4.2 일변량 연속형 데이터 그래프
연속형 변수 1개를 그래프로 표시해 보겠습니다다.
그래프로 그릴 변수는 Cars93$MPG.highway 컬럼 한 개(일변량)로, 이 변수는 int 형의 연속형 변수임을 알 수 있습니다.
이 절에서의 일변량 연속형 데이터에 대하여 다음의 그래프를 그려 보기로 한다.
4.2.1 히스토그램
히스토그램은 이 변수의 최소값(min) ~ 최대값(max) 사이를 적당한 구간(bin 또는 class라고 함)으로 나누고, 각 구간에 속하는 데이터의 갯수를 그래프로 표시한 것입니다.
library(MASS)
# histogram : hist()
hist(Cars93$MPG.highway, main = "histogram : hist()")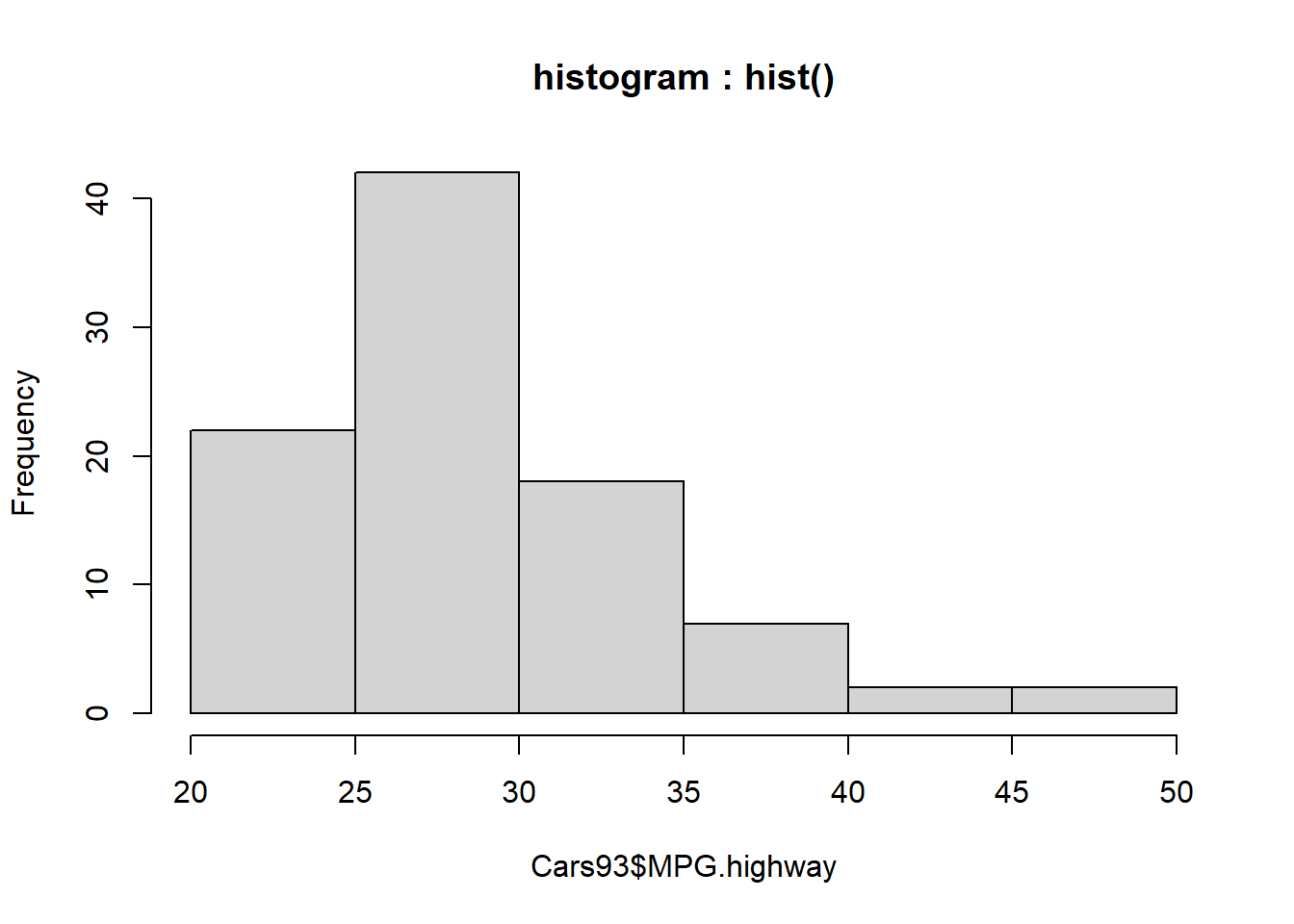
Figure 4.2: 일변량 연속형 데이터 그래프 : 히스토그램
- 히스토그램에서는 X축을 구성하는 구간을 결정하는 것이 매우 중요합니다. :
breaks =인수로 지정. 기본값은Sturges공식으로 구해진 구간을 사용합니다.
X축의 구간은 hist() 함수의 breaks = 모수에서 지정할 수 있습니다. 이 breaks 모수의 값은 seq() 함수를 이용하여 설정할 수 있습니다. 이 때 seq() 함수의 length.out의 값으로 (구간의 수 + 1)의 값을 대입해 줍니다.
