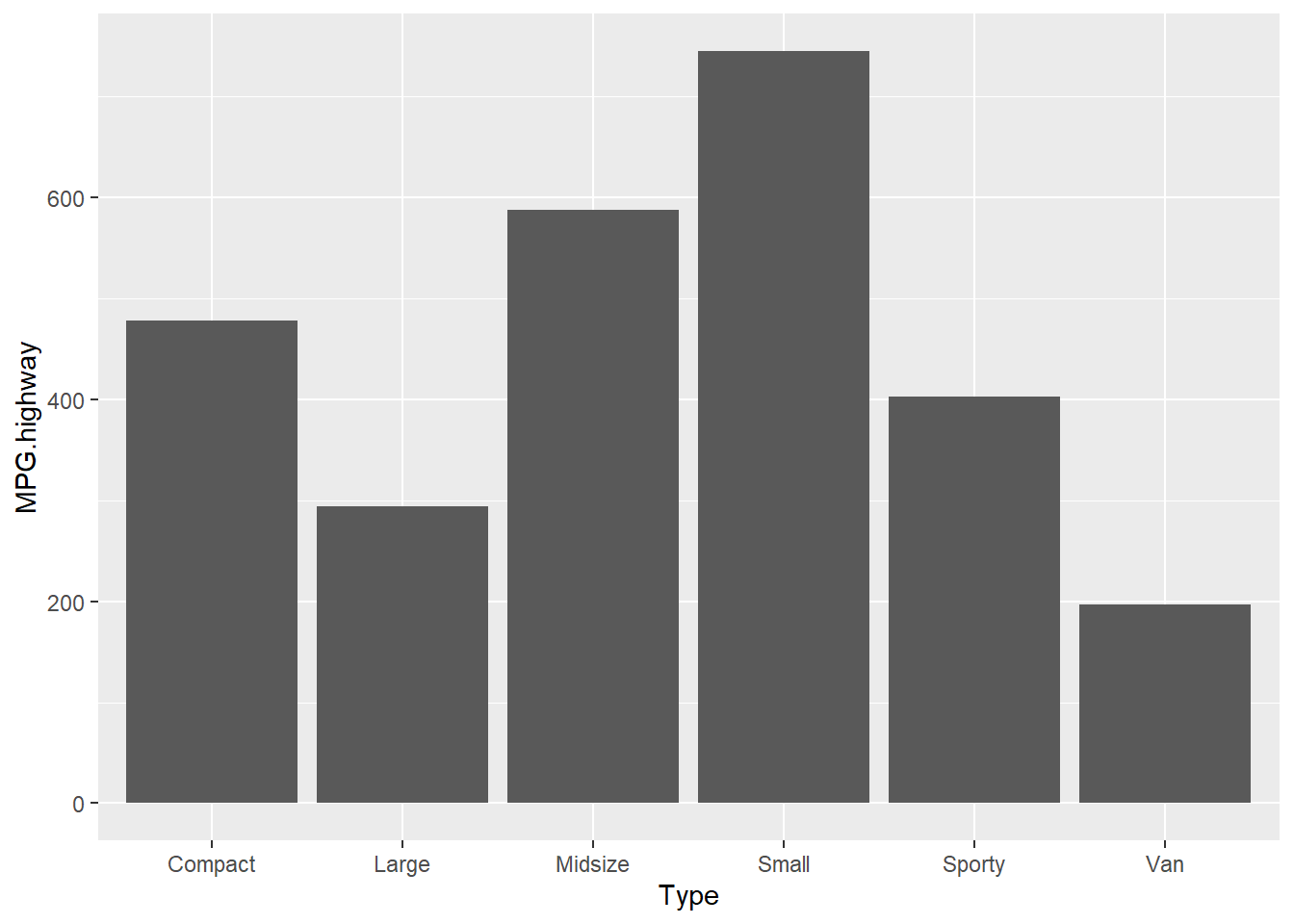
Figure 9.11: Y축을 데이터 세트의 값으로 사용할 경우 : stat = ‘identity’
이제 우리가 원하는대로 X축에 자동차 유형(Type)이 그리고 Y축에는 고속도로 연비(MPG.higyway)가 표시되고 있음을 알 수 있습니다.
그런데 여기서 Y축의 값은 무슨 값일까요? 기본적으로 합계 값을 표현하고 있습니다.
참고로, 합계 값은 다음과 같이 확인할 수 있습니다.
Cars93 %>% # 데이터 세트
group_by(Type) %>% # X 축의 변수로 그룹화합니다.
summarise(sum(MPG.highway)) # Y 축의 변수의 그룹별 합계를 구합니다.## # A tibble: 6 x 2
## Type `sum(MPG.highway)`
## <fct> <int>
## 1 Compact 478
## 2 Large 294
## 3 Midsize 588
## 4 Small 745
## 5 Sporty 403
## 6 Van 197