# histogram : hist()
hist(Cars93$MPG.highway, main = "histogram : hist()",
breaks = seq(20, 50, length.out = 11)) # 20 ~ 50 까지의 숫자로 10개 구간으로 히스토그램을 그립니다.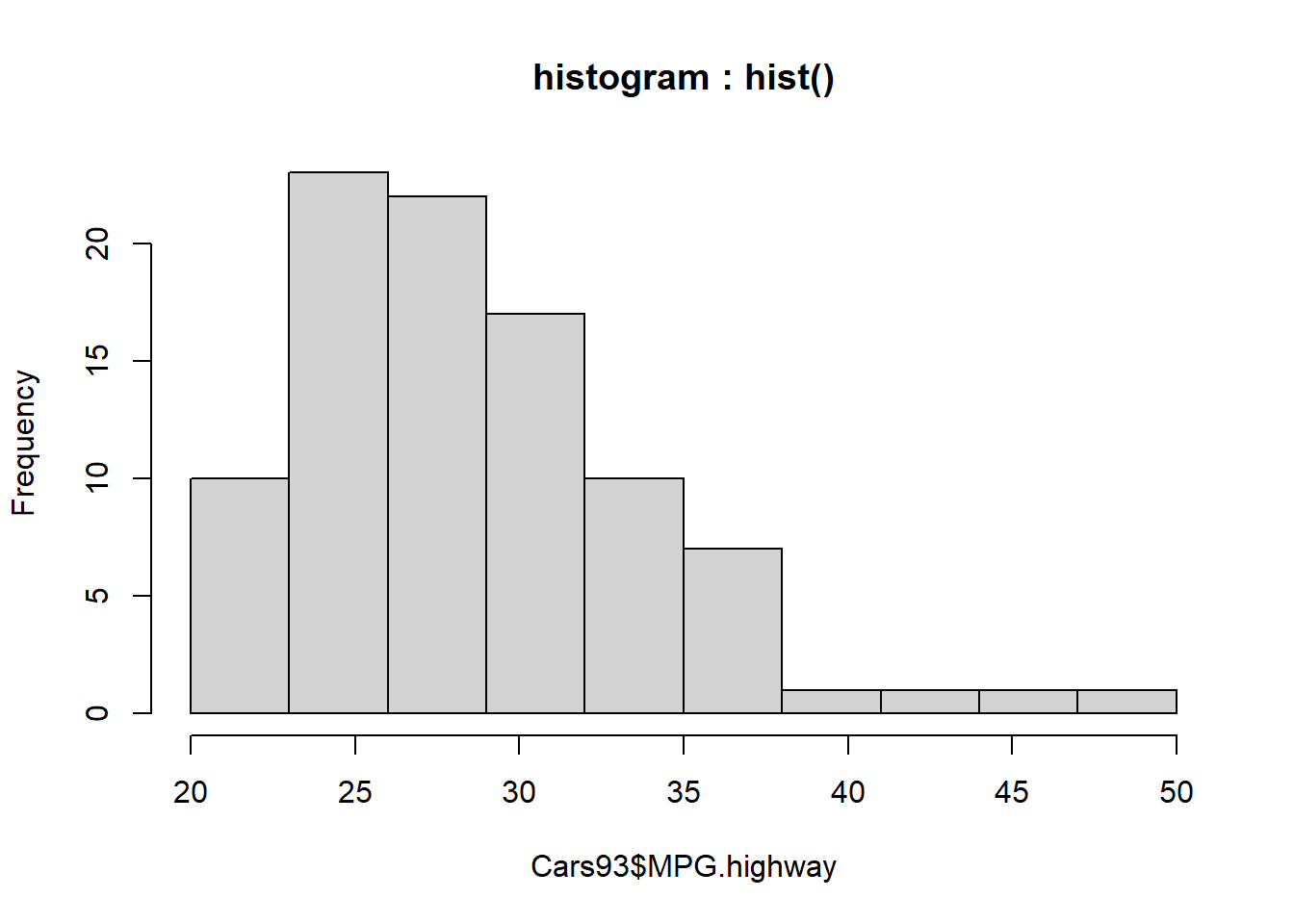
Figure 4.3: 일변량 연속형 데이터 그래프 : 히스토그램의 구간 조절
xlab, ylab 등의 모수를 이용하여 x축과 y축의 제목을 변경할 수 있으며, ylim의 모수를 이용하여 y축의 값의 범위를 조절할 수 있습니다. 그리고 main 모수에 그래프의 제목을 지정할 수 있습니다.
# histogram : hist()
y <- hist(Cars93$MPG.highway,
xlab = "고속 도로 연비", # x축의 제목을 설정합니다.
ylab = "빈도 수", # y축의 제목을 설정합니다.
main = "histogram : hist()") # 그래프의 제목을 설정합니다.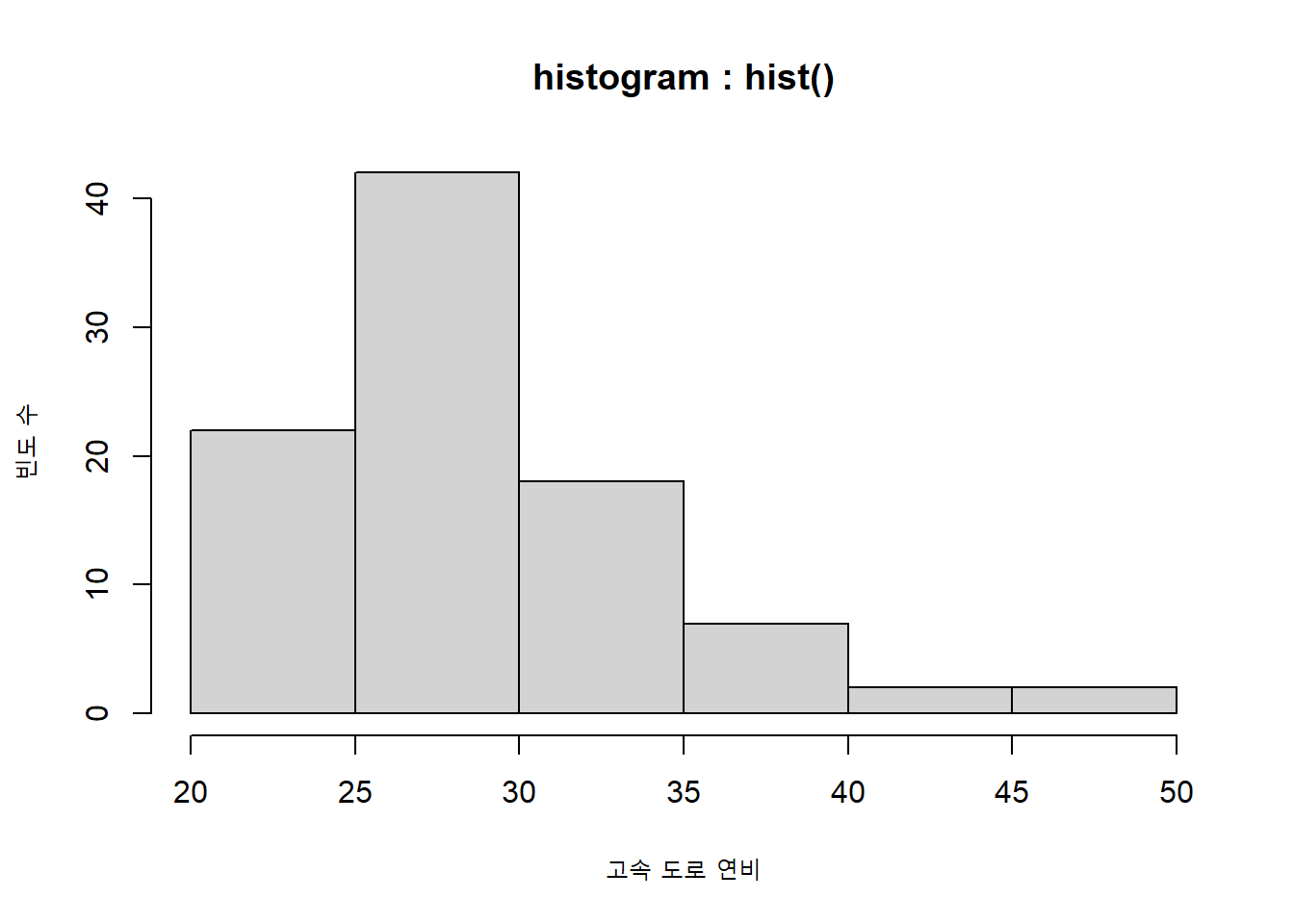
Figure 4.4: 일변량 연속형 데이터 그래프 : 히스토그램 - 축 제목과 그래프 제목
히스토그램의 막대의 색을 col 모수에 지정할 수 있으며, 또한 ylim 으로 y축의 값의 범위를 지정할 수 있습니다.
# histogram : hist()
hist(Cars93$MPG.highway, main = "histogram : hist()",
col = topo.colors(6), # 막대의 색을 그라디에이션으로 지정합니다.
ylim = c(0, 50)) # y축의 값의 범위를 지정합니다.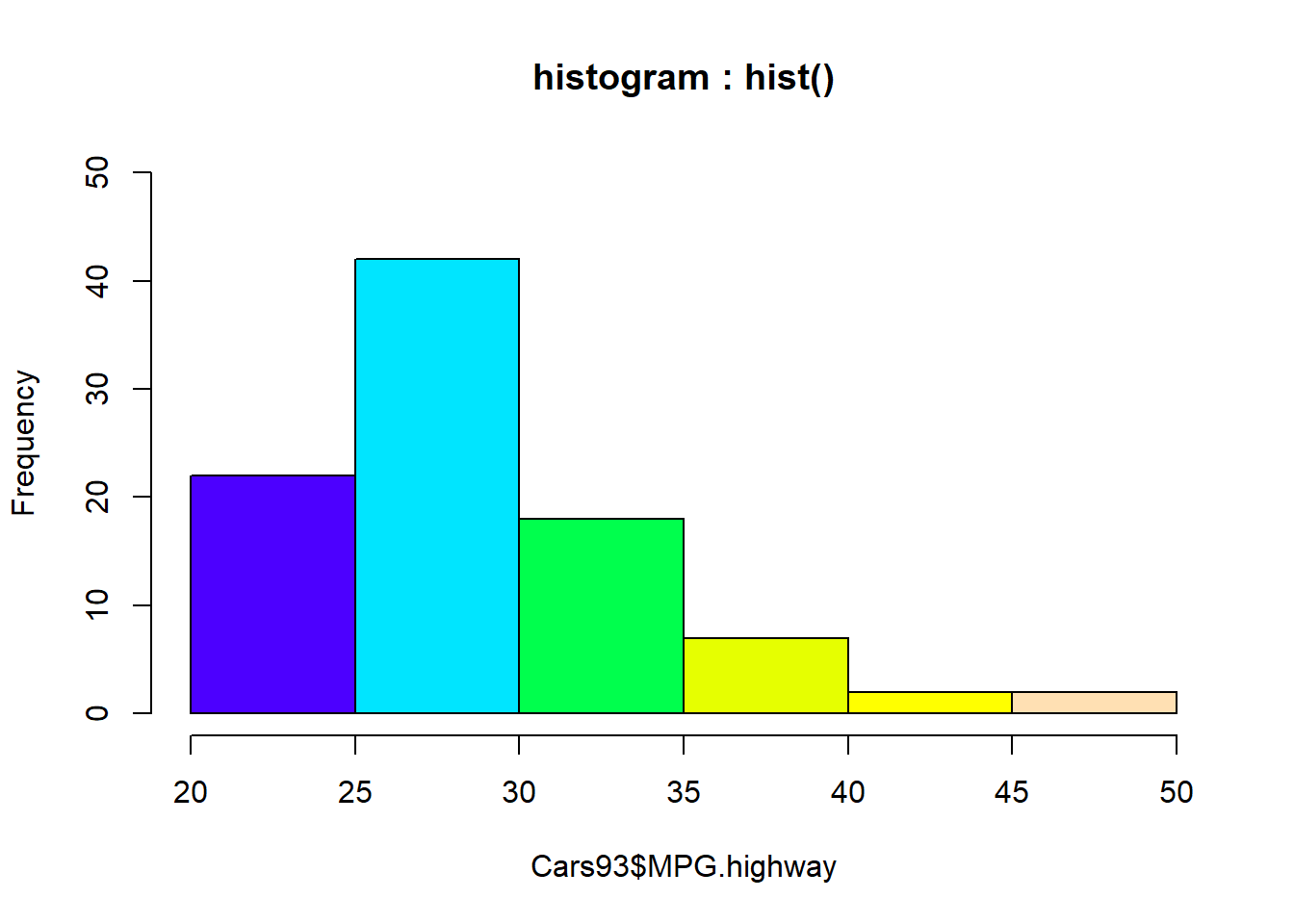
Figure 4.5: 일변량 연속형 데이터 그래프 : 히스토그램 - 색/Y축 범위 지정
cm.color(6),heat.colors(6),rainbow(6),terrain.colors(6)등의 그라디에이션 색상을 표현할 수도 있습니다.
한편 Y축을 빈도 수가 아닌 상대 빈도수(상대 도수)로 표시하기 위해서는 freq = FALSE로 설정해 줍니다.
# histogram : hist()
hist(Cars93$MPG.highway, main = "histogram : hist()",
col = topo.colors(6),
freq = FALSE) # Y축의 값이 비율로 표시가 됩니다.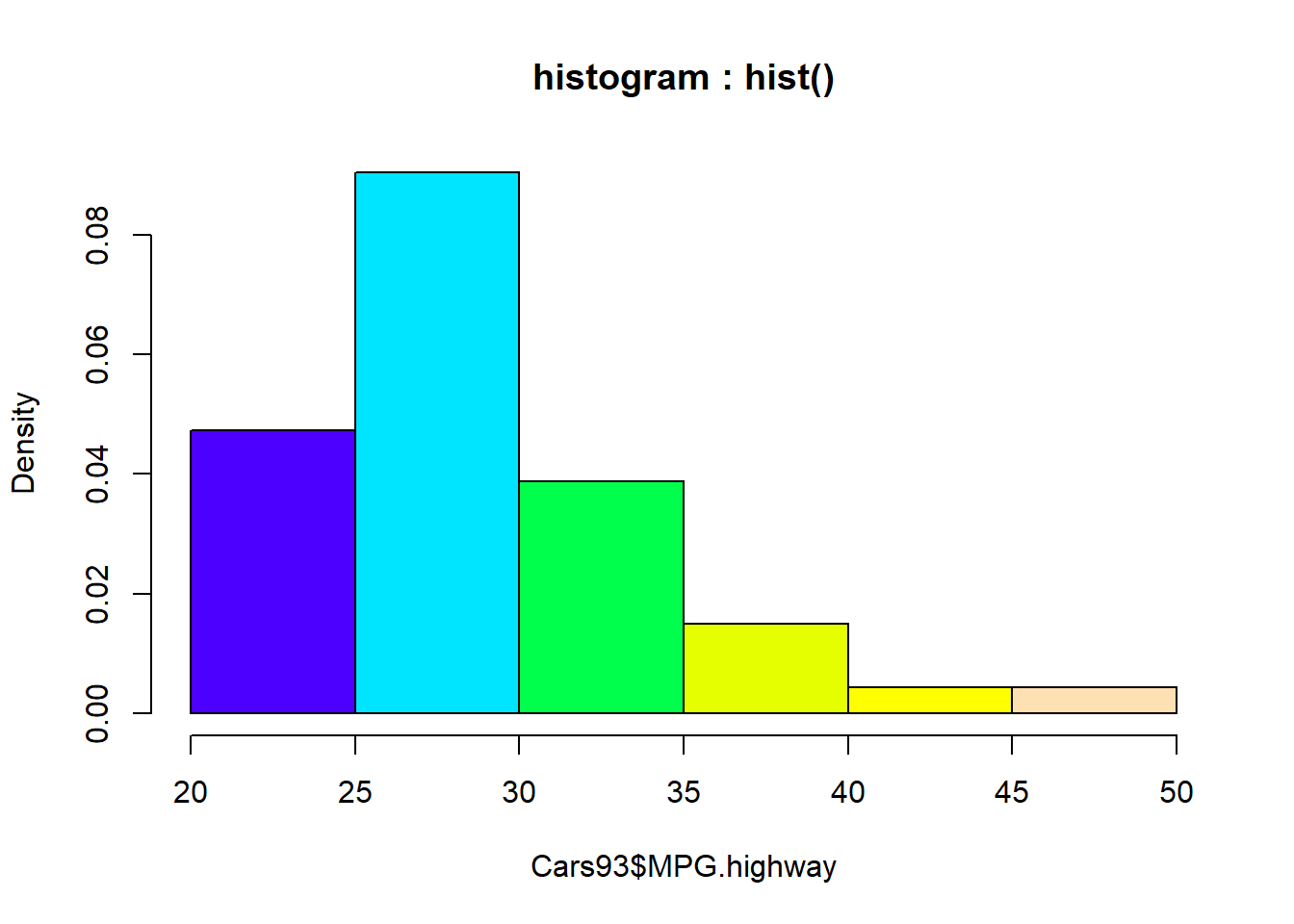
Figure 4.6: 일변량 연속형 데이터 그래프 : 히스토그램 - 상대 도수
지금 작성한 상대 도수 분포도를 이용하여 확률분포도를 나타내는 커브를 lines(density()) 함수를 이용하여 중첩하여 표시할 수 있습니다.
# histogram : hist()
hist(Cars93$MPG.highway, main = "histogram : hist()",
col = topo.colors(6),
freq = FALSE) # 밀도함수를 표시하기 위해 이 모수를 설정합니다.
lines(density(Cars93$MPG.highway)) # 히스토그램 위에 밀도함수를 표시합니다.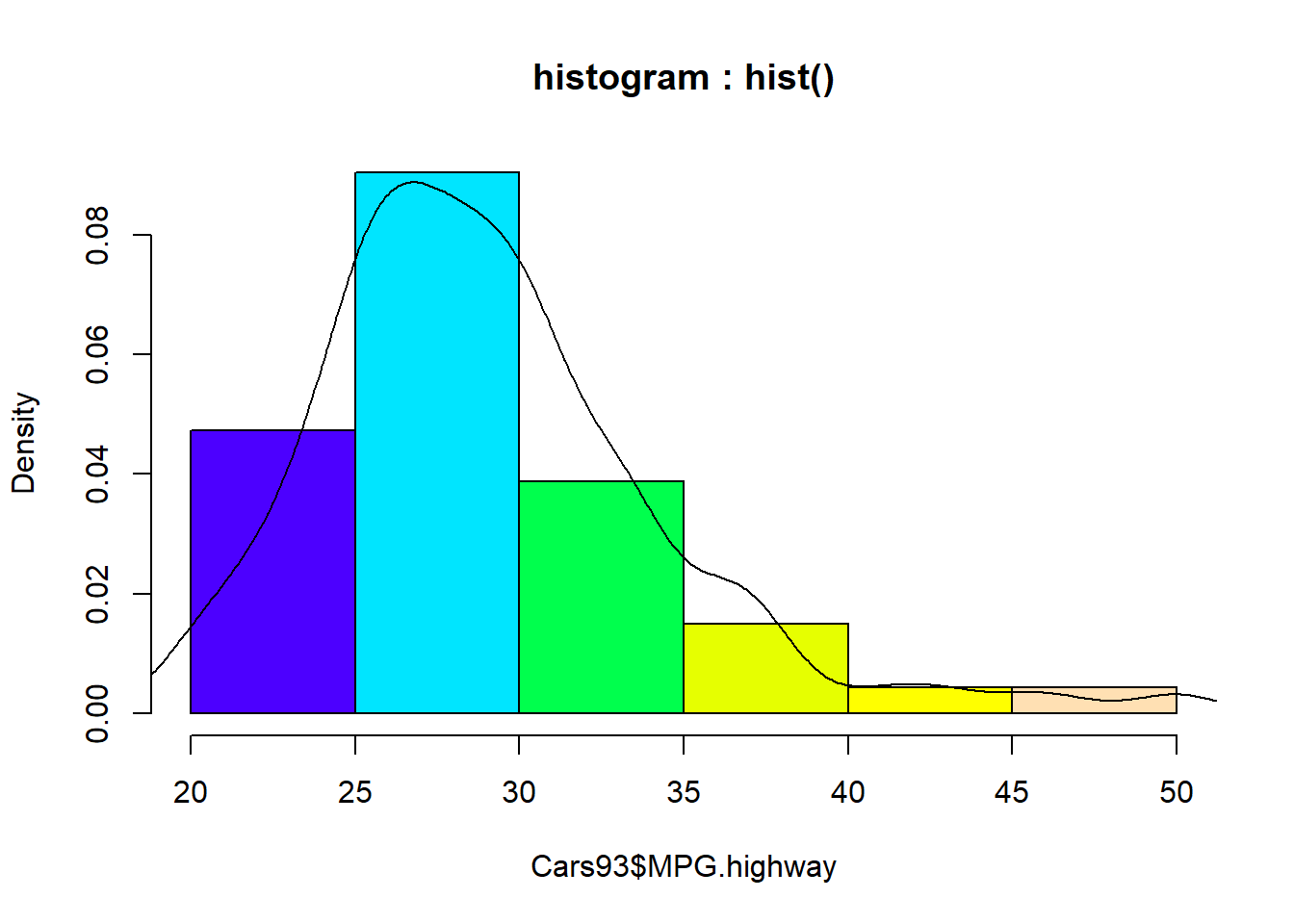
Figure 4.7: 일변량 연속형 데이터 그래프 : 히스토그램 - 밀도함수 표시
자세한 사용방법은 ? hist로 확인할 수 있습니다.
4.2.2 박스 플롯
박스 플롯(Box-and-Whiskers Plot)을 사용하는 이유는 많은 데이터를 눈으로 확인하기 어려울 때 그림을 이용해 데이터 집합의 범위와 중앙값을 빠르게 확인할 수 있는 목적으로 사용합니다. 또한 통계적으로 이상치(outlier)가 있는지도 확인이 가능합니다.
박스 플롯은 수치적 자료를 표현하는 그래프입니다. 이 그래프는 자료에서 얻은 다섯 수치 요약(five number summary)을 가지고 그립니다.
다섯 수치 요약은 아래와 같습니다.
- 최솟값 : 제 1사분위에서 1.5 IQR1을 뺀 위치입니다.
min(x) - 제1사분위(Q1) : 25%의 위치를 의미합니다.
- 제2사분위(Q2) : 50%의 위치로
중앙값(median)을 의미합니다. - 제3사분위(Q3) : 75%의 위치를 의미합니다.
- 최댓값 : 제3사분위에서 1.5 IQR을 더한 위치입니다.
max(x) - 최솟값과 최댓값을 넘어가는 위치에 있는 값을 이상치(Outlier)라고 부릅니다.
# box-and-whisker plot : boxplot()
boxplot(Cars93$MPG.highway, main = "box-and-whisker plot : boxplot()")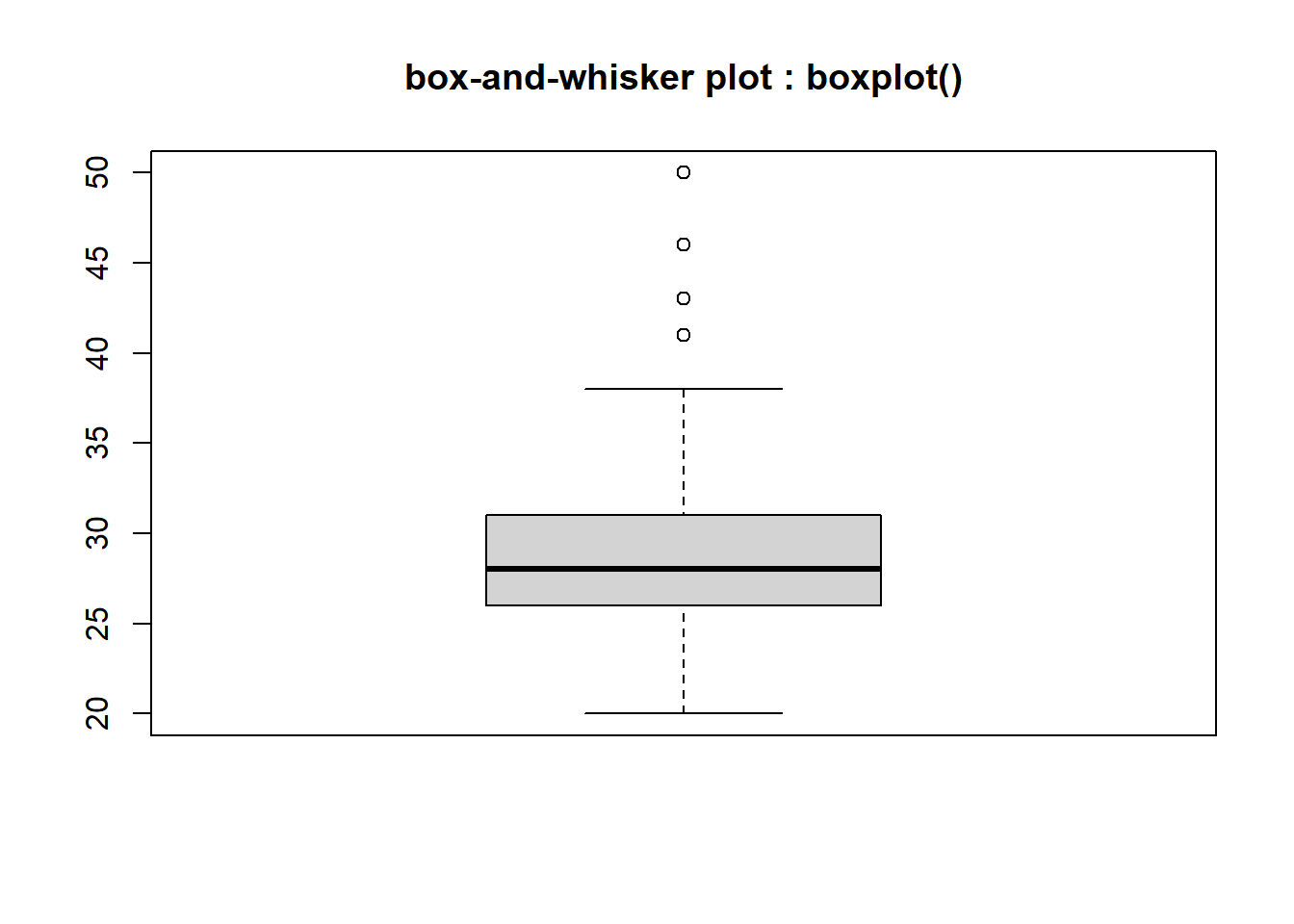
Figure 4.8: 일변량 연속형 데이터 그래프 : 박스 플롯
박스 플롯의 경우에도 xlab, ylab 등을 이용하여 축의 이름을 설정할 수 있습니다. main 모수에 그래프의 제목을 설정할 수 있습니다. 또한 color의 모수에 색깔을 지정할 수도 있습니다.
# box-and-whisker plot : boxplot()
boxplot(Cars93$MPG.highway,
xlab = "고속 도로 연비",
ylab = "빈도 수",
col = "blue",
main = "box-and-whisker plot : boxplot()")
Figure 4.9: 일변량 연속형 데이터 그래프 : 박스 플롯 - 축 제목과 색 시정
notch = TRUE 옵션을 설정해서 V 자형 박스 플롯을 그릴 수 있습니다.
# box-and-whisker plot : boxplot()
boxplot(Cars93$MPG.highway,
xlab = "고속 도로 연비",
ylab = "빈도 수",
col = "blue",
notch = TRUE, # V 자형을 박수를 표시해 줍니다.
main = "box-and-whisker plot : boxplot()")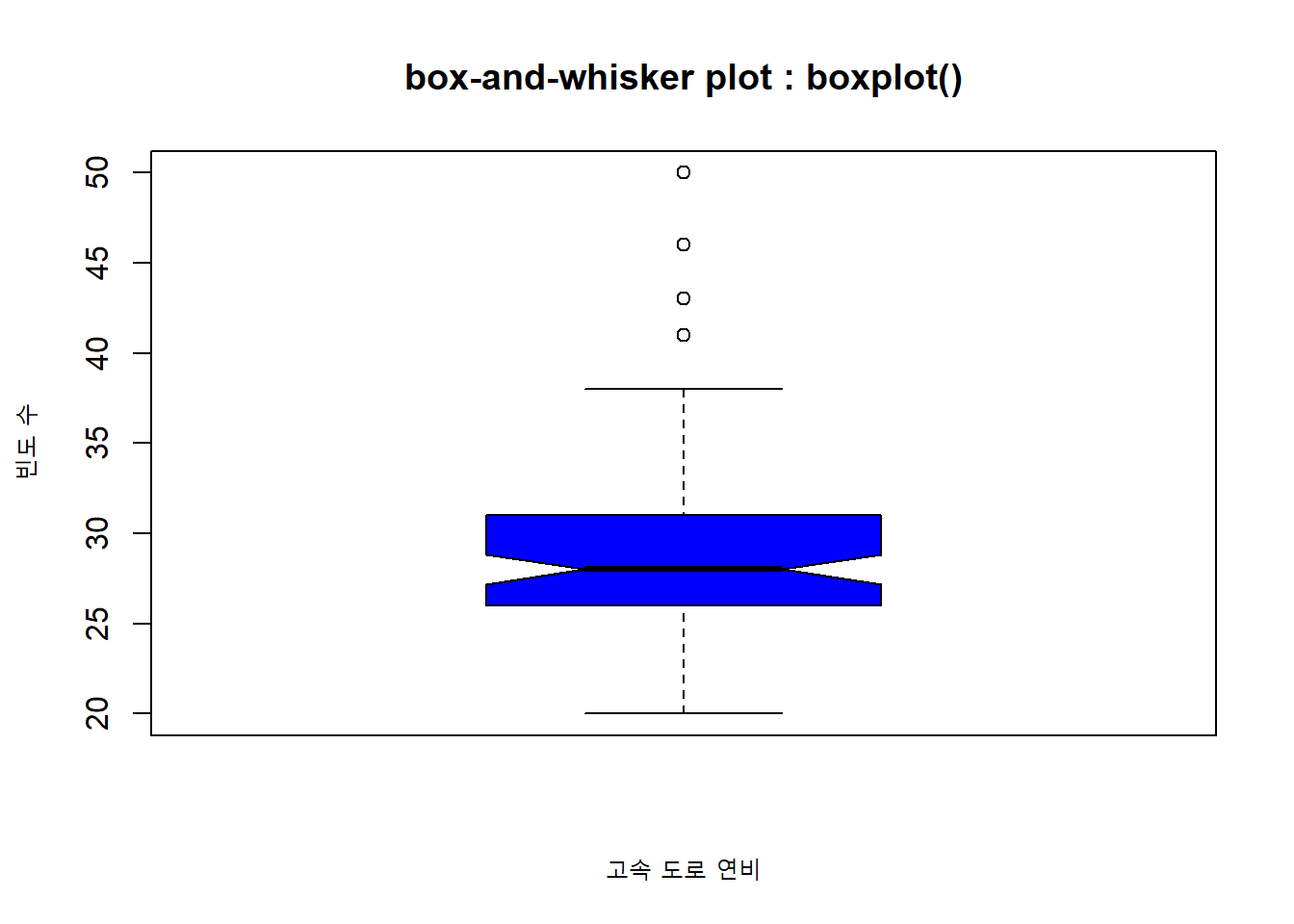
Figure 4.10: 일변량 연속형 데이터 그래프 : V 자형 박스 플롯
horizontal=TRUE 옵션을 설정해서 수평 박스 플롯을 그릴 수 있습니다.
# box-and-whisker plot : boxplot()
boxplot(Cars93$MPG.highway,
xlab = "고속 도로 연비",
ylab = "빈도 수",
col = "blue",
notch = TRUE,
horizontal = TRUE, # 박스 플롯을 수평으로 그려줍니다.
main = "box-and-whisker plot : boxplot()")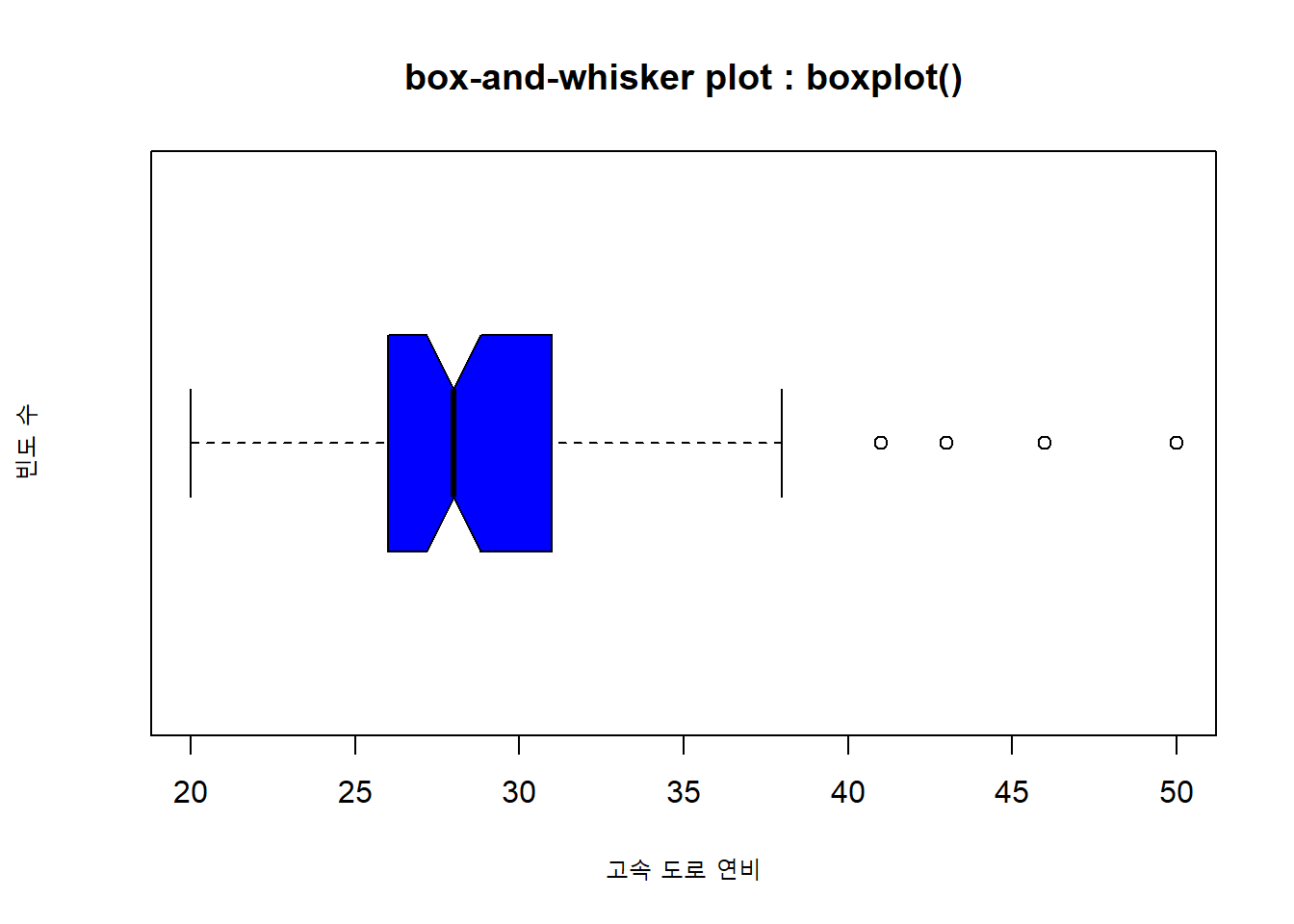
Figure 4.11: 일변량 연속형 데이터 그래프 : 수평 박스 플롯
한편, 범주형 변수인 자동차 유형(Type) 별로 박스 플롯을 그릴 수도 있습니다.
# box-and-whisker plot : boxplot()
boxplot(Cars93$MPG.highway ~ Cars93$Type, # x축: Type 변수, y축 : MPG.highway 변수
xlab = "고속 도로 연비",
ylab = "빈도 수",
col = rainbow(6), # Type 변수의 수준 갯수 만큼 색을 표시합니다.
main = "box-and-whisker plot : boxplot()")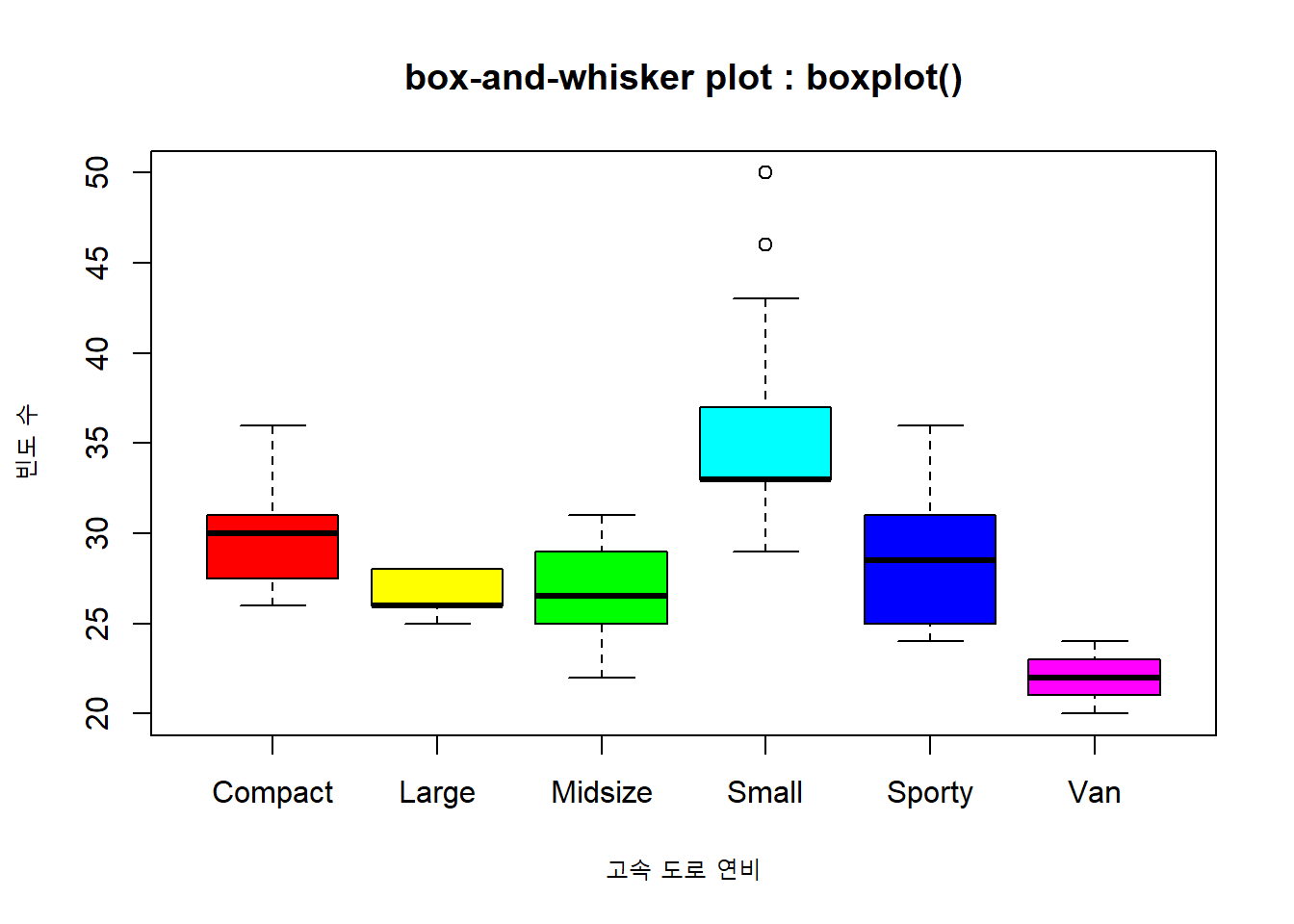
Figure 4.12: 박스 플롯 - 범주형 변수와의 결합
자세한 사용방법은 ? boxplot으로 확인할 수 있습니다.
4.2.3 줄기 잎 그래프
줄기 잎 그림(Stem-and-leaf plot 또는 stem-and-leaf display)이란 통계학에서 통계적 자료를 표 형태와 그래프 형태의 혼합된 방법으로 나타내는 것을 말합니다.
표에서의 줄기(Stem)는 자료들의 공통되는 부분을 모아놓게 되며, 잎(leaf)은 줄기 부분의 나머지 부분을 모아둡니다. 도수(Frequency 또는 Count는 한 줄기에 속하는 자료의 개수를 의미합니다.
library(MASS)
# stem and leaf plot : stem()
stem(Cars93$MPG.highway)##
## The decimal point is 1 digit(s) to the right of the |
##
## 2 | 00112233334444
## 2 | 55555555666666666667777778888888888999999
## 3 | 000000000111111123333333444
## 3 | 6667778
## 4 | 13
## 4 | 6
## 5 | 0- 위의 그림에서 최소값이 20, 최대값이 50임을 알 수 있습니다.
줄기 잎 그래프도 줄기의 갯수는 scale 모수를 이용하여 조절할 수 있습니다. 예를 들어 scale = 0.5로 하면 줄기의 갯수가 반으로 줄어듭니다. scale = 2로 하면 줄기의 갯수가 2배로 늘어납니다.
# stem and leaf plot : stem()
stem(Cars93$MPG.highway, scale = 0.5) # 줄기의 갯수를 반으로 줄입니다.##
## The decimal point is 1 digit(s) to the right of the |
##
## 2 | 0011223333444455555555666666666667777778888888888999999
## 3 | 0000000001111111233333334446667778
## 4 | 136
## 5 | 0stem(Cars93$MPG.highway, scale = 2) # 줄기의 갯수를 두 배로 늘립니다.##
## The decimal point is at the |
##
## 20 | 0000
## 22 | 000000
## 24 | 000000000000
## 26 | 00000000000000000
## 28 | 0000000000000000
## 30 | 0000000000000000
## 32 | 00000000
## 34 | 000
## 36 | 000000
## 38 | 0
## 40 | 0
## 42 | 0
## 44 |
## 46 | 0
## 48 |
## 50 | 0width 모수를 이용하여 잎의 폭을 조절할 수도 있습니다.
# stem and leaf plot : stem()
stem(Cars93$MPG.highway, width = 20)##
## The decimal point is 1 digit(s) to the right of the |
##
## 2 | 00112233
## 2 | 55555555+21
## 3 | 00000000+7
## 3 | 6667778
## 4 | 13
## 4 | 6
## 5 | 0stem(Cars93$MPG.highway, width = 40)##
## The decimal point is 1 digit(s) to the right of the |
##
## 2 | 00112233334444
## 2 | 5555555566666666666777777888+1
## 3 | 000000000111111123333333444
## 3 | 6667778
## 4 | 13
## 4 | 6
## 5 | 0stem(Cars93$MPG.highway, width = 60)##
## The decimal point is 1 digit(s) to the right of the |
##
## 2 | 00112233334444
## 2 | 55555555666666666667777778888888888999999
## 3 | 000000000111111123333333444
## 3 | 6667778
## 4 | 13
## 4 | 6
## 5 | 0자세한 사항은 ? stem으로 확인할 수 있습니다.